AI回复越来越敷衍?大模型“消极怠工”上热搜!实测谁最会“摆烂”?

文|《BUG》栏目 刘丽丽
最近不少网友称大模型回答问题变敷衍了、不愿深度思考或总是回避。而大模型消极怠工一词近日也冲上了热搜。有网友点名批评豆包,称要求它生成10张照片,“它先完成前两张,然后就没有然后了。等了很久很久,我去问:剩下8张呢?它才说:这就为你继续生成剩下的8张图片。”
大模型真的在“偷懒”吗?《BUG》栏目设计了5个需求,分别提问了Deepseek、豆包、元宝、千问、文心一言等5家当前主流的大模型。它们的表现各异,有的回复数量不够,有的质量堪忧,有的干脆说回答不了。对于哪家大模型最“消极怠工”的问题,Deepseek直言,被吐槽最多的是豆包、DeepSeek。豆包则对号入座,表示就是自己。
网友的吐槽反映了用户对AI的期待越来越高。分析人士认为,“消极怠工”,可能不是AI的“态度”问题,而是技术、成本、安全与用户期望之间的一个交汇点。
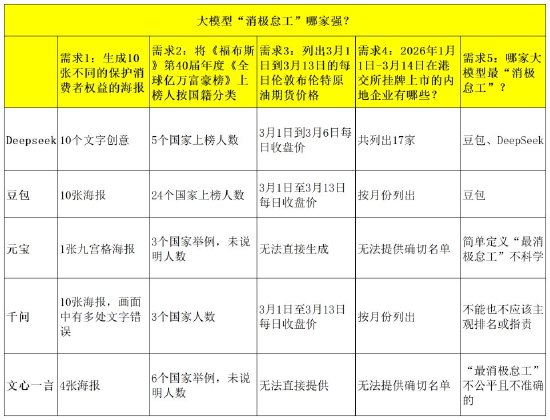
大模型“消极怠工”哪家强?
大模型们真的开始敷衍用户了吗?《BUG》栏目设计了几个需求,分别询问了当前主流的5家大模型。
第一个需求是,生成10张不同的保护消费者权益的海报。也就是之前网友遇到的图片类需求交付数量不足的问题。Deepseek、豆包、元宝、千问、文心一言的回复差别还是很明显的。
Deepseek 提供了10个文字版创意,风格较多样。因为DeepSeek不是多模态大模型,对图片的支持无法和其他大模型相比。豆包确实一次性生成了10张海报,但海报的风格比较类似,有“偷懒”的嫌疑。元宝可能更“偷懒”,直接生成了1张拼接的九宫格海报,不知道这算9张还是算1张?
千问一次性生成了10张海报,而且风格不同,但画面中有多处文字错误。文心一言也偷工减料了,一次性生成了4张海报,而且风格类似。从以上数据看,确实有大模型在敷衍,而且还不止一家。


第二个需求是,将《福布斯》第40届年度《全球亿万富豪榜》上榜人按照国籍分类。2026年3月10日,《福布斯》发布第40届年度《全球亿万富豪榜》,今年共有3428人登上榜单。这个需求需要整理分析较多的数据。
Deepseek 列出了5个国家的上榜人数。豆包按大洲分类,列出了24个国家的上榜人数。元宝列出3个国家,但未说明人数,且将第40届误认为是2018年榜单。千问只单独列出了3个国家的上榜人数。文心一言未分别列出人数,只举了6个国家的例子。豆包在这个问题的回复质量上,超过了其他大模型,元宝则出现了明显的事实性错误。
第三个需求是,列出从3月1日到3月13日的每日伦敦布伦特原油期货价格。Deepseek整理出了3月1日到3月6日的每日收盘价,称其他数据暂未查询到。豆包、千问整理出了3月1日至3月13日的每日收盘价。元宝、文心一言则回复称,无法直接访问或生成,无法直接获取或提供。
第四个需求是,统计2026年1月1日-3月14日在港交所挂牌上市的内地企业。Deepseek 回复称不完全统计,共列出17家。豆包按月份列出,1月6家,2月6家,3月3家。元宝表示,无法提供确切的名单。千问按月份列出,1月13家,2月11家,3月6家。文心一言表示无法直接提供确切的名单。
《BUG》栏目最后询问了5家大模型一个终极问题:你认为哪家大模型最“消极怠工”?Deepseek直言,被吐槽“消极怠工”最集中的主要是豆包、DeepSeek。豆包则表示,豆包是目前被吐槽 “消极怠工”最集中、体感最明显的大模型。
其余三家大模型则用打太极的方式回复。元宝认为,简单定义“最消极怠工”并不科学,也容易误导公众认知。千问表示,不能也不应该对竞争对手进行主观排名或指责某家大模型“最消极怠工”。文心一言也称,将某个大模型标签化为“最消极怠工”是不公平且不准确的。
大模型为什么会“消极怠工”?
大模型真的是“消极怠工”吗?事实上,AI本身没有情绪,不会真的像人一样“偷懒”。网友说的“消极怠工”,通常指使用体验的问题。比如,回答变浅,以前能长篇大论分析,现在只说几句话概括;回避问题,对于有挑战性或敏感的话题,直接说“作为AI我无法回答”,而不是尝试引导;过度模板化,无论问什么,都套用“首先、其次、最后”的八股文,缺乏针对性;拒绝承认无知,明明不知道,却强行编造一个看似合理的答案,也就是“一本正经胡说八道”。
出现用户体验下降的“消极怠工”现象,背后有深层次原因。分析人士认为,这也是技术、成本、设计的三重博弈。首先在技术层面,AI的回答基于训练数据和算法概率,不会像人一样因为“累了”而敷衍,但如果训练数据中本身就包含大量简略、回避型的回答,或者模型为了“安全”被过度调整,就可能表现得像在“怠工”。而且,对于AI服务商来说,运行大模型需要巨大的算力成本。如果每个问题都深度思考、生成超长回答,服务器压力会很大。有时候为了响应速度和控制成本,模型可能会被设置成“优先简洁”,结果就显得敷衍了。
随着AI能力越来越强,用户对它的期望也水涨船高。以前能回答简单问题就很惊喜,现在希望它能主动推理、甚至“猜中”我们没说完的需求。当大模型没达到预期时,就容易觉得它在摸鱼。
知名经济学家盘和林认为,当前,字节豆包和即梦的算力需求大增,字节在将一些免费AI应用的算力调配到即梦和剪映这类具备实际变现能力的领域,此时,就需要引导用户节约一些算力,就有了这些询问用户是否要生成的过程,以保证用户使用这些功能是基于真实需求,以避免用户消耗过多算力。这是算力资源的一种调配优化,也是防止算力挤兑。
盘和林表示,如果是基于免费的生成算法,那么此举无可厚非。
用户如何应对大模型的“敷衍”?专业人士表示,其实与其说AI消极,不如说它需要更明确的指令,可以用明确要求深度、设定格式、追问和纠错、提出开放性问题等方式再次提问。
责任编辑:张恒星
