全球首个,英伟达用AI两个月造出“全新PyTorch”

新智元报道
编辑:Aeneas
【新智元导读】仅用两个月,AI 就「自己」写出了一个能跑模型、对标PyTorch的深度学习系统!陈天奇、贾扬清纷纷大赞:AI终将完全超越人类程序员。
最近,英伟达又发布了一个炸裂成果。
英伟达高级工程师Bing Xu开源了VibeTensor项目,并且表示:「这是第一个完全由 AI 智能体生成的深度学习系统,没有一行人类编写的代码。」
这是什么概念?深度学习运行时(Deep Learning Runtime),是让神经网络真正跑起来的底层系统系统。
仅仅用两个月,AI就自己写出了一个「深度学习运行时」。
它不是demo,不是PPT里的概念,是真正能跑起来的、对标PyTorch的一个系统!
这个项目也获得了陈天奇、贾扬清等大佬的盛赞。



两个月,AI写出比肩PyTorch的成果
AI,能不能从零生成一整套「深度学习系统软件」?这里指的,是那种真正的、工程师平时根本不敢让AI碰的底层系统。
答案是,可以。
VibeTensor是一个受PyTorch启发的即时运行时,它具有全新的C++20内核(CPU + CUDA)、torch风格的Python覆盖层以及实验性的Node.js/TypeScript API。
注意,它并不是一个轻量级封装器。它实现了自己的张量/存储、调度器、自动微分引擎、CUDA运行时和缓存分配器和插件ABI。

在VibeTensor项目中,人类只需要做这几件事:给出高层架构、定义约束条件,设定性能与可靠性目标。
剩下的事,就可以全部交给LLM驱动的编码智能体,包括C++核心运行时,Python API,Node.js接口等等。
英伟达工程师们,再也不用手动编写每一行代码了。
速度也是很惊人:仅仅用两个月时间,整个系统就开发完成了。
两个月,是什么概念?要知道,PyTorch经过了十年级别的演进,需要成百上千名工程师,进行无数次架构的重构。
而VibeTensor只需要2个月,由AI生成大量代码,还覆盖了完整的运行时链路。
当然,VibeTensor现在还不能取代PyTorch。虽然某些特定内核的速度更快,但它整体的训练性能仍然比PyTorch慢。
但这根本不是重点。
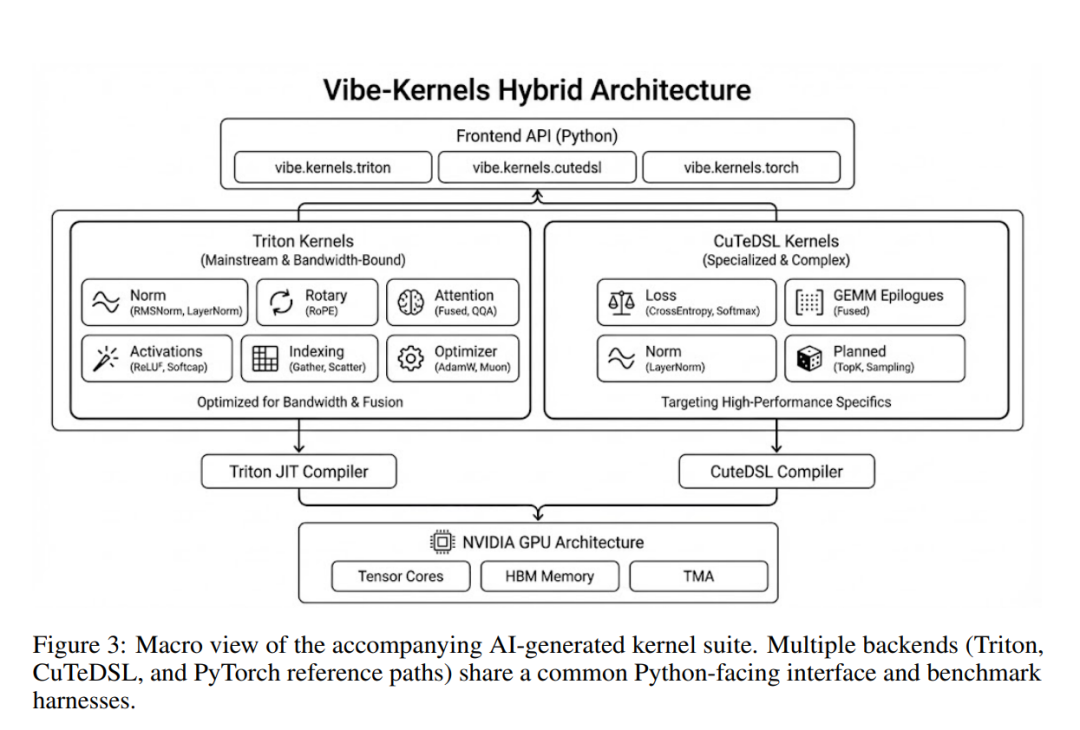
随论文一同发布的AI生成算子内核套件的宏观结构示意图,该套件包含多个后端实现(Triton、CuTeDSL以及PyTorch参考路径)
重点是,AI已经能造出PyTorch级别的复杂系统了。
这就证明:人工智能智能体已经足够强大,能够构建复杂的、功能齐全的软件系统,而不仅仅是简单的脚本。
编码智能体不仅能写函数,还能在测试约束下,协同生成并验证一个跨越多层抽象的复杂系统。
网友们纷纷惊呼:库兹维尔预言的递归改进循环,正在发生!
当然,AI智能体虽然可以编写大量代码,但最终成功与否,还要取决于项目是否附带评审。
有人说,英伟达真正的秀肌肉之处,在于敢把生产级的C++内核交给智能体来写。
这就意味着,英伟达背后,有着世界一流的测试基础设施,以及完善到位的运行时遥测体系。
用AI快速交付,其实并不难,真正困难的是如何可靠地交付——而这,依然是人类的护城河。

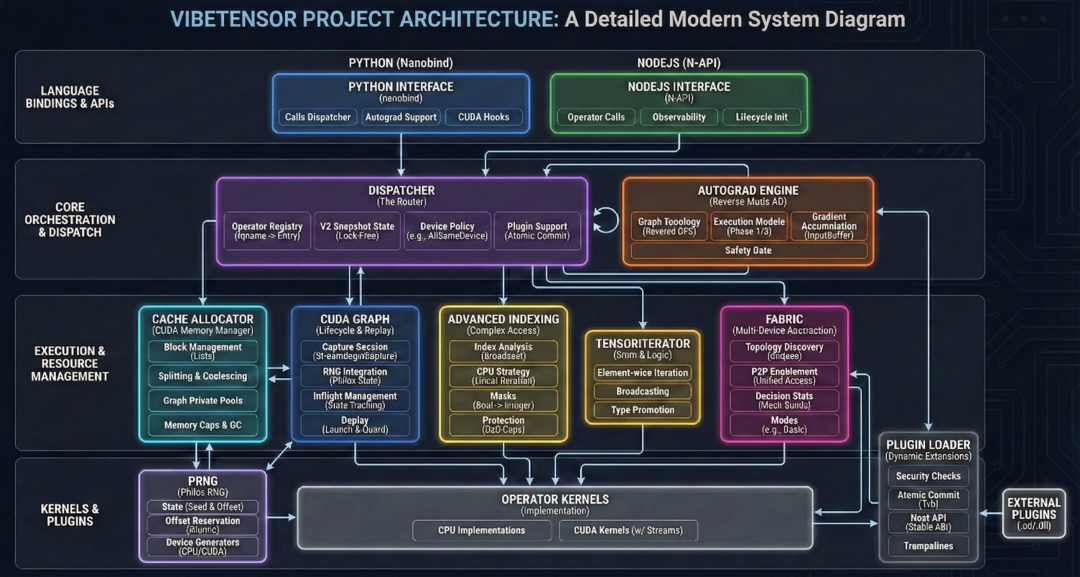
VibeTensor架构
这个架构的宏观视角,是这样的。
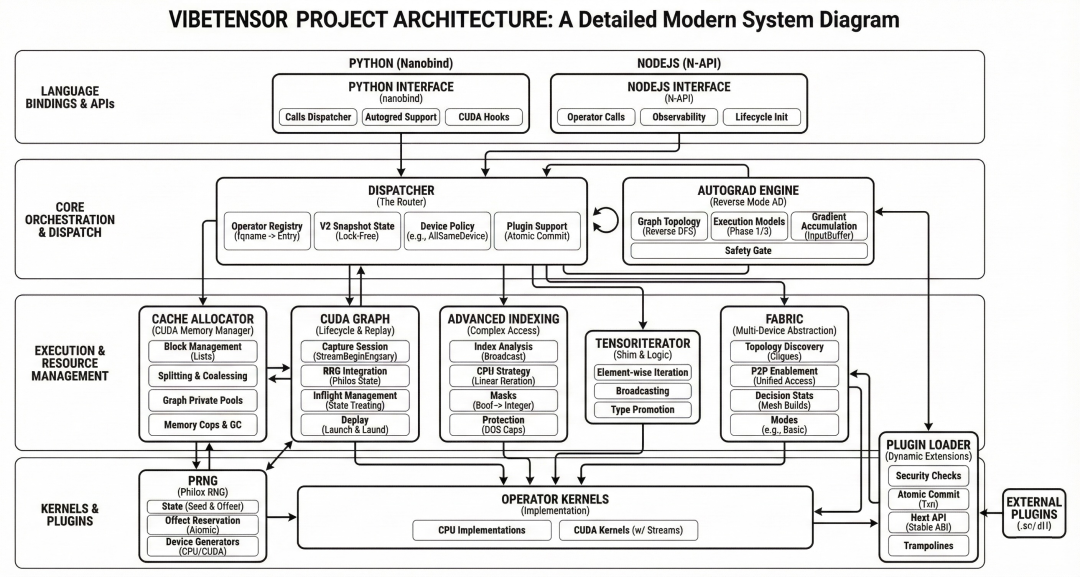
从使用体验上看,VibeTensor是一个受PyTorch启发的即时运行时,包括torch风格的Python API,以及熟悉的张量、算子、自动微分体验。
但在实现上,VibeTensor并不是PyTorch的封装或裁剪版,而是实现了自己的一整套系统栈。
从宏观层面来看,它由如下部分组成——
前端:Python(nanobind)和 Node.js(N-API)都向同一个C++运算符注册表分发。
核心运行时:张量/存储 + 调度器 + 自动微分 + 索引 + 随机数生成器。 CUDA运行时:流/事件包装器、分配器、图、内核启动助手。
计算层:内置CUDA内核 + 可选Triton/CuTeDSL内核 + 插件加载内核。 多GPU实验 :Fabric张量和可观测性(统计+事件环)。
更关键之处在于,它真的能训练模型。
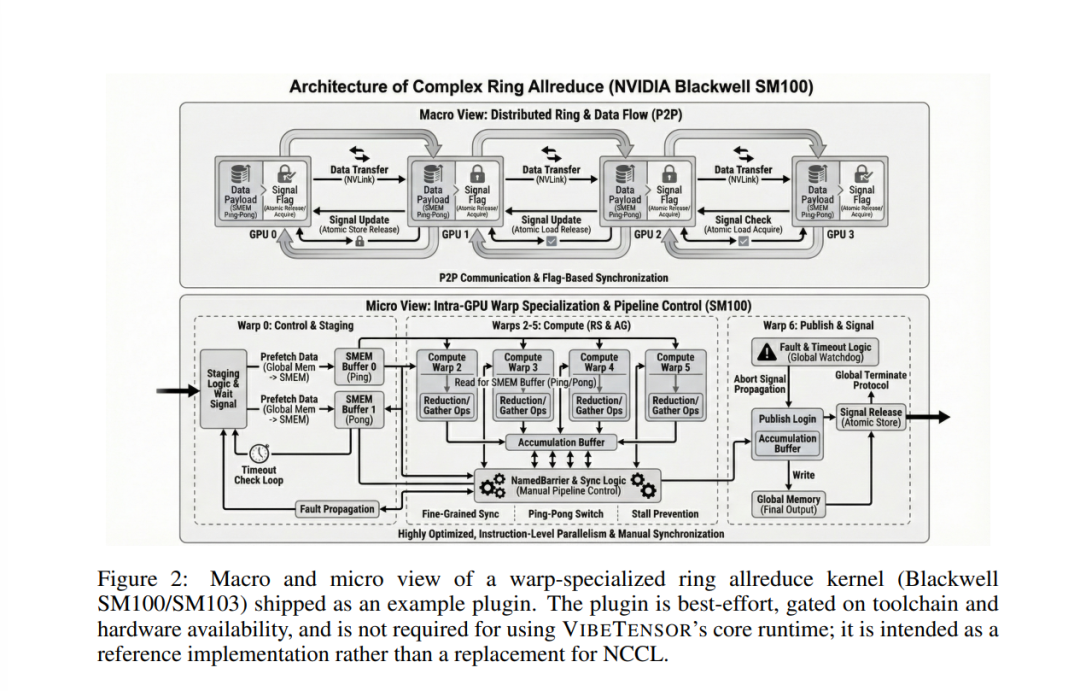
针对Blackwell架构(SM100/SM103)的warp级特化ring all-reduce内核的宏观与微观视图
在评估阶段,论文并没有止步于单算子正确性或micro-benchmark,而是刻意选择了完整训练闭环作为验证手段,覆盖了三类具有代表性的工作负载:序列反转任务、CIFAR-10 上的Vision Transformer,以及一个miniGPT风格的语言模型。
这三个任务并非随意挑选。
序列反转任务是经典的自动求导与时序依赖sanity check,能够快速暴露梯度回传、参数更新或状态复用中的隐藏错误。
CIFAR-10上的ViT则引入了更复杂的算子组合,验证系统在中等规模模型下的稳定性。
而miniGPT风格的语言模型则进一步拉长了训练步数,对长时间运行、多步梯度累积、显存管理和数值稳定性提出了更高要求。
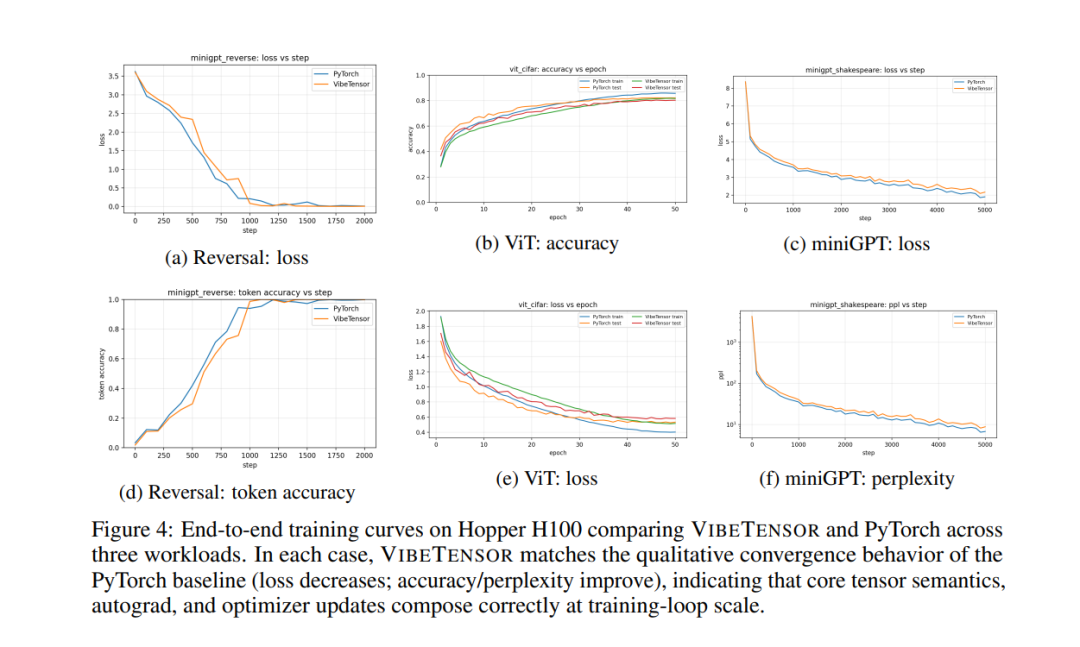
论文展示的训练曲线表明,在这些任务上,VibeTensor与PyTorch在整体收敛趋势上是高度一致的:loss能够稳定下降,accuracy或perplexity持续改善,没有出现梯度爆炸、训练发散或「跑几步就崩」的情况。
这一点尤其关键,因为它意味着系统中的多个核心子系统能够在真实训练循环中正确协同工作。

真正颠覆性的意义:工程边界被打破
英伟达这项研究真正颠覆性的意义,不在性能,而在「工程边界被打破」。
需要强调的是,作者非常克制:他们反复声明VibeTensor性能明显落后PyTorch,也不适合生产环境。
但这恰恰让这篇论文更有分量了。
因为它要证明的不是「AI能不能写出最优代码」,而是——系统软件,第一次被证明是「可被AI整体生成」的!
在过去,大家都默认一个隐含前提:AI可以写应用代码、脚本、业务逻辑,但系统软件、运行时、内存管理、并发控制,只能人写。
VibeTensor 第一次用一个可运行、可复现的工程告诉你:这个边界,正在被打穿。
另外,论文里一个非常重要、但容易被忽略的点是:测试不再只是验证工具,而是约束 AI 搜索空间的核心机制。
在这个项目中:测试约等于可执行的设计文档,回归测试是对抗「AI 局部正确、全局崩坏」的唯一手段,多步训练测试,则可以揪出单步算子永远发现不了的bug。
这本质上是在说:未来系统工程的核心能力,可能不是写代码,而是「设计好一套让 AI不敢乱来的测试体系」。
重要反面教材:「弗兰肯斯坦效应」
论文最后还非常坦诚地总结了AI写系统的典型失败模式,作者称之为弗兰肯斯坦效应。
简单说就是:每个子模块单独看都很合理,拼在一起却会把系统性能彻底拖垮。
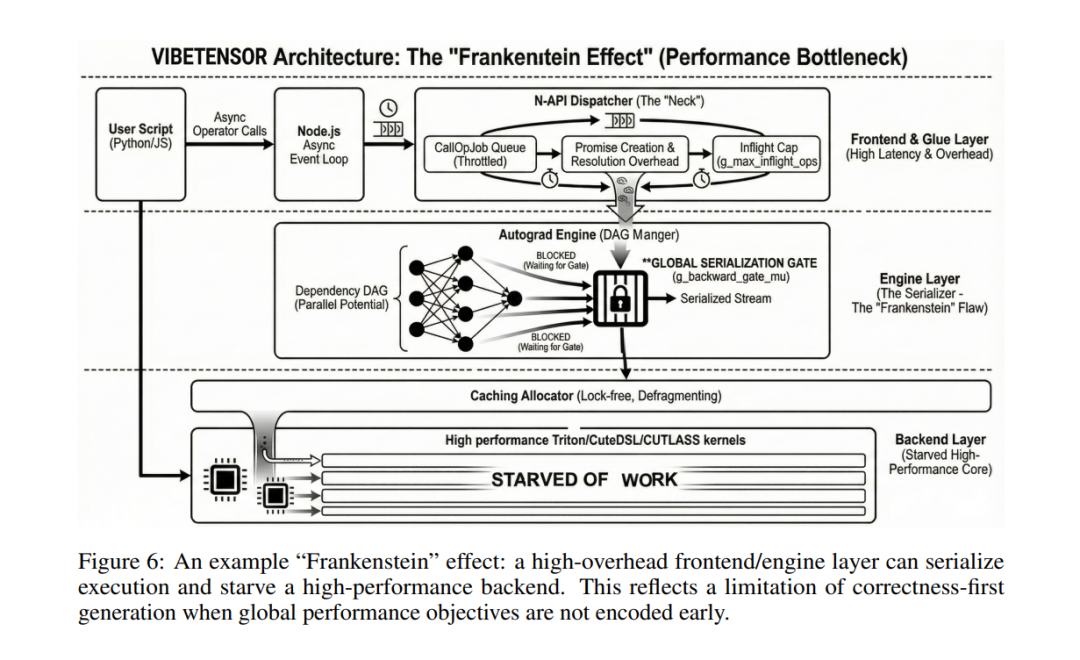
比如,为了安全性,AI在autograd引擎里加了一个全局backward锁。
从单点看这是对的,但结果却是:GPU kernel空转、并行性被扼杀、系统整体变慢好几倍。
这部分内容其实非常有价值,因为它说明了一件事:AI非常擅长「局部最优」,但极其不擅长全局性能目标。
而这,正是下一阶段AI系统工程必须正面解决的问题。
总之,如果用一句话来概括VibeTensor这篇论文的意义,那就是:这是第一篇用完整可运行系统证明「AI已经可以触碰深度学习系统工程核心腹地」的论文。
它不是终点,但很可能是一个分水岭。
英伟达3万工程师全员All in AI编程
最近,还有另一个内幕消息曝出:英伟达的30000名工程师在引入AI编程助手后,代码产出狂翻3倍!
英伟达很早就在内部尝试各种AI代码生成辅助工具,但自从定制版Cursor广泛部署之后,效能提升才真正「爆发」。
注意,Cursor并不是简单补全,而是一套可以:自动生成新代码、生成单元测试与集成测试、理解大规模代码库深层依赖关系、自动修bug的的「全流程AI编程助手」。
据英伟达工程负责人描述:Cursor现在在所有产品线、所有开发阶段都在使用。它能自动从 ticket、设计文档获取上下文,然后基于规则自动生成包括代码、测试、CI 在内的完整变更。
三倍代码量,是说AI写了很多垃圾代码吗?事实相反,英伟达强调:代码质量仍由人工负责审核和监督。
工程师会留出更多时间,给设计决策和复杂逻辑,把重复性工作交给AI完成。
从英伟达的角度来看,这种「让AI进入关键路径」的做法其实并不陌生。早在多年前,DLSS就已经在超算上运行了。
可见,英伟达并不是第一次将AI引入高风险、高复杂度的工程系统,而是已经积累了长期经验。
(来源:新浪科技)
