MiniMax深夜开源!首个推理模型,4560亿参数、百万上下文、价格低至0.8元
作者 | 程茜
编辑 | 心缘
智东西6月17日报道,今日凌晨,“大模型六小虎”之一MiniMax发布全球首个开源大规模混合架构的推理模型MiniMax-M1,并官宣了为期五天的连更计划。
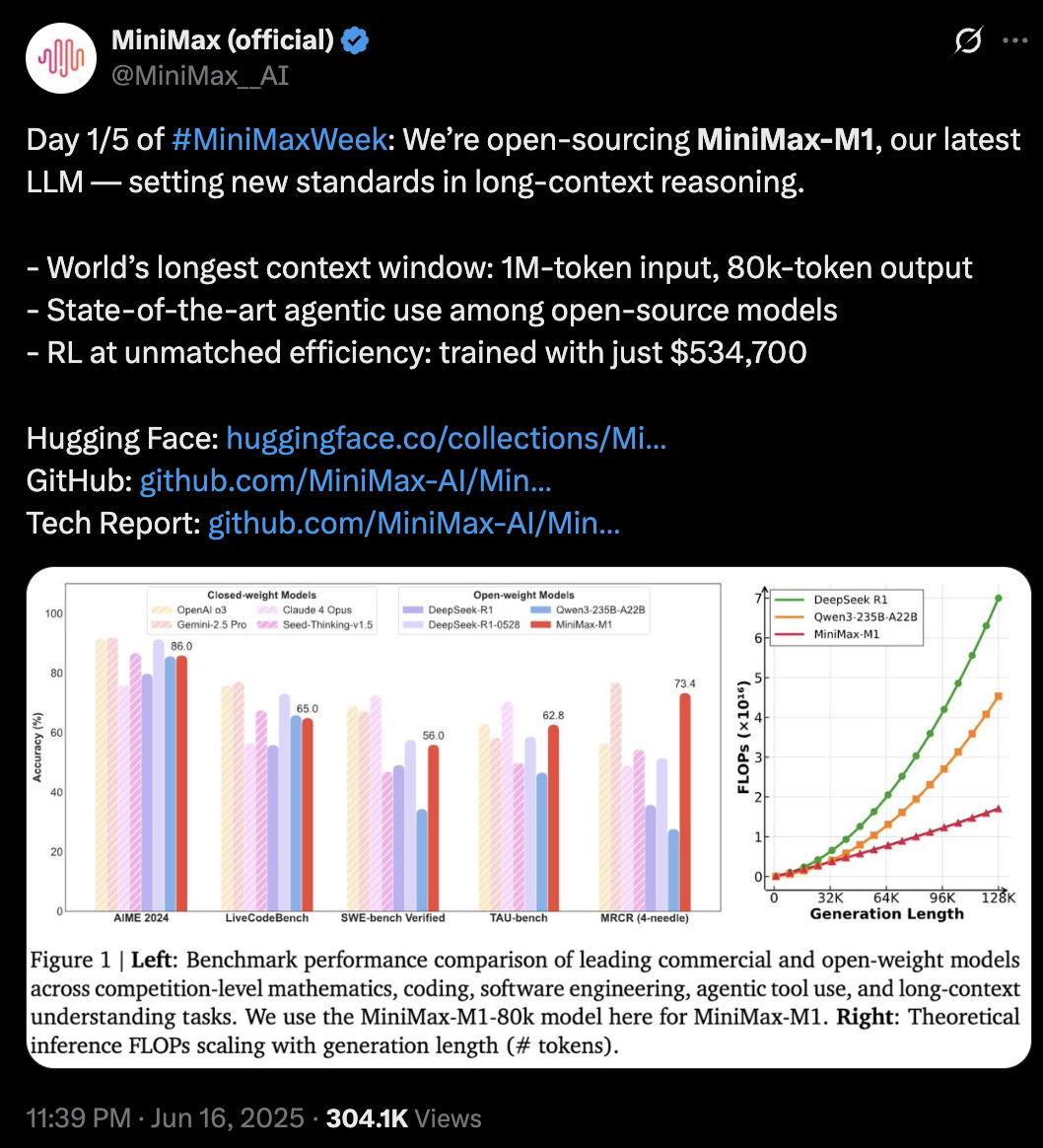
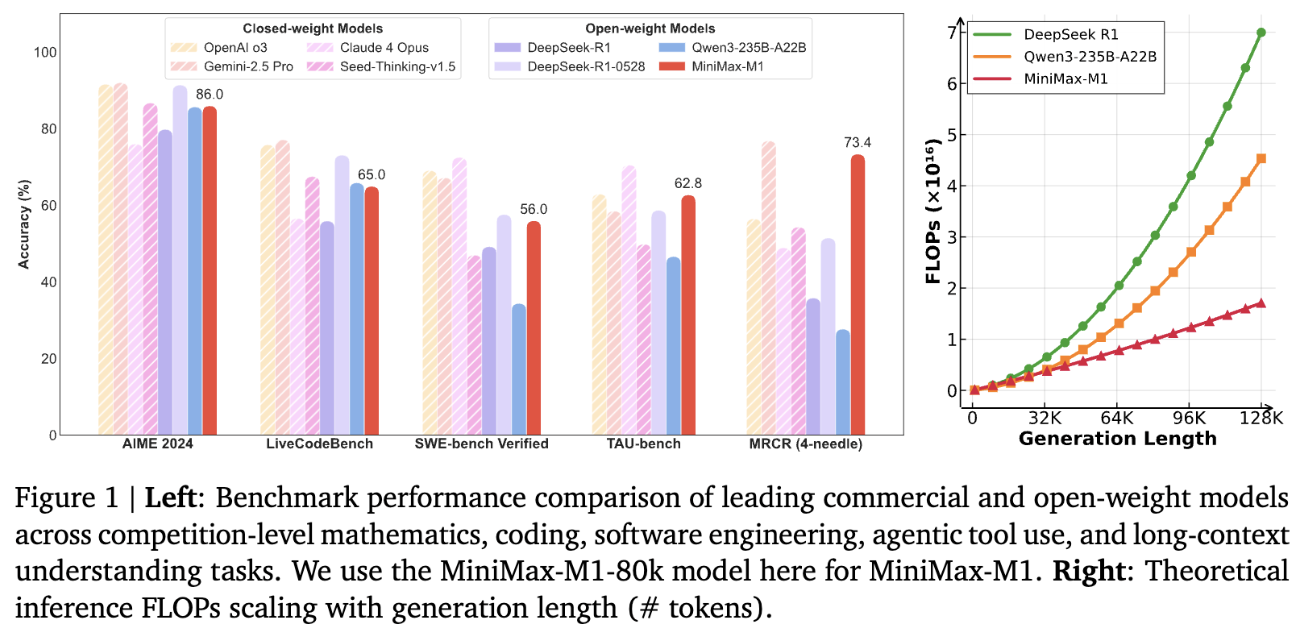
M1参数规模为4560亿,每个token激活459亿参数,原生支持100万上下文输入以及业内最长的8万token推理输出,输入长度与闭源模型谷歌Gemini 2.5 Pro一致,是DeepSeek-R1的8倍。此外,研究人员训练了两个版本的MiniMax-M1模型,其思考预算分别为40K和80K。
MiniMax在标准基准测试集上的对比显示,在复杂的软件工程、工具使用和长上下文任务方面,MiniMax-M1优于DeepSeek-R1和Qwen3-235B等开源模型。
其博客提到,在M1的整个强化学习阶段,研究人员使用512块H800训练了三周,租赁成本为53.74万美金(折合人民币约385.9万元),相比其一开始的成本预期少了一个数量级。
M1在MiniMax APP和Web上支持不限量免费使用。API价格方面,第一档0-32k的输入长度时,输入0.8元/百万token, 输出8元/百万token;第二档32k-128k的输入长度时,输入1.2元/百万token, 输出16元/百万token;第三档128k-1M输入长度时,输入2.4元/百万token, 输出24元/百万token。
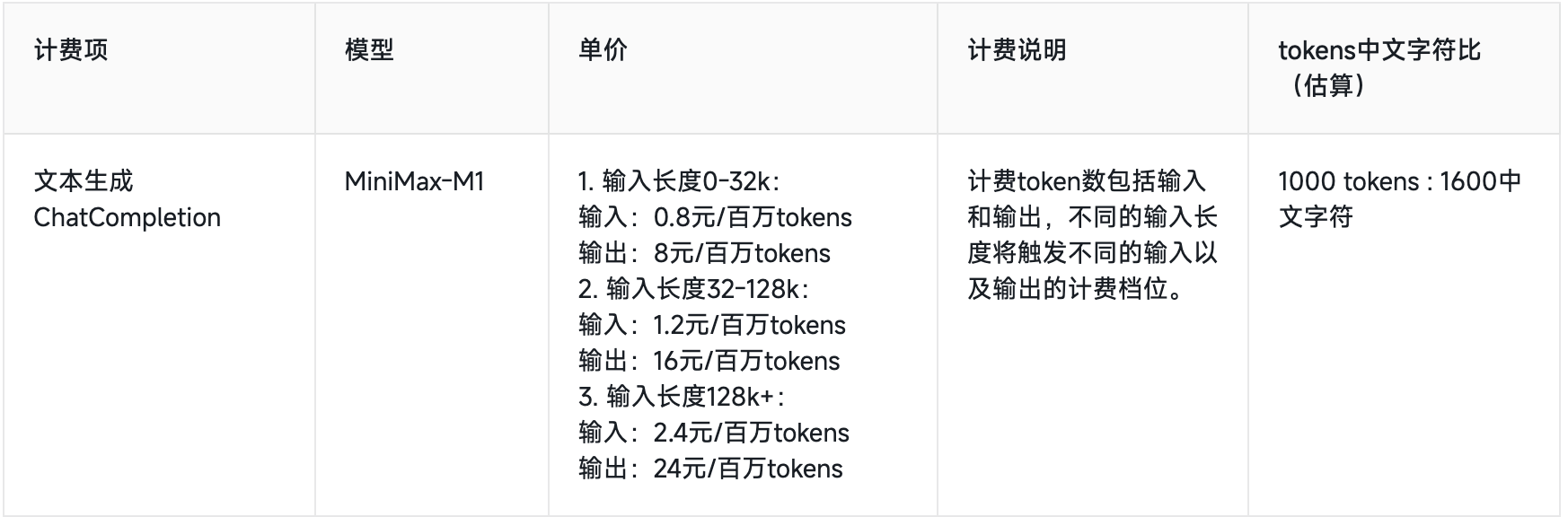
DeepSeek-R1输入长度是64k,输出默认32k最大64k,因此可以对标M1第一档和第二档价格。不过,M1第一档、第二档价格相比DeepSeek-R1优惠时段都没有优势。
在标准时段,M1第一档输入价格是DeepSeek-R1的80%、输出价格为50%;第二档输入价格是DeepSeek-R1的1.2倍、输出价格相同。
第三档是M1的绝对优势区,DeepSeek-R1不支持128k-1M的输入长度。
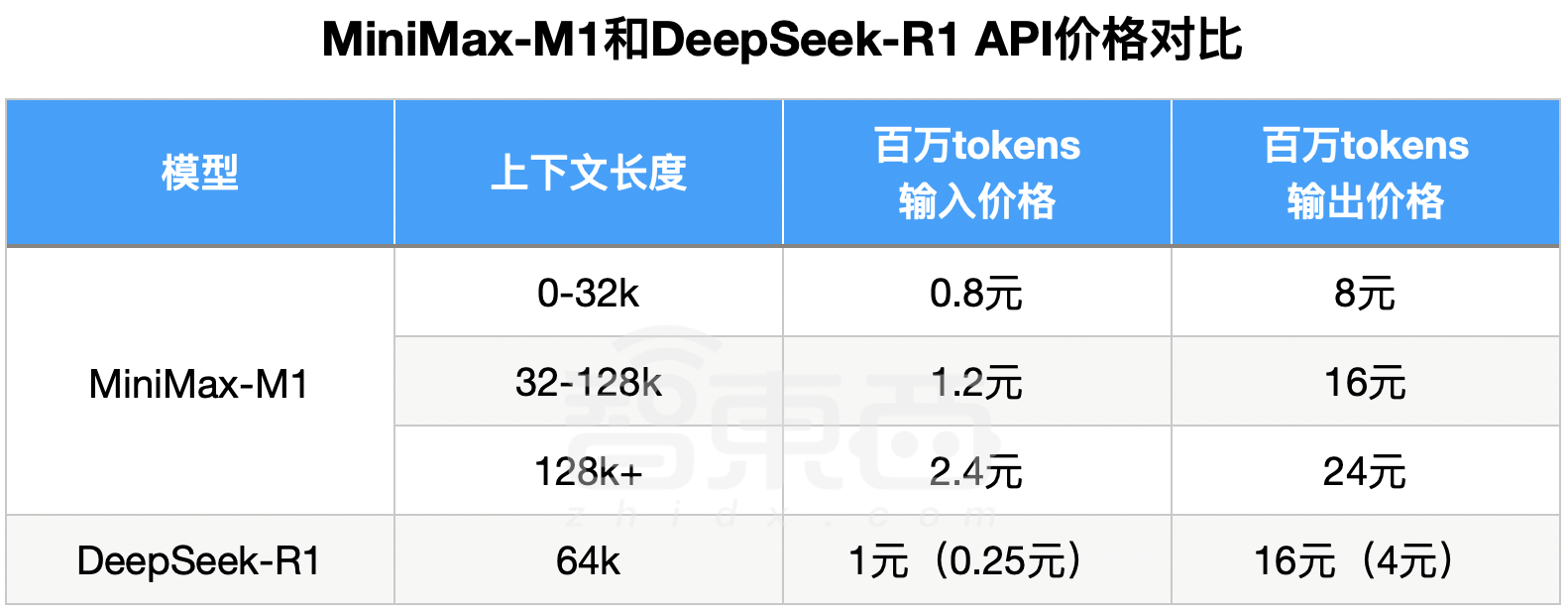
▲MiniMax-M1和DeepSeek-R1 API价格对比
几乎与MiniMax同时,“大模型六小虎”另外一家月之暗面,也发了开源代码模型Kimi-Dev,编程能力强过DeepSeek-R1。
体验地址:https://chat.minimax.io/
GitHub地址:https://github.com/MiniMax-AI/MiniMax-M1
Hugging Face地址:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
技术报告地址:https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
一、Agent工具使用能力一骑绝尘,数学、编程略逊
基于业内主流17个评测集,MiniMax-M1的评测结果在软件工程、长上下文、工具使用等方面的表现优于其他开源或闭源模型。
OpenAI发布的MRCR测试集中,M1的表现略逊于Gemini 2.5 Pro,相比其他模型效果更好。MRCR评估的是大语言模型区分隐藏在长上下文中多个目标的能力,要求模型在极其复杂且多重干扰的长文本中,准确区分多条几乎相同的信息,还需识别其顺序。
在评估软件工程能力的测试集SWE-bench Verified中,MiniMax-M1-40k和MiniMax-M1-80k的表现略逊于DeepSeek-R1-0528,优于其他开源模型。
Agent工具使用方面,在航空业的测试集TAU-bench(airline)中,MiniMax-M1-40k表现优于其余的开源和闭源模型,零售业测试集TAU-bench(retail)中,与DeepSeek-R1表现相当。
但在数学、编程能力等方面,其得分相比Qwen3-235B-A22B、DeepSeek-R1、Claude 4 Opus等都较低。
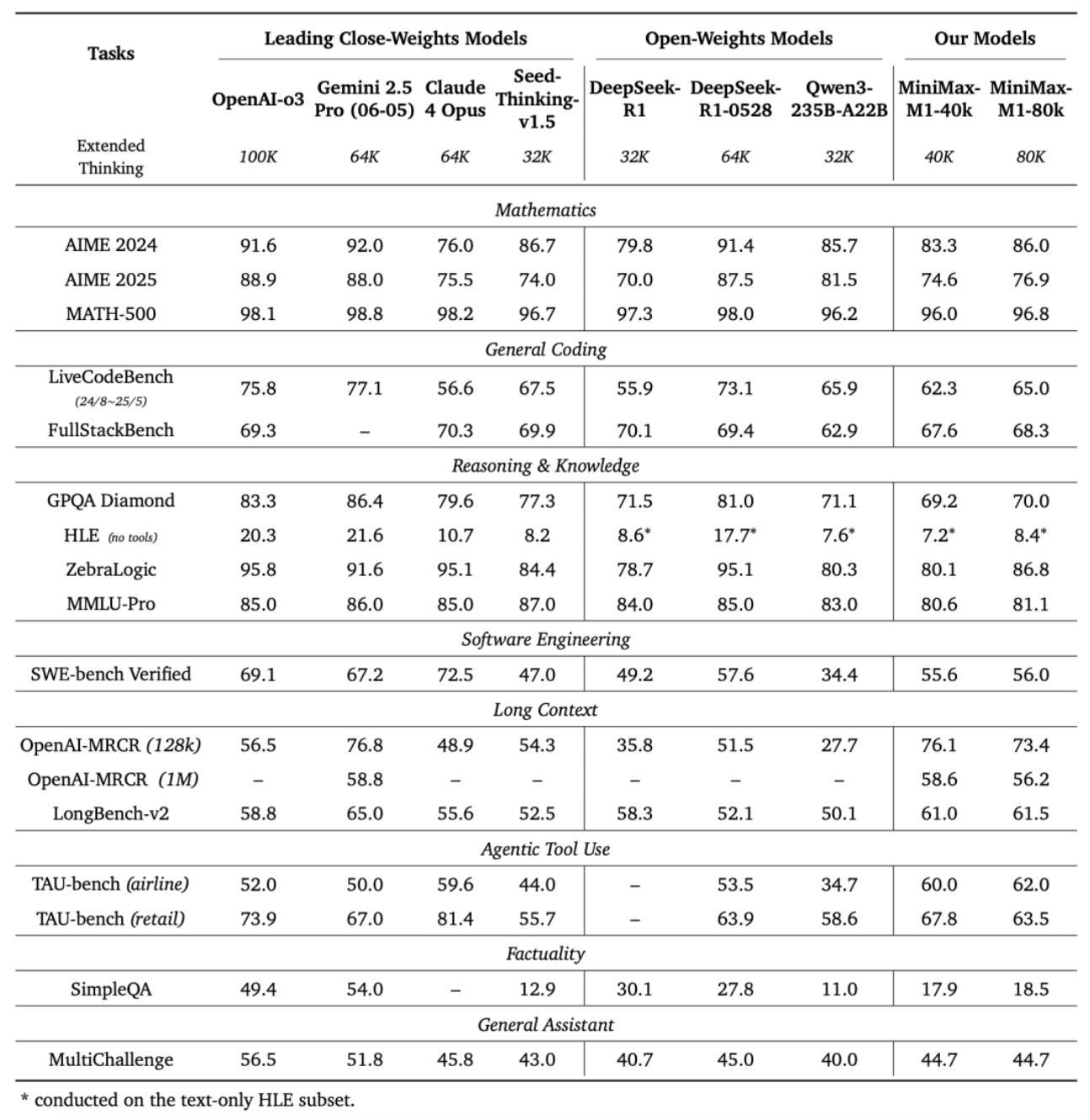
▲MiniMax-M1评测结果
与此同时,MiniMax-M1-80k在大多数基准测试中始终优于MiniMax-M1-40k,这可以验证其扩展测试时计算资源的有效性。
二、闪电注意力机制高校扩展计算,擅长处于长输入+广泛思考
M1是基于MiniMax-Text-01模型开发,采用了混合专家(MoE)架构和闪电注意力机制。
M1的闪电注意力机制可以高效扩展测试时计算。例如,与DeepSeek-R1相比,M1在10万个token的生成长度下只需消耗25%的FLOP,使得M1适合于需要处理长输入和广泛思考的复杂任务。
另一个技术重点是使用大规模强化学习(RL)进行训练,其应用范围可涵盖从传统数学推理到基于沙盒的真实软件工程环境等问题。
MiniMax为M1开发了RL扩展框架,重点包括:提出CISPO新算法,可通过裁剪重要性采样权重而非token更新来提升性能,其性能优于其他竞争性RL变体;其混合注意力机制设计能够提升RL效率,并利用混合架构来应对扩展RL时面临的挑战。
此外MiniMax提到,在AIME的实验中,他们发现CISPO比字节近期提出的DAPO等强化学习算法收敛性能快了一倍,显著优于DeepSeek早期使用的GRPO。
研究人员在基于Qwen2.5-32B-base模型的AIME 2024任务上,对GRPO、DAPO以及CISPO进行了对比,结果表明:在相同训练步数下,CISPO的性能优于GRPO和DAPO;而当使用50%的训练步数时,CISPO可达到与DAPO相当的性能表现。
结语:多Agent协作面临超长上下文、数百轮推理挑战
为了支持日益复杂的场景,大语言模型在测试或推理阶段,往往需要动态增加计算资源或计算步骤来提升模型性能,MiniMax在研究报告中提到,未来大模型尤其需要“Language-Rich Mediator”(富语言中介)来充当与环境、工具、计算机或其他与Agent交互的Agent,需要进行数十到数百轮的推理,同时集成来自不同来源的长上下文信息。
在这样的背景下,作为MiniMax推出的首个推理模型,MiniMax-M1正是其面对这一行业发展趋势在算法创新上的探索。
(来源:新浪科技)
