自动驾驶技术竞争升级,VLA之后是什么?
文 | 极智GeeTech
2026年,自动驾驶行业的内卷逻辑,正在发生第三次重构。
短短数年间,行业快速走完了硬件堆砌竞赛、端到端算法博弈两个阶段,以小鹏、理想为代表的新势力车企和吉利、长城等传统车企扎堆入局VLA(视觉-语言-动作)模型,成为当前自动驾驶技术迭代的重要流派之一。
凭借“视觉感知+语言推理+动作输出”的三位一体架构,VLA解决了传统自动驾驶最大的痛点:看得懂路况,却不懂路况逻辑。但VLA的弊端也十分明显,依靠语言模型进行推理,就需要视觉到语言、语言到动作的两次翻译,而翻译就会导致误差,反应也更慢。
行业竞争的残酷性在于“刚追上主流,就迎来新迭代”。当一部分厂商还在打磨VLA量产落地、优化推理速度与场景泛化能力时,华为、小米等玩家却认为:VLA并不是自动驾驶的终极形态,只是从辅助驾驶走向全自动驾驶的过渡技术。真正的下半场竞争,早已瞄准VLA之后的下一代技术范式。

VLA如何重塑自动驾驶底层逻辑?
想要看懂VLA的局限与未来方向,首先要厘清自动驾驶十年三代技术范式的迭代逻辑,每一次迭代,都是对前一代技术短板的彻底颠覆。
第一代是规则驱动时代,也是最原始的自动驾驶形态。早期自动驾驶完全依托工程师手写百万行级C++代码,通过预设固定规则应对各类路况。系统的核心逻辑是“匹配规则、机械执行”,优点是稳定可控、可解释性强,缺点是极度僵化。面对未预设的突发场景、异形路况、混行交通,系统会直接决策失效,无法适配复杂真实路况,这也是早期辅助驾驶只能局限于高速巡航的核心原因。
第二代是端到端AI时代,以特斯拉FSD V12为标志性起点。行业彻底抛弃模块化拆分与人工规则堆砌,搭建“像素输入、动作输出”的全神经网络架构,通过海量真实路况数据训练,让AI自主学习行驶决策。这一代技术解决了传统规则算法僵化、迭代慢的问题,大幅提升了自动驾驶平顺度与场景适配性。但其也存在致命短板,只有感知能力,没有理解能力。AI能识别障碍物、车道线,却无法理解场景背后的逻辑,不懂交通常识,极易出现“识别到但误判、避险生硬、决策不合理”的问题。
第三代就是当下的VLA时代,也是近两年自动驾驶行业的主流形态。VLA在端到端视觉架构的基础上,加入自然语言推理能力,构建起“视觉感知世界、语言理解逻辑、动作输出决策”的完整闭环。不同于纯视觉端到端模型的“直觉式决策”,VLA可以像人类司机一样,先识别路况、再理解场景、最后制定行驶策略,完美适配城市复杂路口、人车混行、临时施工等高频复杂场景,让高阶无图智驾真正具备量产实用性。
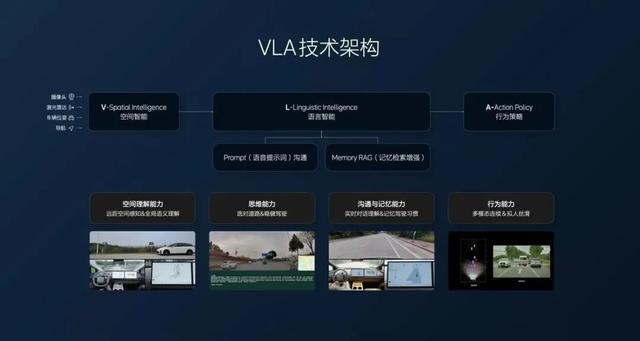
VLA本质上是一种端到端的智能系统,通过统一的神经网络将多模态感知与高层逻辑推理、底层动作执行融为一体。其核心价值是将原本相互独立的感知模块(看)、逻辑模块(想)与执行模块(做)在同一个语义空间内完成了对齐。与传统的自动驾驶系统相比,VLA不仅能够识别环境中的像素点或几何结构,更能理解这些信号背后的语义逻辑。
VLA模型由视觉编码器、大语言模型(LLM)骨干网络以及动作解码器三个核心组件构成。视觉编码器将摄像头采集的多视角图像转化为高维的特征向量,这些向量包含了环境的空间布局与物体特征;LLM骨干网络则作为决策中心,利用预训练过程中积累的海量世界知识对视觉特征进行逻辑加工;动作解码器则将这些抽象的推理结果转化为如转向角度、加减速数值等具体的物理动作。
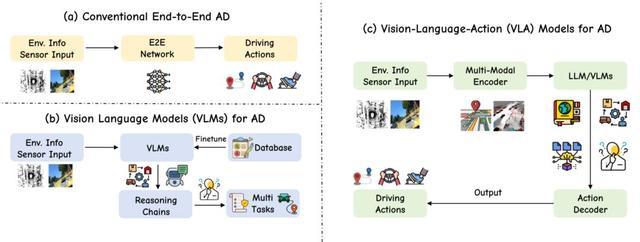
这种一体化的映射方式使得系统能够以一种更接近人类认知的方式来处理驾驶任务。在人类驾驶过程中,大脑并不会先在意识里标出每一个行人的精确坐标再进行计算,而是基于对场景的整体理解(如“这个行人可能要过马路”)直接产生避让动作。VLA模型通过共享的Transformer架构,对语言、视觉和动作模态进行协同编码,构建了统一的语义空间,实现了从感知理解到动作决策的无缝衔接。
经过三年迭代,VLA已经彻底改写行业格局,抹平了中小厂商的算法差距。如今主流车企的VLA,在常规城市道路、高速路况的表现已经趋于同质化,日常通行平顺度、场景覆盖率差距极小。同质化内卷的背后,意味着VLA的技术红利已经见顶,行业亟需新的技术突破点。
看似完美封神,VLA四大瓶颈已现
目前舆论普遍将VLA视为自动驾驶的最优解,但在一线技术团队与行业专家眼中,VLA从诞生之初就自带结构性缺陷,这些短板无法通过模型微调、数据增量、算力升级彻底解决,也是其注定只能成为过渡技术的核心原因。
首先是时序逻辑缺失,空间场景推理能力薄弱。当前多数VLA模型擅长单帧、瞬时路况分析,对车流变化、行人移动轨迹、多车交互的连续时序逻辑预判不足。面对鬼探头、近距离穿插、车流突发变道等高速动态场景,以及车辆在具体空间里的运动,VLA缺乏灵敏感知能力,经常出现决策滞后、预判失误,无法实现人类司机的“提前预判、主动避险”
其次是算力成本高,实时性难以适配车载场景。VLA融合视觉、语言、动作三大模块,模型参数量庞大,推理计算量远超传统端到端算法。车载电控系统要求决策响应速度达到100Hz,而通用VLA语言推理速度普遍不足10Hz,巨大的算力差导致模型必须大幅精简才能上车。即便部分厂商通过优化推理链路,将时延压缩至80毫秒以内,依旧无法彻底解决智能化程度与速度不可兼得的矛盾,高算力成本也大幅抬高了高阶自动驾驶的量产门槛。
第三是缺乏物理世界常识,长尾场景泛化能力失效。VLA的学习逻辑依托海量数据拟合,而非真正理解物理规律。它可以通过训练学会避让常规障碍物,却无法自主推理“路面积水易打滑需要减速”“树枝悬空可能掉落需要绕行”“雨雪天路面摩擦力下降需延长制动距离”等物理常识。对于这类稀缺长尾场景,数据无法完全覆盖,VLA极易出现决策失误,而自动驾驶的安全底线,恰恰由这些长尾极端场景决定。
最后是跨模态对齐偏差,决策稳定性不足。视觉、语言、动作三大模块存在天然的链路损耗,视觉感知偏差、语言推理误差、动作输出偏差会层层叠加。在逆光、浓雾、暗光等视觉受限场景,VLA会出现语义理解与实际路况脱节的问题,出现“识别正确、理解错误、动作偏差”的诡异决策,轻则行驶顿挫、路线偏移,重则引发安全事故,这也是纯视觉VLA方案的先天物理短板。
综上来看,VLA虽然解决了自动驾驶的智能化问题,却没解决安全性、实时性、通用性问题,这也是行业必须突破VLA、探索下一代技术的核心动因。
下一代自动驾驶核心技术方向
站在2026年的技术节点,头部厂商朝着跳出VLA的模态融合思维,转向物理世界智能建模的方向发展。VLA的核心是看懂、读懂、动作,而下一代自动驾驶技术,核心是懂规律、会推演、能预判,目前行业已明确四大主流迭代方向。
其一,多模态物理世界模型,成为下一代技术核心底座。世界模型是彻底解决VLA物理常识缺失的最优解,也是特斯拉、华为重点攻坚的核心方向。不同于VLA依托数据拟合场景,世界模型会自主学习现实世界的物理规则、交通规律、运动逻辑,构建完整的虚拟路况世界。面对从未见过的长尾场景,无需海量数据训练,就能依托物理常识自主推演最优决策,真正实现“举一反三”。简单来说,VLA是见过才会,世界模型是懂原理所以会,从根本上解决长尾场景失效的行业难题,是全自动驾驶落地的核心基础。
其二,时序具身智能架构,补齐动态决策短板。针对VLA时序推理薄弱的缺陷,下一代技术将彻底强化连续场景建模能力,摒弃单帧静态推理模式,搭建时序记忆与动态推演体系。系统可以实时记录过往路况信息、预判未来3-5秒车流与人流动态变化,实现“过去-现在-未来”的全时序链路决策,贴合人类司机的驾驶思维,彻底解决高速动态避险、复杂车流交互、路口多主体博弈的决策难题,大幅提升高速、城市拥堵场景的行驶安全性与平顺度。
其三,神经符号融合,平衡智能度与可解释性。当前VLA属于纯黑盒AI模型,决策逻辑不可解释,存在安全监管隐患,也难以满足自动驾驶合规落地要求。下一代神经符号融合技术,将AI深度学习的直觉优势与符号逻辑的规则优势结合,AI负责实时场景感知与快速决策,符号逻辑负责交通规则、物理常识、安全底线的约束校验。既保留了大模型的极致智能,又解决了黑盒决策的不可控问题,让每一次制动、变道、绕行都有逻辑可循,适配高阶自动驾驶的安全合规要求。
其四,轻量化通用自动驾驶基座,实现普惠量产。VLA算力成本过高的问题,极大限制了高阶自动驾驶的普及。下一代技术将依托模型蒸馏、算子优化、边缘计算重构,打造轻量化通用自动驾驶基座,在保留顶级决策能力的前提下,将算力需求大幅压缩,摆脱对超高算力硬件的依赖。同时适配多传感器融合架构,以视觉为主、雷达为辅,兼顾低成本与高安全冗余,彻底解决高阶自动驾驶只能搭载高端车型的痛点,推动全自动驾驶全面下沉至中端量产车型。
新一轮技术差距正在拉开
技术迭代的窗口期永远短暂,目前国内外头部厂商已经开启下一代技术竞速,提前布局VLA之后的技术赛道,新一轮行业排位赛已然开启。
特斯拉作为行业技术风向标,正在推进端到端时序神经网络融合神经世界模拟器,核心推理仍以端到端为主、云端闭环仿真为辅。与VLA不同,特斯拉未引入大语言模型用作语义推理,而是坚持“纯视觉端到端+物理仿真训练”路线。
FSD采用“多模态(摄像头+IMU+导航+音频)输入 → 时序Transformer/占用网络 → 直接输出控制信号”的一段式端到端架构,并非传统“感知-规划-控制”级联,该结构具备时序建模能力,可视为“端到端时序网络”。神经世界模拟器(Neural World Simulator)则用于云端生成未来状态(给定当前状态+动作 → 预测下一帧场景),支撑闭环训练、长尾场景合成与强化学习。
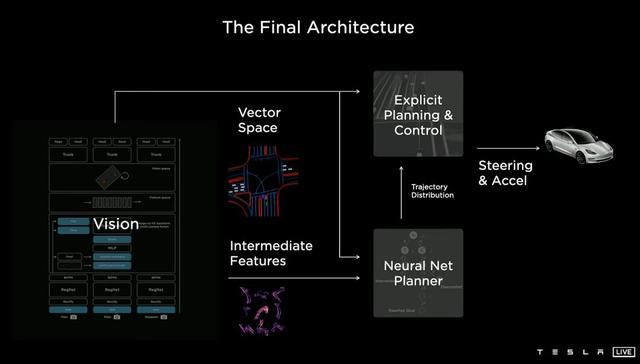
华为于4月推出WEWA 2.0架构,包含云端的世界引擎(WE)与车端的世界行为模型(WA)两大核心部分。在云端引入了多智能体博弈机制与在线强化学习,该机制使模型能与环境实时交互,实现“边生成、边学习、边验证”的工作方式。在车端,架构以安全风险场理论和Driving Agent模块为核心,通过量化动能场、势能场与行为场来评估实时风险,并生成风险热力图辅助决策。Driving Agent模块支持系统自行优化策略以完成出行任务 ,能够提升在复杂场景下的应对能力与防御性驾驶能力。
小鹏、理想则聚焦量产落地优化,走出差异化迭代路线。小鹏汽车在第二代VLA上做出了较为激进的选择——去语言层。小鹏第二代VLA采用“视觉→隐式Token→动作”的架构,彻底抛弃显式语言转译,让视觉信号直接生成连续的驾驶动作,极致压缩推理时延,同时布局虚实结合数据闭环,通过虚拟场景训练补足长尾场景短板。理想推出Mind VLA-01全新架构,针对性解决VLA三维空间对齐偏差问题,强化异形路况、复杂地库场景的适配能力,同时推进模型轻量化,主打极致量产性价比。
小米汽车于3月发布XLA认知大模型,在模态支持、效率与可控性方面有所侧重,其名称中的“X”意指原生支持多模态数据输入,可融合激光雷达、视觉、导航、声音及机器人数据等。XLA采用潜空间推理技术,旨在兼顾系统低时延与推理能力,并保持推理过程的可解释性与可追溯性。其基于Xiaomi MiMo-Embodied具身基座大模型研发,融合了VLA和世界模型架构,实现了从数据驱动到认知驱动的升级,并因其原生支持更丰富的多模态数据输入而命名为XLA而非VLA。
自动驾驶企业阵营方面,小马智行PonyWorld 2.0、文远知行通用仿真模型WeRide GENESIS、蘑菇车联物理世界多模态大模型MogoMind均属于世界模型范畴。世界模型本质上是一套“理解物理世界、在虚拟环境里与世界博弈”的能力框架,其核心能力主要有两个方面:一是对物理世界的数字化建模和抽象;二是基于这样的建模,产生对物理世界合理的想象和预测,例如通过给定的图片预测未来世界将会如何变化。
基于世界模型,自动驾驶企业在进行云端仿真训练时,可以无限制从各个维度生成所需场景,能够根据指令生成视频作为训练数据,模型迭代速度呈现断代式领先。在无人驾驶上成熟落地之后,世界模型有机会进一步探索其他物理AI应用,比如复杂机器人控制、自动化物流系统等。
整体来看,行业格局已经清晰:二线厂商还在全力落地VLA、追赶主流;一线头部厂商已经完成VLA技术吃透,提前布局下一代世界模型与具身智能。未来两年,车企的自动驾驶能力差距将不再由VLA能力决定,而是由下一代物理智能技术的落地速度决定。
VLA之后,自动驾驶迎来全民普惠时代
从规则算法到端到端,从VLA大模型到物理世界智能,自动驾驶的迭代逻辑始终清晰:降低人工依赖、提升通用能力、缩小人机差距。VLA作为关键过渡技术,承载了自动驾驶从“机械辅助”到“类人智能”的跨越,但其结构性短板注定无法支撑L4级完全自动驾驶落地。
未来2-3年,随着VLA、世界模型的进一步发展,自动驾驶将迎来三大颠覆性变化:
第一,安全兜底能力质变,解决长尾极端场景失效问题,真正实现全天候、全场景可靠行驶,消除自动驾驶核心安全隐患。
第二,彻底摆脱数据依赖,无需海量场景覆盖,依托物理常识自主适配各类未知路况,解决不同城市、不同路况的适配难题。
第三,成本大幅下探,轻量化模型架构降低硬件门槛,高阶全自动驾驶将从高端豪车标配,下沉至十几万家用车型,实现全民普惠。
与此同时,行业竞争将彻底告别“参数内卷、功能堆砌”,回归核心的物理建模能力、时序推理能力、安全可控能力。单纯跟风堆叠大模型、复刻VLA功能的厂商,将逐步被市场淘汰,只有真正掌握底层核心算法与物理智能技术的企业,才有可能拿到通往下一站的船票。
任何技术赛道,都没有永恒的技术红利,只有持续的底层革新。VLA的普及,让行业摆脱了低级的硬件、规则内卷,真正迈入AI智驾时代。而VLA之后,自动驾驶将不再只是“会开车的机器”,而是懂路况、懂物理、懂规则、能预判的车载智能体。这一轮迭代,早已超越算法本身,而是自动驾驶从“为人所用”到“与人共生”的终极跨越。
(来源:新浪科技)

