全球AI工厂4万亿激战!这家国产厂商领先一个身位了

作者 | 李水青
编辑 | 漠影
一场围绕Agent的全球基建竞赛,已跨越不可逆的临界点。
全球权威研究机构Omdia最新报告预测,2026年,全球科技巨头在AI基础设施上的资本支出将超过6000亿美元(约合4.07万亿元人民币),规模堪比一个世纪前的工业电气化革命。
国际AI巨头纷纷斥重资打造AI工厂。OpenAI刚刚披露,其2026年全年算力预算500亿美元,并牵头千亿级 “星际之门” 超级算力工厂;Anthropic先后与谷歌、亚马逊达成数百亿美元算力及投资合作,租赁SpaceX大型超算作为推理算力工厂,同时投入500亿美元自建数据中心集群……
当英伟达CEO黄仁勋断言“AI不是软件,而是工厂”,微软CEO纳德拉将Azure重构成“全球最大的AI工厂网络”,产业竞争的焦点已不是模型,而是能否稳定、低成本、规模化地“生产智能”。
Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。
更值得关注的是,这份报告首次系统性梳理了全球AI工厂玩家的不同路径。其中,一个来自中国的样本,被Omdia单独定义为“智能精炼(Intelligence Refiner)”范式的代表——商汤大装置。
Omdia报告截图
与此同时,IDC最新中国企业级MaaS市场报告显示,商汤大装置“万象”大模型平台凭借11.3%的市场份额,位居中国大模型平台私有化市场第二,跻身行业第一梯队。
当下正值OpenAI、Anthropic等全球AI巨头纷纷杀入企业级服务市场,竞赛的号角吹响,国产厂商如何守住阵地并向外围突破?商汤大装置凭什么被国际权威机构盖章认证为“开创者”?
智东西结合Omdia报告,并独家对话商汤大装置解决方案总经理代继,试图从产业最前线拆解:AI工厂为什么突然爆火,以及一家中国企业如何提前卡位这场新基础设施竞赛。
一、AI工厂爆火:从训练模型到生产智能,“精炼师”登场
AI工厂为什么会在今年突然爆火?
代继给出的答案很直接:因为Agent真正逼近了产业爆发临界点,AI产业的水位变了。
过去两年,行业更关注模型训练,重点始终是“大模型能力够不够强”,刷榜快不快;如今随着Agent加速落地,越来越多企业开始发现,真正消耗海量资源的其实是推理阶段。训练可能只发生一次,但推理会长期持续发生。未来80%以上的算力消耗,都可能来自推理与Agent运行。
这意味着,AI产业开始从一次性研发逻辑,转向持续性的工业化运营逻辑。企业开始关心新的问题:模型已经足够聪明,如何把它变成稳定、可控、可规模化的AI生产系统?
这也正是AI工厂概念迅速升温的核心原因。
根据Omdia报告的定义,传统数据中心,本质上是在提供服务器、存储与网络资源;AIDC(智算中心)则主要提供GPU算力;而AI工厂输出的,已经不再只是“计算资源”,而是企业级AI能力、智能体与Token生产能力。
而一旦进入AI工业化运营逻辑,企业开始关心的不再只是模型性能参数,而是:单位Token成本到底是多少?GPU利用率能不能持续提升?多种国产芯片能否混合运行?推理与训练能否动态调度?电力成本是否还能压缩?Agent失控时如何保障业务安全?等等。
这些问题,本质上都是基础设施问题。
Omdia在报告中明确指出,AI工厂已经不是传统数据中心的升级版,而是一种“以生产智能为目标的新型工业基础设施”。
全球科技产业的重心,也开始集体向这里迁移。
一边是海外巨头全面加码。英伟达、微软、亚马逊、谷歌持续扩张AI基础设施;另一边,中国市场也正在进入AI工厂建设高峰期。特别是在金融、政务、能源、制造等行业,越来越多企业开始推进私有化AI工厂建设。
全球AI工厂市场随之演变出了不同类型的核心参与者:有卖“盒子”的一站式私有AI底座商,有卖端到端服务的全栈公有云巨头,有卖极致性能的算力原生AI云,也有卖本地化服务的区域运营商。竞争的焦点在于,谁能把Token的价值密度做得更高,谁就有望占据优势生态位。

全球AI工厂市场演变出了四类核心玩家群体
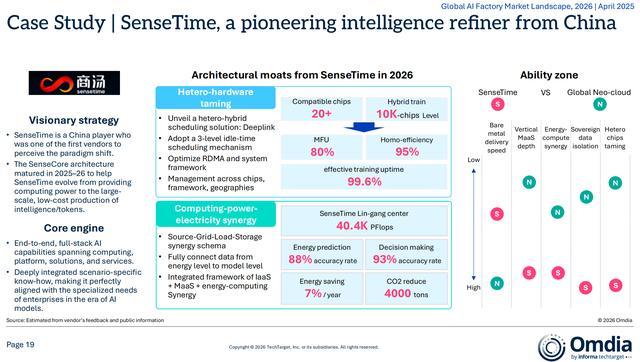
在激烈的角逐中,Omdia之所以将商汤大装置推举为“智能精炼范式”的开创者,核心在于其率先完成了从“算力生产能源公司”向“企业级智能制造工厂”的进化 。
所谓“智能精炼”,本质上是通过一套围绕模型生产和智能输出构建的完整系统工程,形成“智能生产线” 的运行模式,把原始算力、推理服务、数据处理、模型测评、算力调度等融合,最终实现更高效的Token生产。代继告诉智东西,商汤大装置是在这一领域最早布局的代表玩家之一。

商汤临港智算中心
二、为什么是商汤大装置?五层架构,把算力数据炼成生产力
事实上,商汤布局AI工厂,并不是今年才开始。
早在2022年,行业还在讨论“大模型到底有没有商业价值”时,商汤内部就已经提出“AI数字工厂”构想。
过去几年,商汤大装置逐渐形成了一套完整的“五层架构”。而这套架构,本质上也是围绕AI工厂落地过程中最棘手的问题逐层展开。

商汤大装置AI工厂架构
1、能源与物理层:联手“宁王”,先解决“电老虎”痛点
AI工厂首先面对的,是能源问题。
AI时代的数据中心,耗电量远超传统IDC。尤其在推理规模持续爆发之后,电力已经开始成为AI工厂最核心的运营成本之一。因此,AI工厂的竞争,首先是能源的竞争。
为此,商汤大装置与宁德时代合作,在临港AIDC落地算电协同平台:其核心目标是通过电力预测、储能调度与负载优化,让整个AI工厂运行效率最大化。
Omdia数据显示,该系统能源预测准确率达到88%,决策准确率达到93%,PUE降至1.265,年节约电费约7%,碳减排每万P 4000吨。
在AI进入高耗能时代后,“电”已经不再是辅助资源,而是AI工厂核心生产资料的一部分。
2、异构算力层:真正难啃的,是国产芯片碎片化
如果说能源是AI工厂的血液,那么异构芯片协同,就是最难打通的神经系统。
代继向智东西坦言,五层架构里最难的一层,就是异构算力层。原因很简单:国产芯片生态高度碎片化。每一家国产AI芯片或GPU厂商,几乎都是一个“黑盒”。不同芯片拥有不同通信协议、不同调度方式、不同硬件架构,很难通过统一方法实现协同。
而现实情况是,很多大型企业内部,本身就已经采购了多个品牌AI芯片。“每个客户基本都会有一点。”代继说,“你必须帮他把这些东西真正协同起来。”
据了解,商汤大装置率先实现了万卡级国产GPU集群异构混训。Omdia数据显示,其异构训练效率已达到同构训练95%的水平。这意味着,客户无需再过多关注不同芯片之间的适配与调度问题,商汤在底层就把这些碎片化问题解决了。
而这背后,是长期底层优化积累。代继透露,很多国产AI芯片优化,往往需要针对具体超级节点、交换机结构、通信协议逐层写代码调优。不是把任务拉起来跑就行,而是你得知道每一层瓶颈在哪里,不断调到最优值。
这种能力,很难通过短期堆资源获得。
3、调度平台层:AI工厂最大的浪费,是GPU闲着
AI工厂需要同时服务训练和推理两种截然不同的工作负载,需要“训推共池”。
过去很多训练集群,一旦训练结束,大量GPU会出现空转;推理系统则可能在高峰期爆满、低谷期闲置。如何在同一资源池中实现两者的高效共存,避免资源浪费同时保障SLA,是全行业的共同难题。
为此,商汤大装置通过自研训练框架,开发并优化多种并行策略,提升训练性能和显存管理,另外,支持开源vLLM及自研LightLLM双推理引擎,极大提升推理效率并压低推理成本。
本质上,AI工厂已经越来越像现代工业流水线。对于金融、政务等对稳定性要求极高的客户而言,这一层直接决定了AI能力能否进入核心生产环节。
4、MaaS层:模型正在变成开放部署的“工业零部件”
在模型层,行业也发生了明显变化。
过去,大模型公司普遍希望通过闭源模型建立壁垒;但随着开源模型快速成熟,行业开始意识到模型本身,正在逐渐变成标准化能力。
商汤大装置的MaaS层,不是单纯提供自研模型,而是整合“日日新”与大量第三方开源模型,形成统一调用平台,提供模型部署、模型推理、Agent开发能力等。
企业面对琳琅满目的开源模型和商业模型,往往不知道如何选择、如何调优、如何部署模型,商汤的MaaS层整合了“日日新”大模型及第三方开源模型,提供一站式模型服务,让企业可以从海量选项中抽身,聚焦于自身业务逻辑。
模型,正在从“明星产品”变成开放选项的“工业零部件”。
5、产业应用层:真正有价值的,是场景化Token
而五层架构里,最接近业务价值的一层是应用层,也是客户获得感最强的层面。
代继认为,企业真正需要的不是“通用Token”,而是“场景化Token”。也就是说,这个Token必须具备行业理解能力,结合了结合AIGC、具身智能、AI4S等场景的高浓度产业知识,从而成为真正理解业务流程、专业知识与安全边界的智能系统。
商汤过去十几年积累的大量产业经验,也开始在这一层形成复利。
例如,其与铁一院打造铁路设计首个多模态大模型,贯通28个专业知识,测试准确率超90%;与上海市规划资源局共建6000亿参数的“云宇星空”大模型,构建“1+6”模型体系,精准支撑复杂的城市空间治理。
“云宇星空”大模型应用界面
代继告诉智东西,相比纯SaaS层的后来者,商汤大装置拥有更深的物理层控制力,它是智能的“原始生产商”,交付成本更低、稳定性更强。而相比传统云厂商,商汤大装置又是AI原生的,没有历史包袱。
三、OpenAI、Anthropic刚下场,中国厂商已提前卡位“场景化Token”
近期,Anthropic与黑石成立AI原生企业服务公司,OpenAI也设立新公司杀入企业级部署。当模型巨头们纷纷从线上走向线下,商汤大装置的护城河在哪里?
代继告诉智东西,核心还在于“场景化Token”。
他谈道,企业级AI与消费级AI有较大区别。制造、能源、交通、城市治理等传统行业客户往往缺少AI技术团队,或技术人才储备不足,难以直接把GPU和模型转化为生产力。从基础设施到业务价值之间,存在一条极长的落地鸿沟。而真正决定企业AI成败的,往往是行业Know-How、部署能力与场景理解。
这也是为什么,OpenAI和Anthropic开始大量招聘行业专家,并向FDE(前沿部署工程师)模式靠拢。但当这些巨头刚刚开始敲门,商汤大装置早已提前在门内布局。
过去十几年,商汤在智慧城市、医疗、交通、具身智能、AIGC等领域积累的大量行业知识,被重新萃取、嵌入模型与服务体系之中。最终,客户调用的已经不是一个“裸模型”,而是一套具备场景理解能力的智能能力。
这也正切中当前企业市场最核心的变化。国内各行业客户的核心诉求尤为鲜明:强调全掌控、私有化、可控、安全、深度参与。
代继透露,目前国内增长最快的,仍然是私有化AI工厂。因为企业并不希望AI成为一个无法掌控的黑盒。“如果你用这套系统驱动核心业务,一旦失控,整个产线都可能挂掉。”他说。
因此,未来企业AI大概率不会是完全自主Agent,而会是“Agent + Workflow”的混合架构。
在企业服务商业模式的探索上,美国数据巨头Palantir依靠FDE(前沿部署工程师)模式斩获的高速增长震动了业界。代继坦言,商汤大装置目前的进化逻辑与Palantir不谋而合,正重点推动FDE深度赋能模式,集中重兵突破头部的Key Account(大客户)。
这也从行业角度,解释了为什么AI工厂最终会越来越像工业系统,而非互联网产品。
从金融行业的碎片化算力整合,到与上海市规划资源局共建的6000亿参数的政务大模型,再到企业核心业务中的可控Agent体系,商汤大装置正在通过一次次高复杂度项目,把自己的“原生AI云 + 深刻场景理解”融入AI工厂,修筑起一道难以逾越的护城河。
结语:2030年的AI赢家,属于今天的“智能精炼师”
Omdia预测,到2030年,全球数据中心市场累计投资将接近1.6万亿美元。资本正从“买算力”转向“建工厂”,这场竞赛的终局,将是能源、算力、算法、场景与服务的系统性角力。
OpenAI与Anthropic的入场,印证了企业级AI市场的巨大引力。而商汤大装置凭借其前瞻布局的“AI数字工厂”五层架构,包括硬核的算电协同与异构混训能力,以及深入产业肌理的“智能精炼”范式,已在这场全球性的基础设施重构中,率先卡住了生态位。
正如黄仁勋所言,AI模型可以复制,但AI工厂不能。那些率先成为“智能精炼师”的先行者,有望定义下一个时代的产业格局。
(来源:新浪科技)

