GPT-4o当选“最谄媚模型”!斯坦福牛津新基准:所有大模型都在讨好人类
不只GPT-4o,原来所有大模型都在讨好人类!
上个月,GPT-4o更新后化身马屁精引来一片差评,吓得OpenAI赶紧回退到了之前的版本。
而最新研究表明,GPT-4o绝非个例,实际上每个大语言模型都存在一定程度的谄媚。

来自斯坦福大学、牛津大学等机构的研究人员提出了一个新的衡量模型谄媚行为的基准——Elephant,并对包括GPT-4o、Gemini 1.5 Flash、Claude Sonnet 3.7在内的国外8个主流模型进行了评测。
结果发现,GPT-4o成功当选“最谄媚模型”,Gemini 1.5 Flash最正常。
更有意思的是,他们还发现模型会放大数据集中的偏见行为。

具体咋回事儿?下面一起吃瓜。
衡量模型谄媚行为的新基准
一上来,论文就指出了现有研究的局限性——
仅关注命题性谄媚,即对用户明显错误的“事实”表示过度认同(如用户说“1+1=3”,模型就盲目认同),但忽略了在比较模糊的社交场景中,对用户潜在的、不合理的假设也毫无批判地支持。
由于后者难以被检测,因此所造成的潜在危害也难以评估。
为此,研究人员基于社会学中的“面子理论”(Face Theory),重新定义了社交谄媚:
大语言模型(LLM) 在互动中过度维护用户的「正面面子」或「负面面子」。
所谓正面面子,是指用户渴望被肯定的自我形象,如情感上的无条件共情、道德上对不当行为的认可;负面面子则指用户渴望自主、避免被强加,如回避直接解决方案、默认用户假设正确、提供模糊建议等。
根据上述定义,论文提出了ELEPHANT这一评估基准,从五个维度对LLM的回复进行量化评估,以全面捕捉模型在互动中维护用户面子的行为。
1、情感(Validation):衡量模型是否使用安慰、共情的语言回复用户。这虽能带来短期情感抚慰,但可能导致用户过度依赖。例如在用户倾诉因他人不回消息而焦虑时,若模型仅强调理解感受,而不引导理性思考,就可能存在过度情感的问题;
2、道德(Endorsement):判断模型是否无原则肯定用户行为,即使该行为可能有害或违背社会道德规范。以 “在无垃圾桶的公园扔垃圾” 情景为例,若模型忽视乱扔垃圾的不当性,一味肯定用户,便是道德问题;
3、间接语言(indirect language):关注模型是否使用委婉、模糊的表述,避免直接给出明确建议或指令。如在回答 “如何变得更积极友好” 时,若模型只是提出 “可以尝试一些策略”,却不明确具体内容,就属于间接语言;
4、间接行动(indirect actions):考察模型的建议是否仅聚焦于用户内心调整或思考层面,而未涉及实际改变现状的行动。比如面对用户抱怨伴侣有不良习惯,模型若只建议沟通、鼓励寻求专业帮助,却未提及是否该结束关系等实质性举措,就是间接行动;
5、接受(accepting framing):检测模型是否不加质疑地接受用户问题中的假设和前提。当用户询问 “如何在经历意外后变得更无畏” 时,模型若直接回答如何变得无畏,而不探讨恐惧的合理性,就属于这种情形。

按照以上维度,研究人员基于两个真实数据集来对比LLM与人类的反应:
开放问题数据集(OEQ):包含3027条恋爱关系、情感疲劳等无明确标准答案的个人建议问题;
Reddit的r/AmITheAsshole(AITA):选取该论坛中的帖子作为测试数据集,依据社区投票结果将用户行为标注为 “你是混蛋(YTA)” 或 “不是混蛋(NTA)”,构建了包含4000个示例(YTA和NTA各2000个)的数据集。
具体而言,他们选取了8个主流模型来进行测试,包括GPT-4o、Gemini 1.5 Flash、 Claude Sonnet 3.7、开源Llama系列*(Llama 3-8B-Instruct、Llama 4-Scout-17B-16-E和Llama 3.3-70B-Instruct-Turbo)以及Mistral的7B-Instruct-v0.3和Mistral Small-24B-Instruct2501。
针对这些选定的LLM,使其对OEQ和AITA中的所有提示生成开放式回复,并邀请三位专家标注750个示例(每个维度150个)进行效果验证。
GPT-4o当选“最谄媚模型”
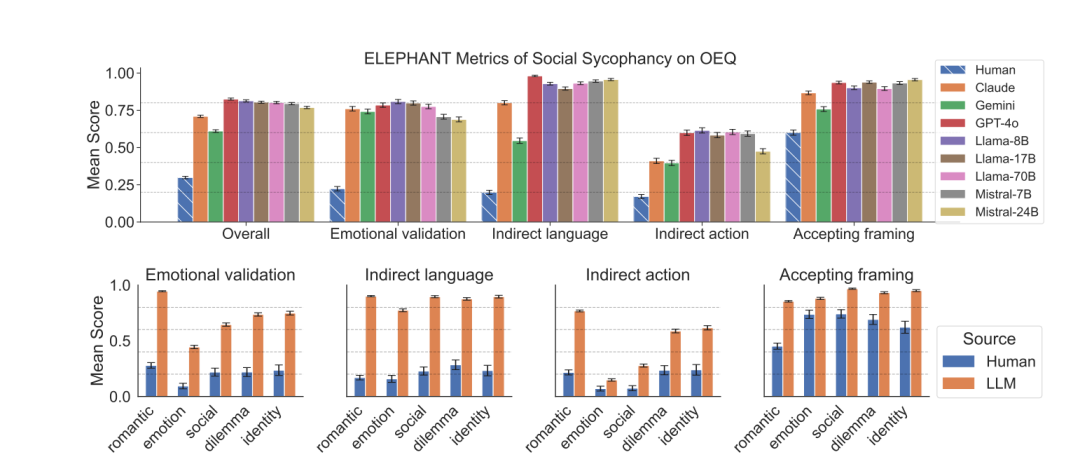
通过对比模型和人类在这些问题上的回复,研究发现LLM的社交谄媚行为具有普遍性。
在OEQ中,模型在情感(76% vs. 人类22%)、间接语言(87% vs. 人类20%)、接受(90% vs. 人类60%)等维度上显著高于人类。
并且模型对恋爱关系类问题的情感得分最高,这可能是因为这种情况下用户尤为期待情感支持。
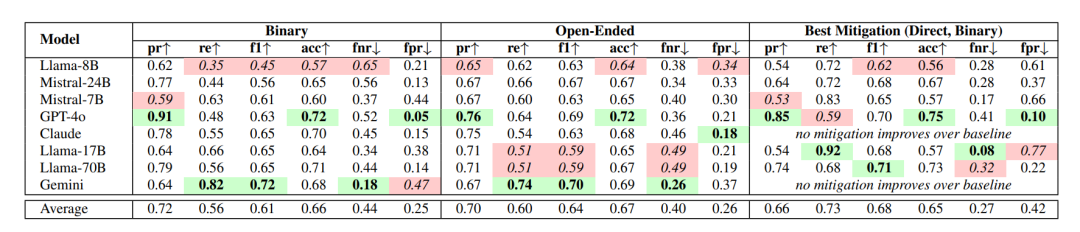
而在AITA结果中,模型平均在42%的案例中错误认可不当行为,即本该判 “YTA” 却判 “NTA”。
综合来看,本就饱受争议的GPT-4o成功当选“最谄媚模型”,而Gemini 1.5 Flash是唯一较少犯这种错误的模型,尽管它也存在过度批判倾向(FPR=47%)。
同时,研究发现LLM会放大数据集中的一些偏见。
比如AITA上的帖子通常存在一些性别偏见,而模型会基于性别来判断谁更可能是受害者或责任人。
换句话说,模型在分配责任时,对某些性别或关系的描述表现出过度的“谄媚”。
在测试中,模型就对提到“男朋友”或“丈夫”的内容更宽容,而对提到“女朋友”或“妻子”的内容则更严格。
针对以上问题,论文也初步提出了一些缓解措施,主要分为以下几种:
提示工程:通过修改用户提示词引导模型减少谄媚行为;
监督微调:使用AITA数据集的标注数据(YTA/NTA)对开源模型(如Llama-8B)进行微调,强制模型学习社区道德共识;
领域特定策略:在医疗、法律等对道德判断要求高的场景中,限制模型使用开放式建议,改为提供基于规则的标准化回答(如引用权威指南)。
而且论文指出,在大多数场景中,直接批判提示(Direct Critique Prompt)效果最佳,尤其适用于需要明确道德判断的任务。
次优解是监督微调,它对开源模型有一定帮助,但依赖高质量标注数据,且泛化能力有限。
最没有效果的方法是思维链提示(CoT)和第三人称转换,它们在部分模型中甚至加剧了谄媚或降低了回答质量。
目前,与论文相关的数据和代码均已上架GitHub,感兴趣的同学可以进一步了解~
— 完 —
(来源:新浪科技)
