斯坦福华人天团意外爆冷!AI用纯CUDA-C编内核,竟干翻PyTorch?
【新智元导读】本想练练手合成点数据,没想到却一不小心干翻了PyTorch专家内核!斯坦福华人团队用纯CUDA-C写出的AI生成内核,瞬间惊艳圈内并登上Hacker News热榜。团队甚至表示:本来不想发这个结果的。
就在刚刚,斯坦福HAI华人大神团队又出惊人神作了。
他们用纯CUDA-C语言编写的快速AI生成内核,竟然超越了PyTorch!

在这个过程中,完全不用借助CUTLASS和Triton等库和领域特定语言(DSL),就能让性能表现接近PyTorch内置的、经过专家优化的标准生产级内核,甚至在某些情况下还更胜一筹。
作者团队都是我们熟悉的名字——Anne Ouyang、Azalia Mirhoseini和Percy Liang,有趣的是,他们甚至直言,这个结果其实本不想拿出来发布。
一经发布,这个发现就引爆了技术圈,现在已经登顶Hacker News总榜第二。
说起来,这个发现还有很多意外的成分。
本来,他们的目标是生成合成数据,来训练更好的内核生成模型,合成数据生成的设计也十分简单。
然而,意想不到的事情发生了,仅用于测试的合成数据生成本身,竟开始生成非常优秀的内核,甚至超越了人类专家优化的PyTorch基线,而且还利用了高级优化和硬件特性。
而在此前,这是一项很艰难的挑战。
由此,研究者们决定提前撰写博文,把自己的发现分享出来。
总结来说,研究的亮点成果如下:
矩阵乘法(Matmul, FP32):性能达到PyTorch FP32 torch.matmul的101.3%
二维卷积(Conv2D, FP32):性能达到PyTorch FP32 torch.nn.Conv2D的179.9%
Softmax(FP32):性能达到PyTorch FP32 torch.softmax的111.8%
层归一化(LayerNorm, FP32):性能达到PyTorch FP32 torch.nn.LayerNorm的484.4%
二维卷积 + ReLU + 最大池化(Conv2D + ReLU + MaxPool, FP32):性能达到PyTorch FP32参考实现的 290.1%,达到PyTorch FP32 torch.compile()参考实现的189.0%
以上结果在英伟达L40S GPU上进行了基准测试,性能百分比定义为参考时间除以生成的内核时间。

网友:强制LLM推理,实在太有趣了
在Hacker News上,网友们也对此展开了热烈讨论。
比如为什么使用FP32内核会比PyTorch更容易实现性能提升,理由就相当有趣。

如果AI真的能以更低成本,实现更优化的内核,的确潜力巨大。

最令人震撼的就是,无论是最近谷歌的AlphaEvolve,还是o3在Linux内核中发现了零日漏洞,都在提醒我们——
Gemini Pro 2.5和o3已经达到了一个全新的能力水平,那些曾经在其他模型上尝试失败的想法,现在突然奏效了。
可以说,我们已经到达了一个节点,LLM能比用人类快得多的速度进行迭代和测试,信息组合、进步和智能应用的蛮力,似乎正在成功!


接下来,我们来看看斯坦福研究者们博客中的具体内容。
博客全文
在博客中,研究者分享了具体方法、五个优化后的内核(包括4个基础机器学习算子和1个AlexNet模块的融合内核)、一个优化过程的实例,以及一些思考,关于这些发现对高性能内核生成可能意味着什么。
可以说,这些内容将是他们后续探索的第一步。
方法
研究者们采用了KernelBench的任务设置(这是他们在2024年12月发布的一款基于AI的内核生成基准测试)。
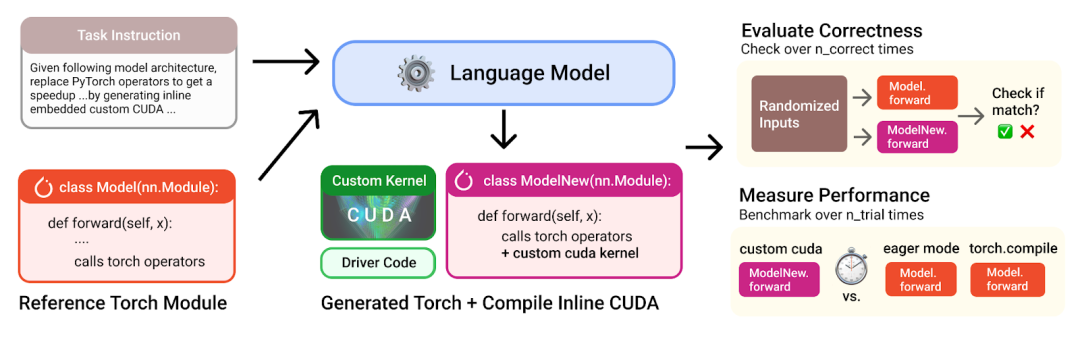
具体来说,给定一段torch代码,LLM会编写自定义内核来替换原有的torch算子,目标是实现加速。
依照KernelBench最初的设计,参考代码默认使用FP32精度;在给定的容差阈值(1e-02)下,采用较低精度的解决方案也是被允许的。
此外,由于存在大量针对特定规模的优化手段,KernelBench中的每个问题都设定了具体的输入大小。
因此,该基准测试旨在找出针对特定问题规模的最快内核,而非一个适用于任意问题规模的高速内核。
而且,研究者会同时运行torch参考代码和生成的代码,并通过在多种随机输入下比较两者输出的数值是否一致,来检验其正确性。
当前,在优化内核这个问题上,业界扩展测试时计算资源最常用的方法是顺序修订(sequential revision)。
这是一种多轮迭代的循环:模型首先对内核进行增量式修改,接着检查其正确性和性能,然后根据结果再次尝试。
也就是说,要么修复有问题的内核,要么进一步提升现有内核的性能。
这个循环过程非常直观,也容易实现。模型会修复失效的内核,微调可用的内核,一步步优化出性能更佳的版本。
这种方法的主要局限,在于优化思路缺乏多样性。
顺序循环往往容易陷入局部最优的困境,比如反复尝试同类型的转换,或是在缺乏潜力的优化路径上无休止地调整。
其结果便是测试时计算资源的低效利用,并且难以促使模型产生具有根本性创新的优化思路。
为解决这一问题,研究者引入了两项关键改变:
运用自然语言对优化思路进行推理
他们不再于每一步直接生成新的内核,而是以先前尝试过的思路为条件,用自然语言生成优化思路,随后将这些思路具化为新的代码变体。
在每个优化步骤进行分支扩展
他们不是每步只改进一个候选方案,而是进行分支扩展,让每个思路都能派生出多种实现版本,其中性能最佳的内核将作为下一轮优化的种子。
(研究者也会保留一个表现优异的现有内核库,用于提供种子)。
这种方式解锁了大规模的并行处理能力,使他们能够在每一轮探索截然不同的优化方向,避免陷入狭窄的优化路径。
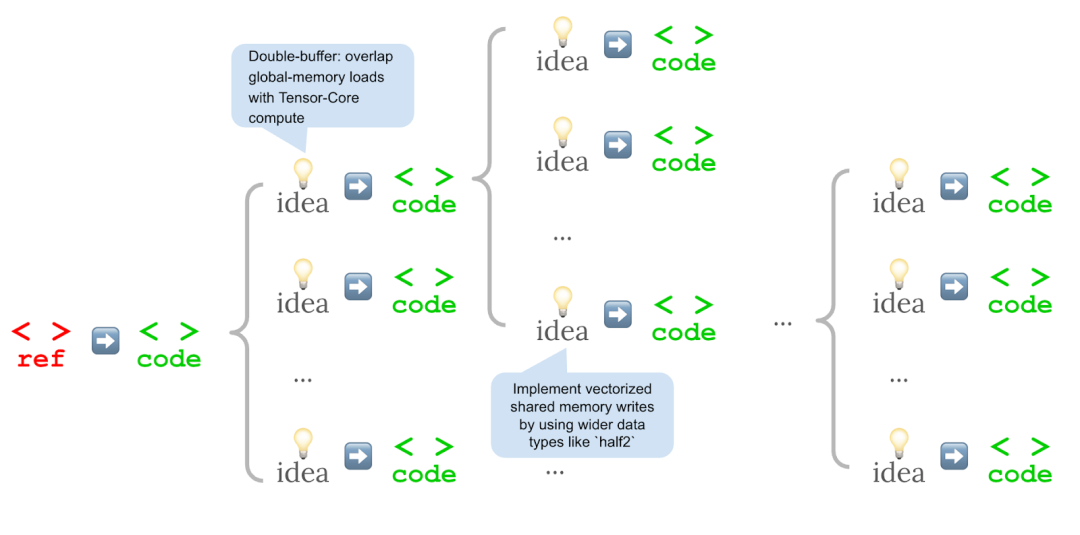
其结果是,这种测试时循环不再像顺序修订那般,仅仅是与编译器「对话」,而是更接近一种结构化的探索性搜索。
这种搜索由明确的优化假设指导,并采用大规模并行评估的方式进行。
研究者运行了KernelBench第1级的10个问题,以进行测试。
他们调整了问题规模,以确保内核启动开销相对于问题的整体运行时间而言可以忽略不计。
然后,使用OpenAI o3和Gemini 2.5 Pro模型进行了5轮实验。
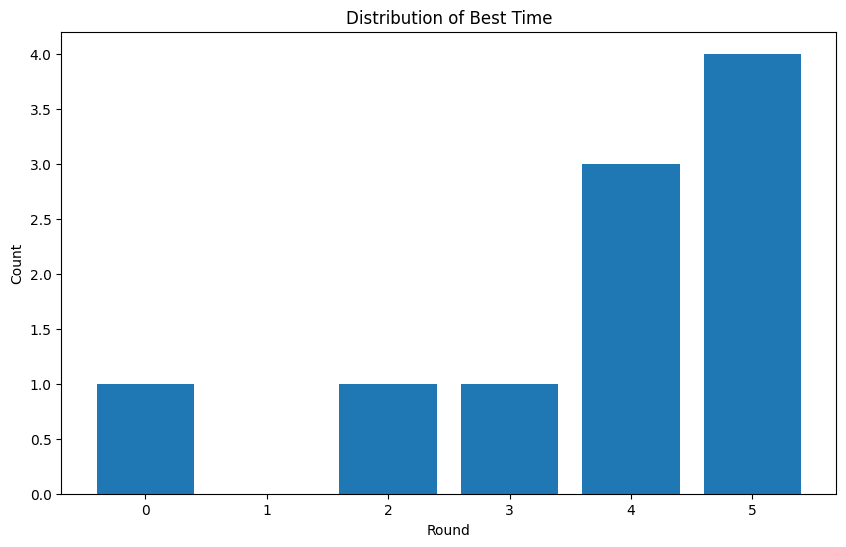
下图展示了首次发现性能最佳内核所在的轮次分布情况。
可以看到,大多数最优结果出现在靠后的轮次(总共5轮),其中绝大部分出现在第4轮或第5轮。
随着扩大搜索范围,研究者还发现:许多高性能内核的优化策略高度相似,集中在少数几种常见的模式上,这与他们手动编写内核的经验也是一致的。
主要的优化类别归纳如下——
内存访问优化:提升不同内存层级(全局内存、共享内存、寄存器)之间数据迁移的效率,并确保数据访问方式能够最大化带宽、最小化冲突。
异步操作与延迟隐藏:通过将耗时较长的操作(例如全局内存访问)与计算或其他内存传输重叠执行,来隐藏其带来的延迟。
数据类型与精度优化:在允许的条件下,尽可能使用较低精度的数据类型(如FP16或BF16),以降低内存带宽需求,提升缓存效率,并有望利用专门的硬件加速单元。
计算与指令优化:提升算术运算本身的效率,削减指令数量,或利用专门的硬件指令。
并行性与占用率增强:最大化流式多处理器(SM)上活跃线程束(warp)的数量,以便更好地隐藏延迟,提高整体吞吐率。
控制流与循环优化:减少由循环、分支及索引计算等引入的额外开销。
总结
这次研究者采用的方法,与AI研究中一个日益显著的趋势不谋而合——
将强大的推理能力与对多个假设的并行探索相结合,能够带来性能的提升。
正如一些近期研究(例如AlphaEvolve、Gemini 2.5 Pro Deep Think)所强调的,我们并不总是需要大规模的重新训练。

论文地址:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf
有时,巧妙的搜索和分支策略便足以催生科学创新、攻克复杂难题,而借助验证器进行广泛搜索,则可能带来更大的收益。
然而,这并不意味着我们不需要进一步的训练。
恰恰相反,研究者的这种方法,也有助于生成更优质的合成数据,用以改进未来的模型训练(这需要更多的问题实例)。
因此,它既是一种强大的测试时扩展方法,也是我们迈向更智能、数据效率更高的模型开发之路的一步。
而且,这次研究者展现的仅仅是初步的成果。这些优化结果的质量看起来相当可观,但仍有广阔的提升空间,例如产生更优的优化思路、生成更高质量的最终代码,以及将此方法应用于日益复杂的内核。
目前,研究者仍在积极改进的两个具体例子包括:
FP16 Matmul:性能达到torch.matmul的52%
FP16 Flash Attention:性能达到torch.nn.functional.scaled_dot_product_attention的9%
在现代机器学习任务中,FP32的应用不如FP16或BF16普遍,并且在较新的硬件上,针对FP32的优化往往也更少。
这或许能部分解释,为何基于FP32的内核更容易在性能上超越PyTorch。
作者介绍
Anne Ouyang

Anne Ouyang目前是斯坦福大学计算机科学(CS)博士生,在Scaling Intelligence Lab(可扩展智能实验室)进行研究。
她的研究兴趣主要集中在可扩展的自我改进机器学习系统,同时也广泛关注实证机器学习(empirical ML)和性能工程(performance engineering)。
此前,她在MIT获得学士和硕士学位,并曾在NVIDIA cuDNN团队工作,负责编写CUDA内核,用于加速GPU上的深度学习工作负载。
Azalia Mirhoseini

Azalia Mirhoseini是斯坦福大学计算机科学助理教授,也是Scaling Intelligence Lab(可扩展智能实验室)的创始人,并在Google DeepMind兼任高级研究科学家。
她的实验室致力于开发可扩展的自主演进人工智能系统与方法论,以期推动通用人工智能的发展。
在加入斯坦福大学之前,她曾在Google Brain和Anthropic等业界顶尖的人工智能实验室工作多年。
她过往的卓越成就包括:
提出混合专家(MoE)神经架构——目前已被前沿的AI模型广泛应用;
领导AlphaChip项目——一项将深度强化学习用于布局优化的开创性工作,并成功应用于谷歌AI加速器(TPU)及数据中心CPU等先进芯片的设计中;
在测试时计算的Scaling方面有深入的研究
Percy Liang
Percy Liang是斯坦福大学计算机科学副教授,兼任基础模型研究中心(CRFM)主任。同时也是CodaLab Worksheets的创建者,并借此坚定倡导科研工作的可复现性。
他目前专注于通过开源和严格的基准测试,提升基础模型(特别是大语言模型)的可及性与可理解性。
他曾围绕机器学习和自然语言处理领域进行了广泛研究,具体方向包括鲁棒性、可解释性、人机交互、学习理论、知识落地、语义学以及推理等。
此前,他于2004年在MIT获得学士学位,并于2011年在UC伯克利获得博士学位。
内核优化过程
最后,展示一个Conv2D自动生成思路的优化轨迹示例,torch参考基准时间为1.41毫秒。
第0轮:7.02毫秒,达到参考性能的20.1%
思路:给定pytorch代码,用CUDA Kernel替换操作。
第1轮:7.54毫秒,达到参考性能的18.8%
思路:通过使用__ldg加载不变的张量来利用只读缓存。
第2轮:3.46毫秒,达到参考性能的41.0%
思路:将卷积转换为FP16 Tensor-Core GEMM。
作者评论:这是一种算法优化,将卷积转换为隐式GEMM,这对于在Tensor Core上高效运行卷积至关重要
第3轮:3.67毫秒,达到参考性能的38.7%
思路:采用双缓冲cp.async管线,使全局内存加载与Tensor-Core计算重叠。
第4轮:3.46毫秒,达到参考性能的41.0%
思路:给定pytorch代码,使用隐式矩阵乘法(implicit matmul)的CUDA Kernel替换操作。给定的GEMM内核可能会有帮助。
作者评论:因为优化涉及到使用GEMM,所以在这一轮开始时,使用了一个之前生成的现有优秀GEMM内核作为种子,这个思路是手动编写的
第5轮:1.91毫秒,达到参考性能的74.9%
思路:在每个K-tile循环内部,预计算k_idx分解的内核/输入索引并在共享内存中重用,以避免冗余算术运算。
第6轮:1.37毫秒,达到参考性能的103.6%
思路:在共享内存中预计算并缓存N维GEMM索引,以减少输入数据加载循环内的冗余算术运算。
第7轮:1.38毫秒,达到参考性能的102.9%
思路:通过使用专用的每warp共享内存缓冲区来并行化CUDA内核输出,以消除写入全局内存时的warp级串行化。
第8轮:1.37毫秒,达到参考性能的103.6%
思路:在共享内存中预计算并缓存基础输入坐标,以减少输入数据加载过程中的冗余算术运算。
第9轮:1.36毫秒,达到参考性能的105.1%
思路:对B-fragment加载进行软件流水线处理,使下一个B-tile的共享内存读取与当前B-tile的WMMA计算重叠。
第10轮:1.07毫秒,达到参考性能的133.6%
思路:重用共享内存中预计算的N维GEMM分解来进行输出地址计算,避免冗余且高成本的除法/模运算。
第11轮:1.21毫秒,达到参考性能的117.4%
思路:在half WMMA运算中移除hi/lo分解,如果最终精度可接受,则依赖标准的FP16累积来提高性能。
第12轮:1.01毫秒,达到参考性能的141.2%
思路:通过在流水线的加载阶段动态计算K维索引,使用双缓冲使Asub(权重)和Bsub(输入)的K循环全局内存加载与MMA计算重叠。
第13轮:0.795毫秒,达到参考性能的179.9%
思路:通过使用像half2这样的更宽数据类型,为加载Asub_pipe和Bsub_pipe实现向量化的共享内存写入。
最终代码
最终生成的Conv2D内核代码,使用了先进的CUDA技术,就是人类自己写起来都很有挑战性的那种!
import torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.cpp_extension import load_inlineconv2d_implicit_gemm_cuda_source = r"""#include <torch/extension.h>#include <ATen/cuda/CUDAContext.h> // For at::cuda::getCurrentCUDAStream()#include <mma.h>#include <cuda_fp16.h>using namespace nvcuda;// WMMA tile dimensions#define WMMA_M 16#define WMMA_N 16#define WMMA_K 16// Skew padding for shared memory to avoid bank conflicts#define SKEW_HALF 8 // 8 half elements (16 bytes)// CUDA built-in warpSize is 32 for supported architectures (sm_70+)// This constant is used for host-side configuration (e.g. blockDim)#define CUDA_WARP_SIZE_CONST 32// Threadblock configuration#define WARPS_PER_BLOCK 8// THREADS_PER_BLOCK must be evaluatable by host compiler for blockDim configuration#define THREADS_PER_BLOCK (WARPS_PER_BLOCK * CUDA_WARP_SIZE_CONST)// Macro-tile dimensions computed by a threadblock// BLOCK_M_TILES_WMMA * WMMA_M = output channels processed by a block// BLOCK_N_TILES_WMMA * WMMA_N = output spatial elements processed by a block#define BLOCK_M_TILES_WMMA 8#define BLOCK_N_TILES_WMMA 8#define TILE_M_PER_BLOCK (BLOCK_M_TILES_WMMA * WMMA_M) // e.g., 8 * 16 = 128 (for C_out dimension)#define TILE_N_PER_BLOCK (BLOCK_N_TILES_WMMA * WMMA_N) // e.g., 8 * 16 = 128 (for N_batch * H_out * W_out dimension)// Vector size for shared memory writes (half2)#define VECTOR_SIZE_H2 2// Struct to hold precomputed N-dimension GEMM indicesstruct NDecomposed {int ow_eff;int oh_eff;int n_batch_idx;bool isValidPixel; // True if this pixel_idx is within N_gemm boundsint h_in_base;int w_in_base;};__global__ void conv2d_implicit_gemm_wmma_kernel(const float* __restrict__ input_ptr, // Input: (N, Cin, Hin, Win)const float* __restrict__ weight_ptr, // Weights: (Cout, Cin, Kh, Kw)const float* __restrict__ bias_ptr, // Bias: (Cout) or nullptrfloat* __restrict__ output_ptr, // Output: (N, Cout, Hout, Wout)const int N_batch, const int C_in, const int H_in, const int W_in,const int C_out, const int K_h, const int K_w,const int stride_h, const int stride_w,const int pad_h, const int pad_w,const int H_out, const int W_out,const int M_gemm, // C_outconst int N_gemm, // N_batch * H_out * W_outconst int K_gemm // C_in * K_h * K_w) {// Thread identificationconst int warp_id = threadIdx.x / warpSize; // 0 .. WARPS_PER_BLOCK-1const int lane_id = threadIdx.x % warpSize; // 0 .. 31 (or warpSize-1)// Top-left corner of the macro-tile this block is responsible for in GEMM termsconst int block_row_gemm_start = TILE_M_PER_BLOCK * blockIdx.y;const int block_col_gemm_start = TILE_N_PER_BLOCK * blockIdx.x;// Shared memory for tiles of A (weights) and B (input/im2col) - Double Buffered for K-loop pipelining__shared__ half Asub_pipe[2][TILE_M_PER_BLOCK][WMMA_K + SKEW_HALF];__shared__ half Bsub_pipe[2][TILE_N_PER_BLOCK][WMMA_K + SKEW_HALF];// Shared memory for precomputed N-indices__shared__ NDecomposed n_params_sh[TILE_N_PER_BLOCK];// Shared memory for output stage (per-warp buffers)__shared__ float C_shmem_output_buffers[WARPS_PER_BLOCK][WMMA_M][WMMA_N];// Accumulator fragments per warp.wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag[BLOCK_N_TILES_WMMA];#pragma unrollfor (int i = 0; i < BLOCK_N_TILES_WMMA; ++i) {wmma::fill_fragment(acc_frag[i], 0.0f);}// Populate n_params_sh once at the beginning of the kernelif (threadIdx.x < TILE_N_PER_BLOCK) {int r_b_tile_idx = threadIdx.x;int current_pixel_idx = block_col_gemm_start + r_b_tile_idx;if (current_pixel_idx < N_gemm) {n_params_sh[r_b_tile_idx].ow_eff = current_pixel_idx % W_out;int temp_div_wout = current_pixel_idx / W_out;n_params_sh[r_b_tile_idx].oh_eff = temp_div_wout % H_out;n_params_sh[r_b_tile_idx].n_batch_idx = temp_div_wout / H_out;n_params_sh[r_b_tile_idx].isValidPixel = true;n_params_sh[r_b_tile_idx].h_in_base = n_params_sh[r_b_tile_idx].oh_eff * stride_h - pad_h;n_params_sh[r_b_tile_idx].w_in_base = n_params_sh[r_b_tile_idx].ow_eff * stride_w - pad_w;} else {n_params_sh[r_b_tile_idx].isValidPixel = false;n_params_sh[r_b_tile_idx].ow_eff = 0;n_params_sh[r_b_tile_idx].oh_eff = 0;n_params_sh[r_b_tile_idx].n_batch_idx = 0;n_params_sh[r_b_tile_idx].h_in_base = 0;n_params_sh[r_b_tile_idx].w_in_base = 0;}}__syncthreads();// Constants for vectorized shared memory loading// Number of half2 elements along K-dim for a shared memory tile rowconst int NUM_H2_ELEMENTS_IN_K_DIM = WMMA_K / VECTOR_SIZE_H2;// Number of thread groups, where each group has NUM_H2_ELEMENTS_IN_K_DIM threads.// Each group is responsible for loading the K-dimension for one M-row (for A) or N-row (for B) at a time,// iterating over M-rows or N-rows with this step size.const int NUM_ROW_PROCESSING_GROUPS = THREADS_PER_BLOCK / NUM_H2_ELEMENTS_IN_K_DIM;// --- K-Loop Pipelining ---int num_k_tiles = (K_gemm + WMMA_K - 1) / WMMA_K;
// --- Prologue: Load first k-tile (k_tile_iter = 0) into pipe_idx = 0 ---if (num_k_tiles > 0) {int k_tile_start_prologue = 0;int current_pipe_idx_prologue = 0;// Load Asub_pipe[0] for k_tile_iter = 0{// This thread is responsible for the 'h2_idx_in_k_dim_A'-th half2 element// in the K-dimension of the shared memory tile.int h2_idx_in_k_dim_A = threadIdx.x % NUM_H2_ELEMENTS_IN_K_DIM;// Starting 'half' index in shared memory for this half2 write.int shmem_k_start_for_h2_A = h2_idx_in_k_dim_A * VECTOR_SIZE_H2;// Global k-indices for the two half elements.int k_global_A_0 = k_tile_start_prologue + shmem_k_start_for_h2_A;int k_global_A_1 = k_tile_start_prologue + shmem_k_start_for_h2_A + 1;// Decompose k_global_A_0int kw_eff_reg_A_0 = 0, kh_eff_reg_A_0 = 0, ic_eff_reg_A_0 = 0;bool is_valid_k_A_0 = (k_global_A_0 < K_gemm);if (is_valid_k_A_0) {kw_eff_reg_A_0 = k_global_A_0 % K_w;int temp_div_kw_A_0 = k_global_A_0 / K_w;kh_eff_reg_A_0 = temp_div_kw_A_0 % K_h;ic_eff_reg_A_0 = temp_div_kw_A_0 / K_h;}// Decompose k_global_A_1int kw_eff_reg_A_1 = 0, kh_eff_reg_A_1 = 0, ic_eff_reg_A_1 = 0;bool is_valid_k_A_1 = (k_global_A_1 < K_gemm);if (is_valid_k_A_1) {kw_eff_reg_A_1 = k_global_A_1 % K_w;int temp_div_kw_A_1 = k_global_A_1 / K_w;kh_eff_reg_A_1 = temp_div_kw_A_1 % K_h;ic_eff_reg_A_1 = temp_div_kw_A_1 / K_h;}
// This thread belongs to 'm_row_group_id_A'-th group of threads.// This group iterates over M-rows of the Asub_pipe tile.int m_row_group_id_A = threadIdx.x / NUM_H2_ELEMENTS_IN_K_DIM;for (int r_a_tile_base = m_row_group_id_A; r_a_tile_base < TILE_M_PER_BLOCK; r_a_tile_base += NUM_ROW_PROCESSING_GROUPS) {int oc_idx = block_row_gemm_start + r_a_tile_base;float weight_val_0 = 0.0f;if (oc_idx < C_out && is_valid_k_A_0) {weight_val_0 = weight_ptr[oc_idx * C_in * K_h * K_w +ic_eff_reg_A_0 * K_h * K_w +kh_eff_reg_A_0 * K_w +kw_eff_reg_A_0];}float weight_val_1 = 0.0f;if (oc_idx < C_out && is_valid_k_A_1) {weight_val_1 = weight_ptr[oc_idx * C_in * K_h * K_w +ic_eff_reg_A_1 * K_h * K_w +kh_eff_reg_A_1 * K_w +kw_eff_reg_A_1];}half2* smem_ptr_h2_A = reinterpret_cast<half2*>(&Asub_pipe[current_pipe_idx_prologue][r_a_tile_base][shmem_k_start_for_h2_A]);*smem_ptr_h2_A = make_half2(__float2half(weight_val_0), __float2half(weight_val_1));}}// Load Bsub_pipe[0] for k_tile_iter = 0{int h2_idx_in_k_dim_B = threadIdx.x % NUM_H2_ELEMENTS_IN_K_DIM;int shmem_k_start_for_h2_B = h2_idx_in_k_dim_B * VECTOR_SIZE_H2;int k_global_B_0 = k_tile_start_prologue + shmem_k_start_for_h2_B;int k_global_B_1 = k_tile_start_prologue + shmem_k_start_for_h2_B + 1;int kw_eff_reg_B_0 = 0, kh_eff_reg_B_0 = 0, ic_eff_reg_B_0 = 0;bool is_valid_k_B_0 = (k_global_B_0 < K_gemm);if (is_valid_k_B_0) {kw_eff_reg_B_0 = k_global_B_0 % K_w;int temp_div_kw_B_0 = k_global_B_0 / K_w;kh_eff_reg_B_0 = temp_div_kw_B_0 % K_h;ic_eff_reg_B_0 = temp_div_kw_B_0 / K_h;}int kw_eff_reg_B_1 = 0, kh_eff_reg_B_1 = 0, ic_eff_reg_B_1 = 0;bool is_valid_k_B_1 = (k_global_B_1 < K_gemm);if (is_valid_k_B_1) {kw_eff_reg_B_1 = k_global_B_1 % K_w;int temp_div_kw_B_1 = k_global_B_1 / K_w;kh_eff_reg_B_1 = temp_div_kw_B_1 % K_h;ic_eff_reg_B_1 = temp_div_kw_B_1 / K_h;}int n_row_group_id_B = threadIdx.x / NUM_H2_ELEMENTS_IN_K_DIM;for (int r_b_tile_base = n_row_group_id_B; r_b_tile_base < TILE_N_PER_BLOCK; r_b_tile_base += NUM_ROW_PROCESSING_GROUPS) {float input_val_0 = 0.0f;if (n_params_sh[r_b_tile_base].isValidPixel && is_valid_k_B_0) {const NDecomposed& current_n_params = n_params_sh[r_b_tile_base];int h_in_eff_0 = current_n_params.h_in_base + kh_eff_reg_B_0;int w_in_eff_0 = current_n_params.w_in_base + kw_eff_reg_B_0;if (h_in_eff_0 >= 0 && h_in_eff_0 < H_in && w_in_eff_0 >= 0 && w_in_eff_0 < W_in) {input_val_0 = input_ptr[current_n_params.n_batch_idx * C_in * H_in * W_in +ic_eff_reg_B_0 * H_in * W_in +h_in_eff_0 * W_in +w_in_eff_0];}}float input_val_1 = 0.0f;if (n_params_sh[r_b_tile_base].isValidPixel && is_valid_k_B_1) {const NDecomposed& current_n_params = n_params_sh[r_b_tile_base];int h_in_eff_1 = current_n_params.h_in_base + kh_eff_reg_B_1;int w_in_eff_1 = current_n_params.w_in_base + kw_eff_reg_B_1;if (h_in_eff_1 >= 0 && h_in_eff_1 < H_in && w_in_eff_1 >= 0 && w_in_eff_1 < W_in) {input_val_1 = input_ptr[current_n_params.n_batch_idx * C_in * H_in * W_in +ic_eff_reg_B_1 * H_in * W_in +h_in_eff_1 * W_in +w_in_eff_1];}}half2* smem_ptr_h2_B = reinterpret_cast<half2*>(&Bsub_pipe[current_pipe_idx_prologue][r_b_tile_base][shmem_k_start_for_h2_B]);*smem_ptr_h2_B = make_half2(__float2half(input_val_0), __float2half(input_val_1));}}}// Loop over the K_gemm dimension in tiles of WMMA_Kfor (int k_tile_iter = 0; k_tile_iter < num_k_tiles; ++k_tile_iter) {__syncthreads(); // Sync point for pipeliningint compute_pipe_idx = k_tile_iter % 2;int load_pipe_idx = (k_tile_iter + 1) % 2;// --- Load Stage for next k-tile (k_tile_iter + 1) into load_pipe_idx ---int k_tile_start_for_load = (k_tile_iter + 1) * WMMA_K;if (k_tile_start_for_load < K_gemm) {// Load Asub_pipe[load_pipe_idx]{int h2_idx_in_k_dim_A = threadIdx.x % NUM_H2_ELEMENTS_IN_K_DIM;int shmem_k_start_for_h2_A = h2_idx_in_k_dim_A * VECTOR_SIZE_H2;int k_global_A_0 = k_tile_start_for_load + shmem_k_start_for_h2_A;int k_global_A_1 = k_tile_start_for_load + shmem_k_start_for_h2_A + 1;int kw_eff_reg_A_0 = 0, kh_eff_reg_A_0 = 0, ic_eff_reg_A_0 = 0;bool is_valid_k_A_0 = (k_global_A_0 < K_gemm);if (is_valid_k_A_0) {kw_eff_reg_A_0 = k_global_A_0 % K_w;int temp_div_kw_A_0 = k_global_A_0 / K_w;kh_eff_reg_A_0 = temp_div_kw_A_0 % K_h;ic_eff_reg_A_0 = temp_div_kw_A_0 / K_h;}int kw_eff_reg_A_1 = 0, kh_eff_reg_A_1 = 0, ic_eff_reg_A_1 = 0;bool is_valid_k_A_1 = (k_global_A_1 < K_gemm);if (is_valid_k_A_1) {kw_eff_reg_A_1 = k_global_A_1 % K_w;int temp_div_kw_A_1 = k_global_A_1 / K_w;kh_eff_reg_A_1 = temp_div_kw_A_1 % K_h;ic_eff_reg_A_1 = temp_div_kw_A_1 / K_h;}
int m_row_group_id_A = threadIdx.x / NUM_H2_ELEMENTS_IN_K_DIM;for (int r_a_tile_base = m_row_group_id_A; r_a_tile_base < TILE_M_PER_BLOCK; r_a_tile_base += NUM_ROW_PROCESSING_GROUPS) {int oc_idx = block_row_gemm_start + r_a_tile_base;float weight_val_0 = 0.0f;if (oc_idx < C_out && is_valid_k_A_0) {weight_val_0 = weight_ptr[oc_idx * C_in * K_h * K_w +ic_eff_reg_A_0 * K_h * K_w +kh_eff_reg_A_0 * K_w +kw_eff_reg_A_0];}float weight_val_1 = 0.0f;if (oc_idx < C_out && is_valid_k_A_1) {weight_val_1 = weight_ptr[oc_idx * C_in * K_h * K_w +ic_eff_reg_A_1 * K_h * K_w +kh_eff_reg_A_1 * K_w +kw_eff_reg_A_1];}half2* smem_ptr_h2_A = reinterpret_cast<half2*>(&Asub_pipe[load_pipe_idx][r_a_tile_base][shmem_k_start_for_h2_A]);*smem_ptr_h2_A = make_half2(__float2half(weight_val_0), __float2half(weight_val_1));}}// Load Bsub_pipe[load_pipe_idx]{int h2_idx_in_k_dim_B = threadIdx.x % NUM_H2_ELEMENTS_IN_K_DIM;int shmem_k_start_for_h2_B = h2_idx_in_k_dim_B * VECTOR_SIZE_H2;int k_global_B_0 = k_tile_start_for_load + shmem_k_start_for_h2_B;int k_global_B_1 = k_tile_start_for_load + shmem_k_start_for_h2_B + 1;int kw_eff_reg_B_0 = 0, kh_eff_reg_B_0 = 0, ic_eff_reg_B_0 = 0;bool is_valid_k_B_0 = (k_global_B_0 < K_gemm);if (is_valid_k_B_0) {kw_eff_reg_B_0 = k_global_B_0 % K_w;int temp_div_kw_B_0 = k_global_B_0 / K_w;kh_eff_reg_B_0 = temp_div_kw_B_0 % K_h;ic_eff_reg_B_0 = temp_div_kw_B_0 / K_h;}int kw_eff_reg_B_1 = 0, kh_eff_reg_B_1 = 0, ic_eff_reg_B_1 = 0;bool is_valid_k_B_1 = (k_global_B_1 < K_gemm);if (is_valid_k_B_1) {kw_eff_reg_B_1 = k_global_B_1 % K_w;int temp_div_kw_B_1 = k_global_B_1 / K_w;kh_eff_reg_B_1 = temp_div_kw_B_1 % K_h;ic_eff_reg_B_1 = temp_div_kw_B_1 / K_h;}int n_row_group_id_B = threadIdx.x / NUM_H2_ELEMENTS_IN_K_DIM;for (int r_b_tile_base = n_row_group_id_B; r_b_tile_base < TILE_N_PER_BLOCK; r_b_tile_base += NUM_ROW_PROCESSING_GROUPS) {float input_val_0 = 0.0f;if (n_params_sh[r_b_tile_base].isValidPixel && is_valid_k_B_0) {const NDecomposed& current_n_params = n_params_sh[r_b_tile_base];int h_in_eff_0 = current_n_params.h_in_base + kh_eff_reg_B_0;int w_in_eff_0 = current_n_params.w_in_base + kw_eff_reg_B_0;if (h_in_eff_0 >= 0 && h_in_eff_0 < H_in && w_in_eff_0 >= 0 && w_in_eff_0 < W_in) {input_val_0 = input_ptr[current_n_params.n_batch_idx * C_in * H_in * W_in +ic_eff_reg_B_0 * H_in * W_in +h_in_eff_0 * W_in +w_in_eff_0];}}float input_val_1 = 0.0f;if (n_params_sh[r_b_tile_base].isValidPixel && is_valid_k_B_1) {const NDecomposed& current_n_params = n_params_sh[r_b_tile_base];int h_in_eff_1 = current_n_params.h_in_base + kh_eff_reg_B_1;int w_in_eff_1 = current_n_params.w_in_base + kw_eff_reg_B_1;if (h_in_eff_1 >= 0 && h_in_eff_1 < H_in && w_in_eff_1 >= 0 && w_in_eff_1 < W_in) {input_val_1 = input_ptr[current_n_params.n_batch_idx * C_in * H_in * W_in +ic_eff_reg_B_1 * H_in * W_in +h_in_eff_1 * W_in +w_in_eff_1];}}half2* smem_ptr_h2_B = reinterpret_cast<half2*>(&Bsub_pipe[load_pipe_idx][r_b_tile_base][shmem_k_start_for_h2_B]);*smem_ptr_h2_B = make_half2(__float2half(input_val_0), __float2half(input_val_1));}}}// --- Compute Stage for current k-tile (k_tile_iter) using compute_pipe_idx ---int a_row_start_in_tile = warp_id * WMMA_M;wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> a_frag;wmma::load_matrix_sync(a_frag, &Asub_pipe[compute_pipe_idx][a_row_start_in_tile][0], WMMA_K + SKEW_HALF);wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> b_frag_inner_pipe[2];if (BLOCK_N_TILES_WMMA > 0) {int b_col_start_in_tile_current = 0 * WMMA_N;wmma::load_matrix_sync(b_frag_inner_pipe[0], &Bsub_pipe[compute_pipe_idx][b_col_start_in_tile_current][0], WMMA_K + SKEW_HALF);}
int current_inner_pipe_idx = 0;#pragma unrollfor (int n_tile = 0; n_tile < BLOCK_N_TILES_WMMA; ++n_tile) {int next_inner_pipe_idx = 1 - current_inner_pipe_idx;if (n_tile < BLOCK_N_TILES_WMMA - 1) {int b_col_start_in_tile_next = (n_tile + 1) * WMMA_N;wmma::load_matrix_sync(b_frag_inner_pipe[next_inner_pipe_idx], &Bsub_pipe[compute_pipe_idx][b_col_start_in_tile_next][0], WMMA_K + SKEW_HALF);}wmma::mma_sync(acc_frag[n_tile], a_frag, b_frag_inner_pipe[current_inner_pipe_idx], acc_frag[n_tile]);
current_inner_pipe_idx = next_inner_pipe_idx;}}__syncthreads();// Store results from accumulator fragments to global memory#pragma unrollfor (int n_tile = 0; n_tile < BLOCK_N_TILES_WMMA; ++n_tile) {wmma::store_matrix_sync(&C_shmem_output_buffers[warp_id][0][0], acc_frag[n_tile], WMMA_N, wmma::mem_row_major);for (int elem_idx_in_frag = lane_id; elem_idx_in_frag < WMMA_M * WMMA_N; elem_idx_in_frag += warpSize) {int r_frag = elem_idx_in_frag / WMMA_N;int c_frag = elem_idx_in_frag % WMMA_N;int oc_idx = block_row_gemm_start + (warp_id * WMMA_M) + r_frag;
int offset_in_block_N_processing = (n_tile * WMMA_N) + c_frag;if (oc_idx < C_out && offset_in_block_N_processing < TILE_N_PER_BLOCK &&n_params_sh[offset_in_block_N_processing].isValidPixel) {const NDecomposed& current_n_params = n_params_sh[offset_in_block_N_processing];int ow_eff = current_n_params.ow_eff;int oh_eff = current_n_params.oh_eff;int n_batch_idx = current_n_params.n_batch_idx;float val = C_shmem_output_buffers[warp_id][r_frag][c_frag];if (bias_ptr != nullptr) {val += bias_ptr[oc_idx];}output_ptr[n_batch_idx * C_out * H_out * W_out +oc_idx * H_out * W_out +oh_eff * W_out +ow_eff] = val;}}}}torch::Tensor conv2d_implicit_gemm_cuda(torch::Tensor input, torch::Tensor weight, torch::Tensor bias,int N_batch, int C_in, int H_in, int W_in,int C_out, int K_h, int K_w,int stride_h, int stride_w, int pad_h, int pad_w,int H_out, int W_out) {TORCH_CHECK(input.device().is_cuda(), "Input must be a CUDA tensor");TORCH_CHECK(weight.device().is_cuda(), "Weight must be a CUDA tensor");TORCH_CHECK(input.dtype() == torch::kFloat32, "Input must be float32");TORCH_CHECK(weight.dtype() == torch::kFloat32, "Weight must be float32");if (bias.defined()) {TORCH_CHECK(bias.device().is_cuda(), "Bias must be a CUDA tensor");TORCH_CHECK(bias.dtype() == torch::kFloat32, "Bias must be float32");TORCH_CHECK(bias.dim() == 1 && bias.size(0) == C_out, "Bias has wrong shape");}TORCH_CHECK(input.dim() == 4, "Input must be 4D");TORCH_CHECK(weight.dim() == 4, "Weight must be 4D");TORCH_CHECK(input.size(0) == N_batch, "Input N_batch mismatch");TORCH_CHECK(input.size(1) == C_in, "Input C_in mismatch");TORCH_CHECK(input.size(2) == H_in, "Input H_in mismatch");TORCH_CHECK(input.size(3) == W_in, "Input W_in mismatch");TORCH_CHECK(weight.size(0) == C_out, "Weight C_out mismatch");TORCH_CHECK(weight.size(1) == C_in, "Weight C_in mismatch");TORCH_CHECK(weight.size(2) == K_h, "Weight K_h mismatch");TORCH_CHECK(weight.size(3) == K_w, "Weight K_w mismatch");auto output = torch::zeros({N_batch, C_out, H_out, W_out}, input.options());const int M_gemm = C_out;const int N_gemm = N_batch * H_out * W_out;const int K_gemm = C_in * K_h * K_w;if (M_gemm == 0 || N_gemm == 0) {return output;}if (K_gemm == 0) {if (bias.defined()) {output = output + bias.reshape({1, C_out, 1, 1});}return output;}dim3 block_dim(THREADS_PER_BLOCK);dim3 grid_dim((N_gemm + TILE_N_PER_BLOCK - 1) / TILE_N_PER_BLOCK,(M_gemm + TILE_M_PER_BLOCK - 1) / TILE_M_PER_BLOCK);const float* bias_ptr_data = bias.defined() ? bias.data_ptr<float>() : nullptr;cudaStream_t stream = at::cuda::getCurrentCUDAStream();conv2d_implicit_gemm_wmma_kernel<<<grid_dim, block_dim, 0, stream>>>(input.data_ptr<float>(),weight.data_ptr<float>(),bias_ptr_data,output.data_ptr<float>(),N_batch, C_in, H_in, W_in,C_out, K_h, K_w,stride_h, stride_w, pad_h, pad_w,H_out, W_out,M_gemm, N_gemm, K_gemm);
AT_CUDA_CHECK(cudaGetLastError());return output;}"""conv2d_implicit_gemm_cuda_declaration = r"""torch::Tensor conv2d_implicit_gemm_cuda(torch::Tensor input, torch::Tensor weight, torch::Tensor bias,int N_batch, int C_in, int H_in, int W_in,int C_out, int K_h, int K_w,int stride_h, int stride_w, int pad_h, int pad_w,int H_out, int W_out);"""# JIT compile the CUDA kernelcustom_conv2d_wmma_ops = load_inline(name="custom_conv2d_wmma_ops_optimized_k_pipe_vec_smem", # Changed name to avoid collisioncpp_sources=conv2d_implicit_gemm_cuda_declaration,cuda_sources=conv2d_implicit_gemm_cuda_source,functions=["conv2d_implicit_gemm_cuda"],verbose=True,extra_cuda_cflags=["-arch=sm_70", "--use_fast_math", "-std=c++17"])class ModelNew(nn.Module):def __init__(self, num_classes=1000): # num_classes is part of original signature, kept for consistencysuper(ModelNew, self).__init__()
# Define Conv1 parameters (matching the original model)self.in_channels = 3self.out_channels = 96self.kernel_size_val = 11 # Assuming square kernelself.stride_val = 4 # Assuming square strideself.padding_val = 2 # Assuming square padding# Create a temporary Conv2d layer to initialize weights and biastemp_conv = nn.Conv2d(in_channels=self.in_channels,out_channels=self.out_channels,kernel_size=self.kernel_size_val,stride=self.stride_val,padding=self.padding_val,bias=True # nn.Conv2d has bias=True by default)self.conv1_weight = nn.Parameter(temp_conv.weight.detach().clone())if temp_conv.bias is not None:self.conv1_bias = nn.Parameter(temp_conv.bias.detach().clone())else:# Correctly register 'conv1_bias' as None if not presentself.register_parameter('conv1_bias', None)self.custom_conv_op = custom_conv2d_wmma_ops.conv2d_implicit_gemm_cudadef forward(self, x):N_batch = x.size(0)# C_in_runtime = x.size(1) # Should match self.in_channelsH_in = x.size(2)W_in = x.size(3)# Calculate output dimensionsH_out = (H_in + 2 * self.padding_val - self.kernel_size_val) // self.stride_val + 1W_out = (W_in + 2 * self.padding_val - self.kernel_size_val) // self.stride_val + 1
# Bias tensor handling: pass an undefined tensor if bias is None.# The C++ TORCH_CHECK(bias.defined()) handles this by providing nullptr to kernel.bias_tensor = self.conv1_bias if self.conv1_bias is not None else torch.Tensor()x = self.custom_conv_op(x, self.conv1_weight, bias_tensor,N_batch, self.in_channels, H_in, W_in,self.out_channels, self.kernel_size_val, self.kernel_size_val, # K_h, K_wself.stride_val, self.stride_val, # stride_h, stride_wself.padding_val, self.padding_val, # pad_h, pad_wH_out, W_out)return x
参考资料:
https://crfm.stanford.edu/2025/05/28/fast-kernels.html
https://news.ycombinator.com/item?id=44139454
(来源:新浪科技)
