智谱与Minimax交出“大招”之后,DeepSeek“平A”了一下
谁能想到,仅仅一个晚上,国内三大AI巨头接连发布了自己的新模型?
DeepSeek、智谱和MiniMax无缝衔接上演了这出好戏,AI爱好者们在这个春节可是有的忙了。
在算力紧缺、同质化加剧的当下,国产大模型逐渐走上差异化的路径:
有人押注超长文本的记忆边界,有人攻坚智能体的工程化落地,也有人选择以轻量和效率闯进企业级市场。
01 DeepSeek:百万级上下文定义长文本处理边界
首先是产品端沉寂已久但全球万众瞩目的DeepSeek悄悄在官网和移动端开启了新模型的灰度测试。
尽管官方尚未发布正式技术文档,但社区普遍推测该模型可能是即将发布的DeepSeek-V4-Lite版本。
根据目前流传的消息,该模型的参数规模可能只有200B左右,且并未使用DeepSeek与北大联合研发的Engram条件记忆机制。
不过,我们仍然可以在简单的实测中发现新版本的核心突破:100万(1M)token的超长上下文窗口。

这一参数已经远超前代版本以及部分国内主流大模型32K-128K的限制,单次交互可以处理相当于500页A4文档的文本量,能够处理长文档分析、跨章节推理等生活中频繁应用的场景。
超长上下文的实证检验:大海捞针
“大海捞针”测试是AI界评估长文本能力的行业标准方法之一,通过在超长文本中随机插入特定信息,要求模型精准定位并回答相关问题,以此检验上下文窗口的实际有效性。
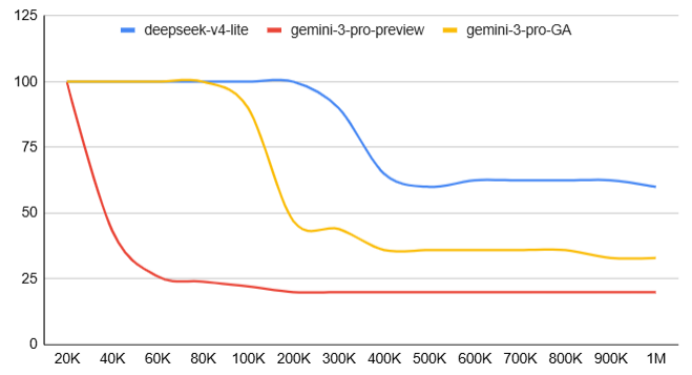
根据技术社区的测试结果,DeepSeek的新模型在100万token长度下仍然能够保持60%以上的准确率,准确率曲线在20万token以内近乎水平,此后才开始出现较为平缓的衰减,优于同期测试的Gemini系列模型。
若上述测试结果真实可靠,则表明DeepSeek的新模型不仅确实支持百万级上下文,还具备较高水平的有效上下文利用率。模型能够真正理解并利用超长文本中的信息,而不仅仅是技术层面上的信息接收。
在技术社区中,还有一位测试者的结果进一步佐证了这一强大能力。
该测试者将自创世界观设定集的30个Markdown文件一次性上传给DeepSeek,约57万字节,折合19-28.5万token,随后提出涉及人物背景、物品来源、据点描述等五类细节问题。
模型对稀疏信息能够准确定位并还原上下文,即使出现频次极低的角色也从未遗漏。因此,在20万token量级的实际文档处理中,DeepSeek的新模型已经展现出可靠的细粒度信息检索能力。
能力边界:专注文本赛道
在经典的“鹈鹕骑自行车”测试中,DeepSeek输出的矢量图形出现了结构混乱与几何失真的现象。
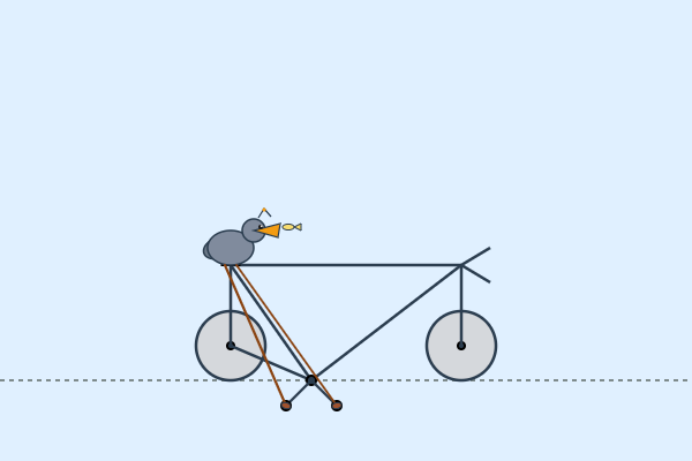
这一测试要求模型在零样本的情况下生成稀有组合场景的SVG图像代码,检验模型对结构化语言的精确控制能力。
而结果表明,模型在涉及几何坐标、空间关系的代码生成任务上存在局限。
这个结果与DeepSeek的技术定位直接相关,并不出人意料:和前代版本一样,新模型延续了纯文本模型的定位,研发重心都放在了百万token级上下文的文本建模和信息压缩,而非跨模态的视觉结构推理或精确代码生成。
事实上,在算力资源有限的约束下,放弃对SVG等结构化图形语言的优化,转而加强长文本处理能力,正好符合国产AI“重在应用”的发展方向,并有助于形成差异化技术路径。
DeepSeek的新模型在这项测试中体现出的不足并非能力缺陷,而是资源分配的必然取舍。
最后,根据技术社区和社媒平台流传的相关消息,DeepSeek可能还有一个参数规模突破1T的超大模型正在训练中,虽然大概率不会在2月发布,但多模态功能可能会得以落实。
02 智谱:智能体工程化与算力紧缺的事实
如果说DeepSeek放出来的轻量级模型是一次平A,那么紧随其后发布GLM-5的智谱就是实打实放出了大招。
GLM-5的发布其实并不意外,几天前pony-alpha的出现以及技术架构的前瞻(GLM-5架构细节浮出水面:DeepSeek仍是绕不开的门槛)都表明智谱已做好推出新产品的准备。
不过,在官方的发布公告中有一个很让人好奇的观点:智谱将其技术叙事从“Vibe Coding”(氛围编程)推向了“Agentic Engineering”(智能体工程化)。
文字意义上,这一转变表明智谱的大模型能力正在开始迁移:从过去的生成代码片段和前端Demo,到完成端到端的复杂系统性工程任务。
接下来,我们一起来看看GLM-5的实际能力如何。
可靠性的飞跃
首先是Artificial Analysis的评测榜单:
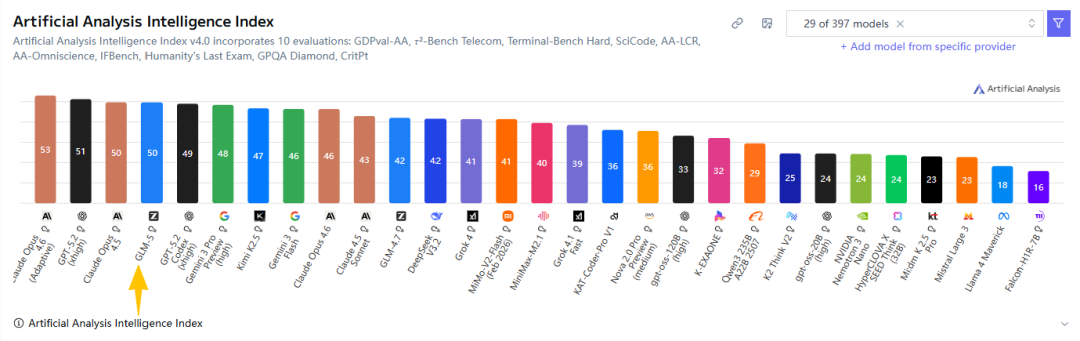
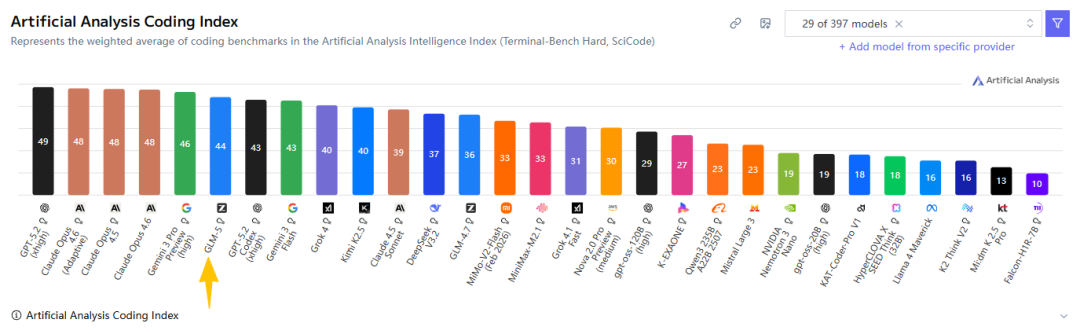
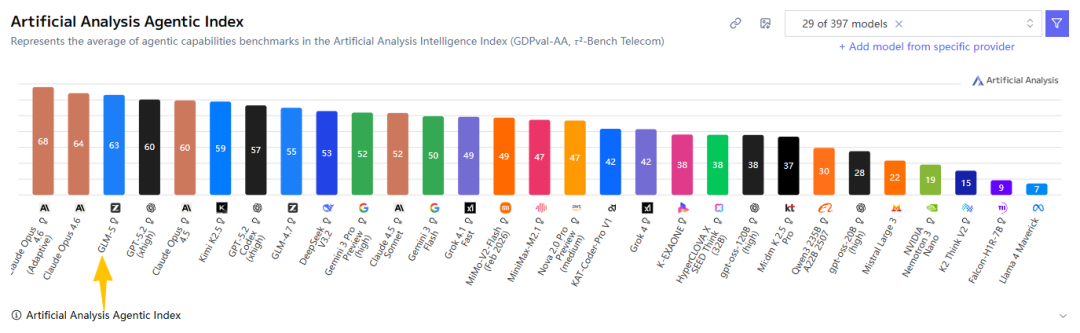
智能程度全球第4,编程能力全球第6,代理能力全球第3的开源模型!
说实话,刚看到这个榜单的时候我都有些被吓到了。
这还是我第一次看到国产模型凭借全方位的强大能力位列排行榜如此靠前的位置,而且与Gemini、GPT、Claude等世界顶级闭源模型的差距只在毫厘之间,证明智谱宏大的技术叙事绝非空口无凭。
根据官方发布的数据,GLM-5的参数规模总量为744B,激活参数为40B,相比前代模型GLM-4.7参数规模翻了一倍以上,预训练数据也从23T增加至28.5T。
Scaling Law仍在发挥作用,更多的参数和数据为GLM-5在复杂任务处理中提供了更坚实的语义基础。
技术层面和先前文章中分析的基本一致,模型首次集成了DeepSeek的稀疏注意力机制(DSA),在维持长文本处理效果的同时追求更高效率,显著降低了部署成本。
同时,GLM-5还引入了自研的Slime异步强化学习框架,使模型能够在与用户的长期交互中持续学习知识,提升任务规划的连贯性和稳定性。不过,智谱尚未发布这一技术的论文,待发布后会进行进一步解读。
更关键的技术突破在于可靠性指标的飞跃:在AA-Omniscience幻觉率测试中,GLM-5将幻觉率从前代版本GLM-4.7的90%直接压缩至34%,打破Claude 4.5 Sonnet的纪录成功登顶。
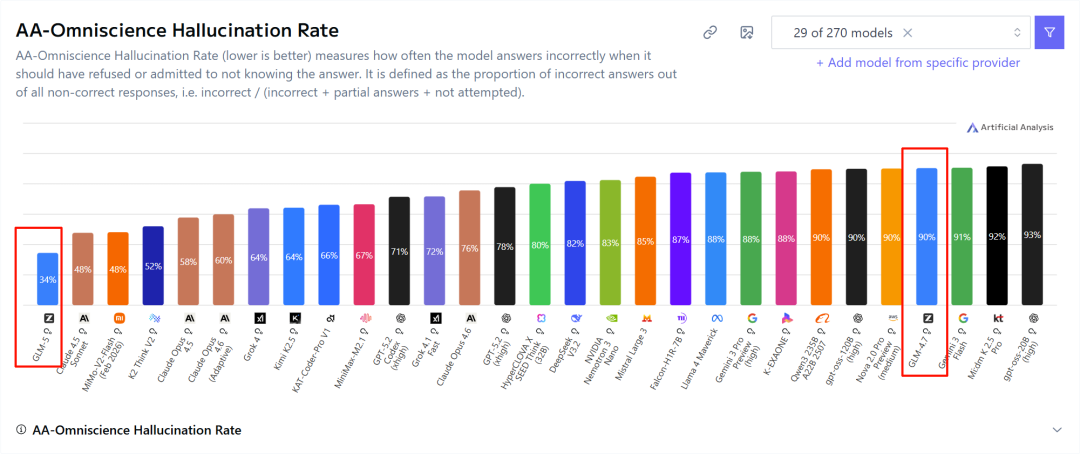
频繁产生幻觉的模型,不可能胜任系统化的复杂任务。GLM-5在生成事实性内容的时候明显更加谨慎,大幅降低了用户最抵触的编造信息风险,这也为智谱宣称的“智能体工程化”落地提供了必要的保证。
编程与代理能力的检验
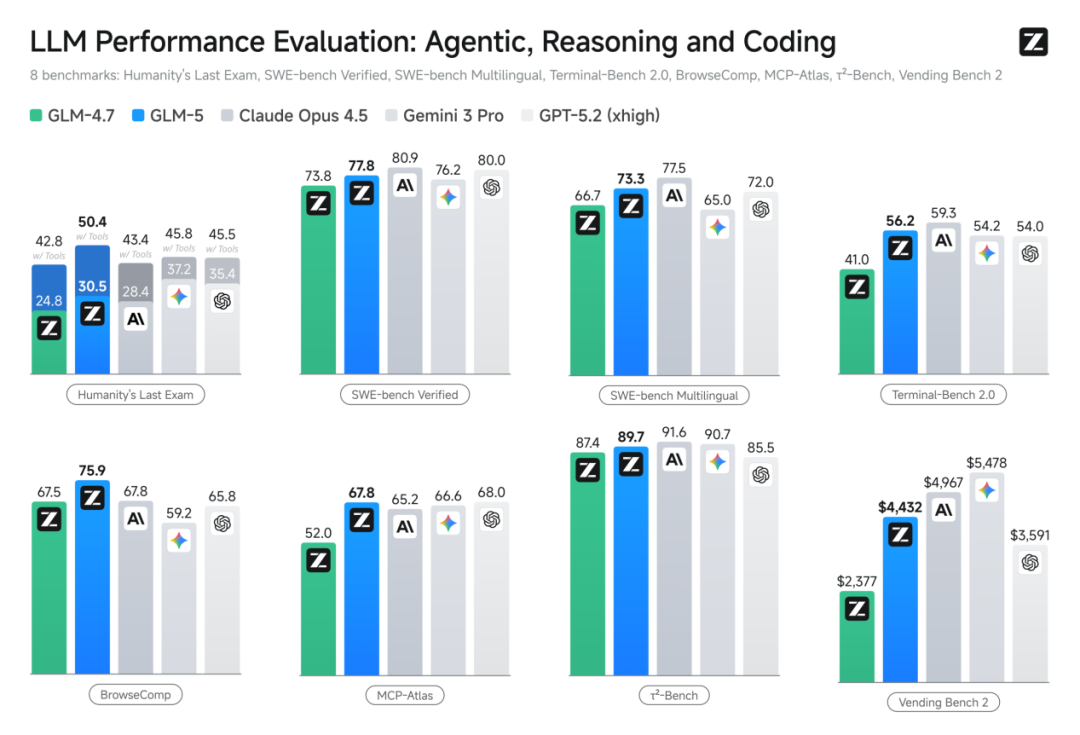
在编程能力和代理能力上,GLM-5在SWE-bench Verified、Terminal-Bench 2.0等主流基准测试中均取得高分,已经达到开源模型领先水平。
根据内部测试结果,GLM-5在进行前端构建任务时,成功率高达98%;后端重构和任务规划场景中,成功率相比前代版本GLM-4.7也提升了超过20%,实际使用体验接近Claude Opus 4.5。
GLM-5已经能够自主拆解用户需求并协调多工具链,从而妥善处理依赖关系并完成端到端的任务交付。例如,用户输入自然语言需求后,模型即可直接生成可部署的横板解谜游戏和论文检索应用。
而在Vending Bench 2模拟经营测试中,模型构建的智能体运营自动售货机在1年之内赚到了4432美元,展现出对资源分配、市场波动和长期目标一致性的把控能力。
GLM-5体现出的这些能力,不约而同地指向了智能体工程化的核心需求:模型必须在多步骤、跨工具、长时间跨度的任务中保持逻辑的连贯性和执行的稳定性。
慷慨的开源与算力缺乏的事实
GLM-5性能之强大有目共睹,更可贵的是智谱选择以MIT License协议将GLM-5完整开源,同步发布于Hugging Face和魔搭社区,此后还接入了TRAE国内版和Ollama,直接“拆除”了开发者的使用门槛。
与此同时,作为“国产大模型之光”,模型与华为昇腾、摩尔线程、寒武纪等国产芯片平台深度适配,通过优化底层算子提升推理性能,国产算力生态新增一大支柱。
但是,如此慷慨的开源举措却与商业端的资源紧缺形成了鲜明的对比。
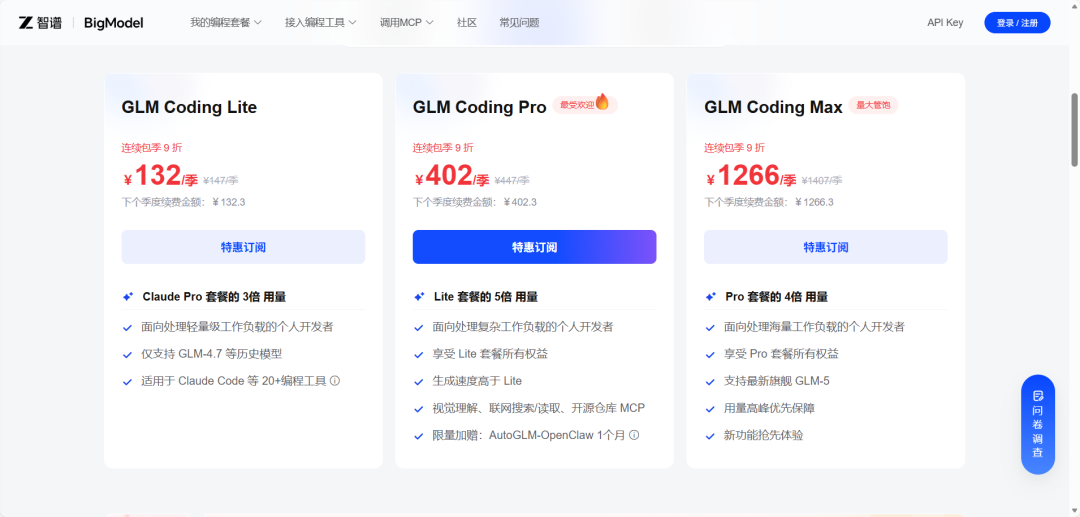
但是,与GLM-5发布同时而来的消息,还有智谱GLM Coding Plan的价格上调:套餐涨幅30%以上,取消首购半价优惠并新增周额度限制。
此前三款订阅服务的季度价格为:
GLM Coding Lite:60元/季
GLM Coding Pro:300元/季
GLM Coding Max:600元/季
更为关键的是,官方此前发布公告称GLM-5在商用API层面仅对MAX套餐用户开放,待到模型资源更迭完成后Pro套餐用户才可使用GLM-5,至于Lite套餐用户则无明确说明。

智谱在收到大量针对该问题的反馈后,工作人员迅速在技术社区和平台回复,坦承算力资源极为紧张,“并发不足已持续1个月”、“限购20天仍无法满足需求”等问题尚未解决。Pro套餐用户在未来2-3日内即可使用GLM-5,Lite套餐用户仍无明确期限。
除此之外,GLM-5的API价格也是国内顶尖,输出价格甚至是DeepSeek-V3.2的6倍:
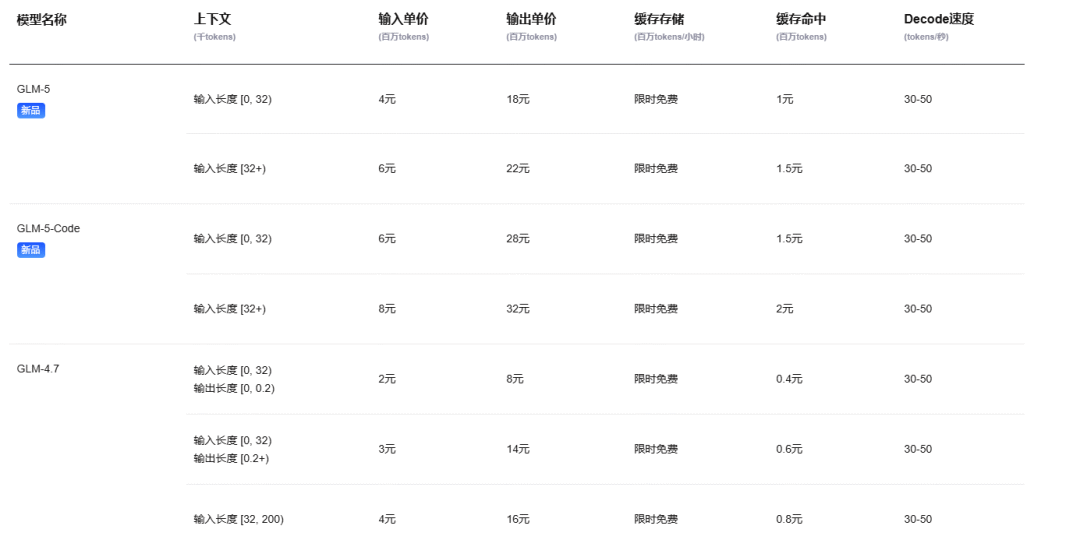
智谱面临的现实困境也是国产大模型厂商共有的:技术迭代速度已经远超基础设施供给能力。
开源释放权重已经快速构建起国产模型的生态影响力,但商用服务的稳定性仍然严格受制于GPU集群规模。
智谱的慷慨开源和商用限流,既是技术自信的展示,也是对算力瓶颈的无奈妥协。想要让国产大模型进入工程化阶段,基础设施的支撑能力仍然是最核心的问题。
03 Minimax:轻量级架构与效率优先
同样交出大招的不止有智谱,还有与之几乎同时上市的MiniMax。

不过,与DeepSeek类似,MiniMax官方也没有发布任何新模型的公告和技术文档,而是悄悄上线了新模型MiniMax-M2.5,并通过媒体报道传递了核心信息:
MiniMax-M2.5定位为全球SOTA编程模型,直接对标Claude Opus 4.6,并能在工作重点核心生产力场景中达到行业领先水平。
据称M2.5最显著的技术特征是仅10B激活参数量的轻量化设计。在当前国产大模型普遍采用数百亿至上千亿参数的背景下,这一规模显得十分克制。
尽管如此,M2.5仍然能支持100 TPS的高吞吐推理,速度超过国际顶尖模型,同时在显存占用和推理能效比上具备优势。若数据真实,在同等硬件条件下M2.5可支持更高并发的实时编程任务,有效降低部署成本。
虽然仍无权威性测试结果,但社区的第三方实测提供了有限验证。在一项自发组织的代码修复能力测试中,M2.5在多平台环境下位列第九,通过率为61.5%。而作为参照的GPT-5.3 Codex以73.1%的通过率位居榜首,Claude Opus 4.6的通过率为65.4%。
考虑到M2.5的激活参数规模远比其他模型要少,该模型在单位算力下的任务完成效率具备一定竞争力。但是否能达到全球SOTA水平,则需要等到技术文档发布后进一步验证。
在算力资源普遍紧张的行业背景下,MiniMax选择以轻量级模型切入已经接近饱和的编程赛道,推测是为了规避大规模参数模型带来的部署成本压力,并通过高吞吐设计抢占企业级的实时编程场景。
不过,缺少透明的技术细节让用户难以评估其能力边界,能否实现差异化竞争优势将取决于实际用户体验和价格。
(来源:新浪科技)
