北大拿下2篇最佳论文,DeepSeek实习生立功,华人横扫这场AI顶会

作者 | 陈骏达
编辑 | 李水青
智东西7月31日报道,昨天,第63届计算语言学协会年会(ACL 2025)在奥地利召开。作为自然语言处理领域最具学术影响力的会议之一,本届ACL吸引了超过8300多篇论文的投稿,中国大陆科研人员在本届ACL实现明显突破。
最佳论文奖是ACL最受关注的奖项,今年ACL共评选出4篇最佳论文,其中2篇来自中国大陆,分别由北大、DeepSeek和华盛顿大学联合团队,以及北大-灵初智能联合实验室摘得。
DeepSeek等机构的获奖论文以原生稀疏注意力(NSA)为主题,第一作者为袁境阳。袁境阳在DeepSeek实习期间提出了NSA模型,现在在北京大学计算机学院攻读博士学位。DeepSeek创始人兼CEO梁文锋也出现在作者名单中。
NSA可用于超快速的长上下文训练与推理,以性价比极高的方式,罕见地在训练阶段应用稀疏性,在训推场景中均实现速度的明显提升,特别是在解码阶段实现了高达11.6倍的提升。

论文链接:https://aclanthology.org/2025.acl-long.1126/
北大-灵初智能联合实验室首席科学家杨耀东博士团队的获奖论文,则揭示了大模型参数结构中存在的一种弹性机制,并可能导致模型在后训练阶段产生抗拒对齐的行为。这一发现对AI治理和安全问题很有启发意义。

论文链接:https://aclanthology.org/2025.acl-long.1141/
其余2篇最佳论文来自美国、德国。斯坦福大学、康奈尔大学(科技校区)联合团队在获奖论文中提供了一套评估算法公平性的基准测试,并发现现有促进算法公平性的手段存在误区,如果盲目使用可能会适得其反。

论文链接:https://aclanthology.org/2025.acl-long.341.pdf
由德国CISPA亥姆霍兹信息安全中心、TCS Research以及微软三家机构合作的获奖论文,则聚焦于大型语言模型在自主决策中的采样偏差——揭示其背后由“描述性常态”与“规定性理想”共同塑造的启发式机制,并通过公共卫生与经济趋势等现实案例,论证这种向理想值偏移的现象如何在实际应用中导致显著偏差与伦理风险。

论文链接:https://aclanthology.org/2025.acl-long.1454/
ACL官方数据显示,2025年,所有投稿论文中的第一作者中,有51.3%来自中国大陆,与去年30.6%的比例实现了明显增长;今年所有作者中,中国大陆作者的比例也达到51%。过去两年,美国在第一作者数量上均位居第二,不过比例已经从2024年的29.6%下降至2025年的14.0%。
以下是本届ACL中两篇来自中国大陆的最佳论文的核心内容梳理:
一、DeepSeek联手北大:新型稀疏注意力机制,让模型解码狂飙11.6倍
北京大学、DeepSeek和华盛顿大学联合团队(后简称联合团队)的获奖论文全名为《原生稀疏注意力:面向硬件对齐且可原生训练的稀疏注意力机制(Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention)》,曾于今年2月份作为DeepSeek-R1开源的系列技术报告之一发布。
什么是稀疏注意力?与传统注意力机制相比,稀疏注意力方法能通过选择性计算关键的查询键对来减少计算开销。不过,现有许多稀疏注意力方法在实际推理中未能显著降低延迟,还无法适应现代高效的解码架构,也缺乏对训练阶段的支持。
联合团队希望解决现有稀疏注意力的两大问题,一是事后稀疏化导致的性能退化,二是现有稀疏方法在长序列训练的效率短板。
NSA的核心思想是通过动态分层稀疏策略,结合粗粒度的token压缩和细粒度的token选择,保留全局上下文感知能力和局部精确性。
在NSA机制中,模型会同时使用三种不同的注意力方式来处理输入文本,每种方式都有它自己的擅长领域:
(1)压缩注意力
这个分支把输入的信息聚合成块,捕捉粗粒度的语义信息,也就是对输入内容的关键信息进行总结提炼。压缩注意力可以减少计算的工作量,但会损失细节。
(2)选择性注意力
为了避免压缩时遗漏重要内容,NSA新增了选择性注意力机制。这一机制给每一块信息打个“重要程度”的分数,并选择最关键的信息进行更细致的计算。这样既能保留关键细节,又不会让计算变得太复杂。
(3)滑动窗口注意力
这个分支负责处理文本中临近的词之间的关系。它会在固定大小的窗口内计算注意力,比如只看当前词前后的几个词,这样可以更好地理解局部上下文。这个机制能防止模型太过依赖前两个机制,而忽视邻近词之间的联系。
整体来看,NSA通过这三种注意力机制互相配合,一方面节省计算资源,一方面又能兼顾全局语义和关键细节。
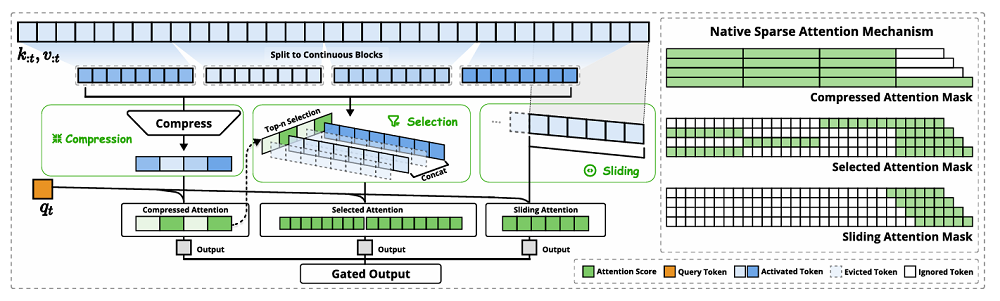
▲NSA架构概览
为测试NSA机制的实际效果,联合团队在同一模型的基础上,分别使用了不同的注意力机制,比如传统的全注意力机制、NSA机制等,并在多个测试任务上进行比较。
使用NSA机制的模型在9个测试中获得了7项最佳成绩,整体表现超过了其它所有方法,包括全注意力。尤其是在逻辑推理、问答等任务上,采用NSA机制的模型表现较好,这说明它能排除掉不重要的信息,把注意力集中在真正关键的部分。
除了质量方面的提升,NSA还带来效率方面的优势。联合团队在8张A100显卡上做了测试,他们发现:
(1)在64k长度的文本输入下,NSA的前向计算速度是全注意力的9倍;
(2)反向计算速度是全注意力的6倍;
(3)在解码时,NSA将速度提升至原有的11.6倍。
这些提速的关键在于NSA对硬件更友好,比如,其内存访问是按“块”来走的,最大化了张量核心的利用率,而且内部调度机制减少了不必要的计算负担。
二、北大-灵初智能团队:探索模型对齐困境,“弹性”机制或成开源模型隐忧
北大-灵初智能联合实验室首席科学家杨耀东博士团队(后简称该团队)的获奖论文全名为《语言模型抗拒对齐:来自数据压缩的证据(Language Models Resist Alignment: Evidence From Data Compression)》。这一研究揭示了一个关键问题:大语言模型在对齐时其实会反抗。
该团队发现,尽管我们可以通过各类对齐方式让模型变得更“安全”、更“符合人类价值观”,模型本身其实倾向于回到它原来预训练时学到的原始分布。就像一个弹簧被拉伸后又想回到原始状态,这种行为被称为“弹性”。
这种弹性体现在两个方面:
(1)抵抗(Resistance):模型不太愿意改变自己,仍然保留原来的分布特征;
(2)反弹(Rebound):对模型对齐越深,它反弹回原始状态的速度反而越快——如果用反方向训练(比如取消之前的对齐过程),它很快就会打回原形。
研究还发现,这种行为可以用压缩率变化来衡量——也就是说,模型对不同数据集的学习压缩程度变化,与数据量大小成反比。
为了进一步解释这种行为,该团队构建了一个理论模型:语言模型训练和对齐过程其实是一种信息压缩过程。他们基于“压缩定理”(compression theorem)和“压缩协议”(compression protocol),从信息论的角度来分析模型为什么会产生“弹性”——这为理解为什么对齐不稳定提供了数学框架。
最后,该团队通过一系列实验,验证了这一现象在不同的大模型中都存在。这说明“弹性”并不是个别模型的特例,而是语言模型训练过程中一种普遍的内在机制。
因此,要想实现真正稳固的对齐,不能只停留在表层的微调,而必须深入理解并对抗这种由压缩机制引发的反对齐倾向。
该团队还基于模型弹性机制,提出了对开源策略的思考。
一方面,开源模型权重有助于研究者快速发现漏洞、推动大规模对齐与安全研究;另一方面,模型弹性也意味着,即便是通过审计和安全微调的模型,如果被公开,一旦出现更先进的反对齐手段,这些模型也可能很容易被重置到未对齐状态,大大降低模型“越狱”的门槛,破坏原有的安全机制,带来现实风险。
结语:华人AI研究者集体崛起,安全成为ACL热点议题
除了中国大陆团队在最佳论文奖上的杰出表现,ACL 2025还见证了华人AI研究者的集体崛起。
本届ACL评选出26篇杰出论文,这是重要性仅次于最佳论文的奖项。这26篇论文中,有13篇论文的第一作者为华人,占比达50%。这也显示出,华人AI研究者在全球范围内的学术影响力,正不断扩大。
值得一提是,ACL的获奖论文中,有大量以AI安全、监督、对齐等为主题,学术界对这些重要议题的关注,给产业界的AI研究提供了极为有益的补充。
(来源:新浪科技)
