智谱GLM-5V-Turbo“擦枪走火”,国产多模态智能体战争一触即发
在国产大模型的激烈竞争中,智谱的GLM系列一直掌握着一张极具商业价值的王牌:极强的代码能力。
随着AI的主要形式从大语言模型转向智能体,行业竞争进入下半场,开发者和开发生态是付费意愿最强的群体。
但是,行业巨头们对AI的期许显然不仅仅是一个“外包的程序员”,只有成为一个能真正接管系统工作流的全能型智能体,才能让AI进入每个普通人的生活。
因此,一个强大的AI只会敲键盘还远远不够,它必须长出眼睛,去审视网页排版、看懂海报图表、甚至要理解GUI上各种非文本的复杂信息。
前几天,DeepSeek灰度测试“识图模式”已经打响了第一枪。
如今,智谱也紧紧跟随,正式开启了多模态领域的全新探索。在最新模型GLM-5V-Turbo的技术报告中,我们可以清晰地认识到,这是智谱向原生多模态智能体发起的新一轮冲锋,也是一份充满技术暴力、工程妥协和商业考量的自白书。
01
视觉底座的暴力美学与微操艺术
向大语言模型中增加视觉能力,这个思路在过去几年中早已被频繁尝试。
然而,由此诞生的视觉语言模型(VLM)往往只是个拼接而成的产物,语言模型是绝对的大脑,视觉模块只是一个外挂摄像头。
也就是说,模型压根无法理解图像等信息中蕴含的逻辑。把二维的视觉信号强行压缩至一维的token序列,带来的结果就会是看不懂图像、忽略关键细节甚至产生严重的幻觉,自然也无法作为智能体使用。
因此,GLM-5V-Turbo在开篇就定下了基调:
多模态感知绝对不能只是一个辅助接口,它必须成为模型推理、规划、工具调用和任务执行的原生核心组件。
因此,为了实现真正的“原生”,智谱这次在底层架构上动了三次大手术:
1.重构视觉底座:专为Agent而生的CogViT
智能体需要操控用户的电脑,因此在图形用户界面中,模型不仅要知道图片里有什么,还要关注各种容易被忽视的细节,哪怕一个长宽可能只有几个像素的按钮。
为此,智谱自研了一套高参数效率的视觉编码器CogViT,并采用两阶段的预训练:
第一阶段是特征重构,两个教师模型中,SigLIP2负责让模型识别语义,DINOv3负责让模型识别纹理,最后通过掩码图像建模增强模型视觉特征的表达;
第二阶段是图文对齐,通过引入NaFlex方案来处理动态分辨率,将全局的Batch Size直接提升至64K。
这种设计方式直接将智谱新模型的空间感知和几何理解能力拉满,也为后续操控网页和手机UI打下了基石。
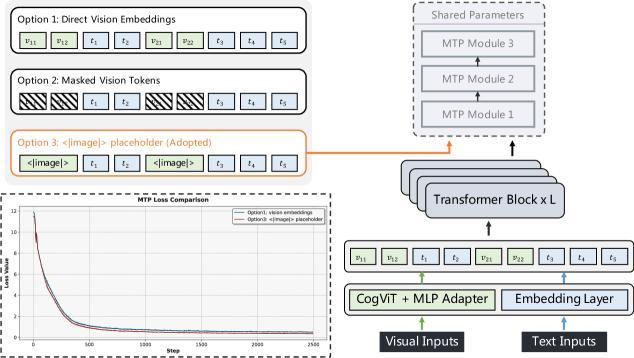
2.工程与算法的平衡:多模态多Token预测(MMTP)
多模态能力的引入,必然伴随着显存和算力消耗的指数级膨胀。
关注AI领域的开发者应该都知道,智谱近半年来算力储备并不宽裕,此前引发激烈讨论的价格调整已经侧面印证了在大规模推理面前,算力成本就是一个黑洞。
引入多Token预测(MTP)以提升推理效率是业内普遍使用的做法,不过智谱在引入MTP时,采用了一个教科书级别的工程决策:
直接把包含大量信息的视觉特征直接传给MTP预测头不可行,那就采用一个共享的特殊token“<|image|>”作为视觉输入的占位符。
看似简单的改动,其实最符合“工程实用主义”。它大幅降低了流水线并行中的通信复杂度,直接避免了显存爆炸这个让人头疼的问题。
除此之外,在保证模型收敛稳定的前提下,这个“巧思”还能极大降低训练和推理的算力成本。
3.破除长尾魔咒:超大规模多模态强化学习系统
目前,智能体的训练思路与大语言模型本质上并无区别,使用的仍然是强化学习。
但是,在智能体的训练过程中,单任务强化学习很容易让模型陷入震荡。
而智谱的研究团队发现,多任务协同强化学习能够让模型见识到更丰富的策略分布,甚至出现跨任务的思维模式迁移。
因此,智谱在超过30个任务类别上进行了联合强化学习,并在基础设施上实现全流水线解耦和异步执行。他们不仅将视觉切分这个环节从前向传播阶段提前至数据加载阶段,还对GPU之间的通信做出了极致的内存管理。
02
从API分发到工作流接管的范式转移
技术的底层重构,最终指向的永远是商业变现逻辑的跃迁。
GLM-5V-Turbo展现出的多模态深度研究能力,正在预示着智谱AI应用的两点商业变局:
一是用多模态深度研究打破传统文本SaaS的壁垒。
对于此前大部分AI助手,大多只能阅读纯文本内容。即便是允许用户上传图片、视频、PDF等附件,一旦其中包含的非文本信息过多,AI的识别能力就会断崖式下降。
然而,GLM-5V-Turbo能够自主循环执行“规划→多模态阅读→状态更新”这套工作流,直接解析各种图表、文档、PPT中的高价值视觉信息,直接交付Markdown商业报告和高度结构化的幻灯片。

在这一点上,智谱的路线与昨天发布Claude for Microsoft 365、单刀直入杀进微软生态的Anthropic几乎完全相同。
因此,传统的信息检索工具必然会面临降维打击。当AI能够端到端交付包含数据可视化的成品报告时,按token计费的模式也会逐渐走向“按交付项目计费”的商业模式。
二是Agent终极形态将会是模型(Model)与载具(Harness)的共生。
智谱的技术报告中给出了一个很有启发性的观点:
系统的能力边界不再由模型单方面决定,而是由模型与它周围的框架(Harness)共同塑造的。
作为国产模型的领头羊之一,智谱官方也在不断提供更为丰富的工具链(Official Skills),并且与行业标准框架Claude Code和Auto Claw均实现了无缝集成。
事实上,智谱早已清晰地认知到,单靠自己一家AI初创公司几乎不可能创造出像Google一般的强大生态。与其孤注一掷,不如让Claude Code和AutoClaw这些善于处理终端和文件逻辑的全球通用工具成为自己操作计算机的灵巧手。
此前人们期待的“全能大模型”神话,如今已经接近破灭,强如OpenAI也无法仅靠大语言模型实现AGI。未来的护城河必将转移到模型能力与外部工具的深度耦合。
毕竟,作为付费主力的B端企业从来都不需要一个什么都能聊的机器人,而是需要一台能够直接无缝融合进已有系统的认知驱动引擎。
03
血泪史:智能体研发的三条定律
智谱的这次技术报告发布之所以与众不同,是因为研究团队在报告末尾非常罕见且坦诚地分享了他们在研发过程中总结的设计视角。
这份用无数算力和通宵加班换来的“避坑指南”,远比开源的模型和技术要宝贵,而且对整个AI行业来说都有极高的价值。
首先,千万不要好高骛远,底层感知才是决定模型天花板的基石。
最近一年来,AI行业逐渐形成了一种风气,所有产品发布时总会带上“深度思考”、“自我反思”、“长逻辑规划”这些标签,仿佛只有贴上这些标签的才是高级的AI。
然而,在用户的反馈中其实不难发现,这些高大上的标签并没有在具体的应用场景中得到落实。
智谱在实践中发现,很多看似高级的规划最终失败,并不是过程中细枝末节的错误积少成多,而是模型在第一步就开始“盲人摸象”。或是没看清细微的UI元素,或是搞错了按钮的空间位置。
智能体的运作逻辑与大语言模型截然不同,视觉感知绝非一个前期处理完就可以丢在一边的低级模块,它持续制约着模型高级推理能力的上限。
其次,面对智能体的训练,应当放弃对“端到端”的迷信,主动拥抱分层优化。
这并非否认“训练智能体应该使用智能体(而非大语言模型)强化学习”的论断,但AI企业也必须面对目前训练智能体成本高昂、高质量轨迹数据稀缺、评测标准缺少行业规范的现实。
一上来就让模型学习极其复杂的长周期任务,带来的结果要么是“只得其形未得其意”,要么是模型直接崩溃。
智谱的做法是把任务如庖丁解牛般细细切碎,从最底层的认清图标,到单步动作预测,再到整条行为轨迹规划,进行分层优化。事实证明,这不仅是算力有限时不得不做出的妥协,更是让模型稳定收敛的最佳途径之一。
最后,那些不能被精准评估的任务,没有参考意义。
对于当前具备多模态能力的智能体来说,最难的并不是让它干活,而是不知道如何客观地“打分”。
相比网页中的对话框,真实的计算机环境中充满了开放性和不确定性。智谱意识到,只有设计出具有严格的步骤控制、能隔离不同维度的信号的验证流程,这种端到端的评测才会有意义,才能反向指导模型的迭代过程。
04
结语
看完智谱的这份技术报告,与其说是一次模型能力的展示与讲解,不如说是研究团队与用户的一次隔空座谈会。
这份报告没有把自己的模型描绘得十全十美,反而在最后抛出了几个直击灵魂的行业未解之谜:
视频和图像都是吃内存的怪物,在朝长周期的任务中应该如何实现上下文压缩记忆?
模型什么时候才能摆脱人类投喂标准答案,自己涌现出更聪明的交互策略?
这些问题,一时半会还没人能够回答。
我们能看到的,只有一个正在快速进化的国产模型,以及整个AI行业正在步入艰难的深水区的现实。
增加多模态能力是智谱向全栈智能体进军的必经之路,但路上的算力账单早已无处不在。在算力紧缺的客观现实下,智谱还是用精妙的架构设计、极端的显存优化和分层的训练策略,硬生生打出了一场令人称赞的资源突围之战。
GLM-5V-Turbo已经证明它有能力接管用户的电脑屏幕,而下一个考验,是整个市场是否准备好了为“原生多模态”的生产力买单。
(来源:新浪科技)
关联资讯:


Anthropic发布Managed Agents,才发现这支硅谷华人团队早就押对了赌注 – 量子位

【数智周报】豆包大模型2.0发布;智谱GLM-5已深度适配华为昇腾等国产芯片;Anthropic宣布300亿美元融资,估值达3800亿美元; 欧盟批准谷歌320亿美元收购Wiz

【钛晨报】推动低空保险高质量发展,国家发改委等三部门发声;国家电影局、商务部组织开展“电影+”消费综合试点;智谱GLM-5深度适配华为昇腾、摩尔线程、寒武纪等七大国产芯片

