加密货币市场突发暴跌!超17万人爆仓!
加密货币市场再现抛售潮。
2月5日,比特币价格快速跳水,跌破71000美元/枚,创下本轮熊市新低。
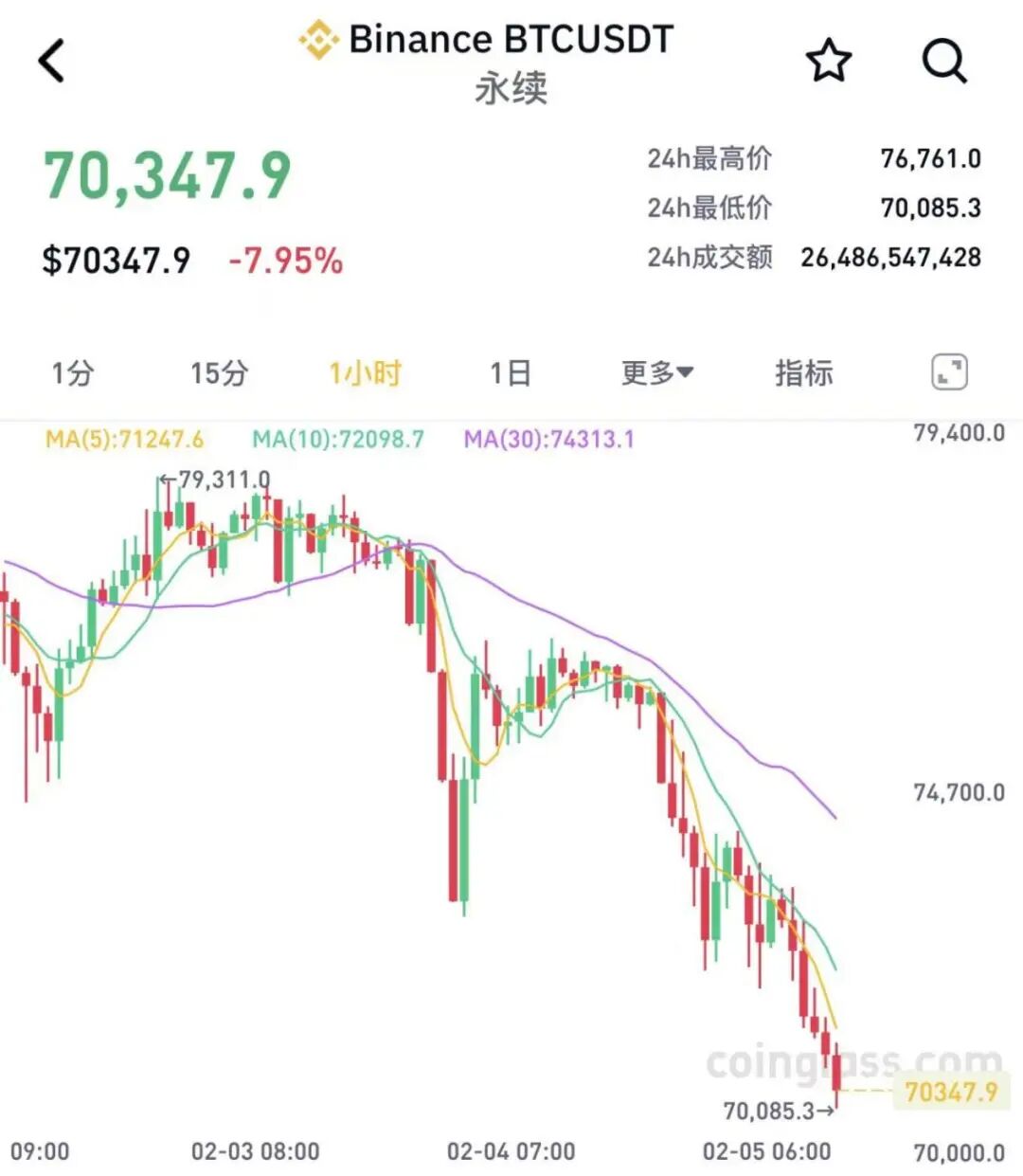
以太坊价格短时跳水,最新报2088.21美元/枚,跌超8%。
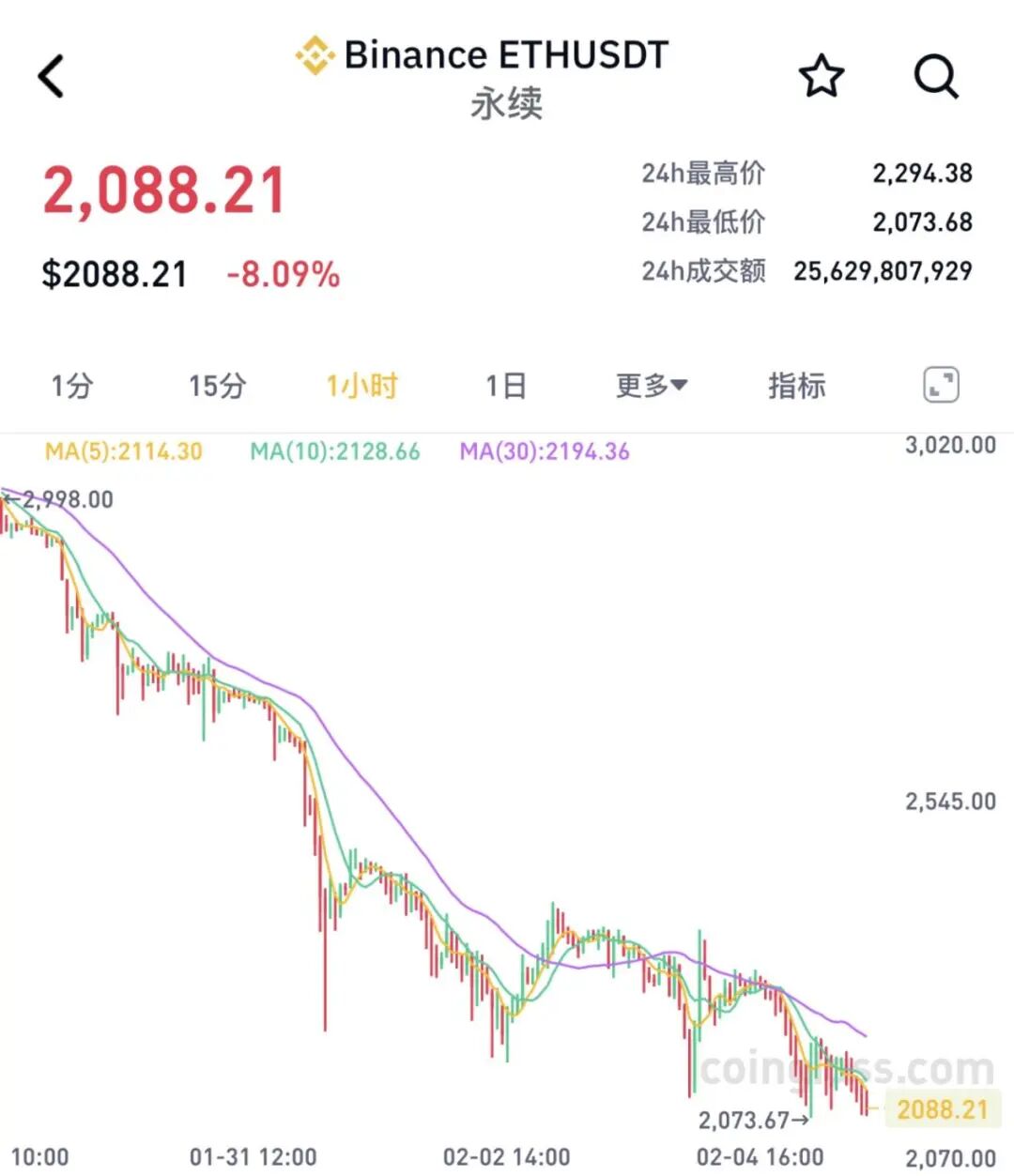
其他加密货币跟随跌势,BNB、XRP、狗狗币跌幅居前。
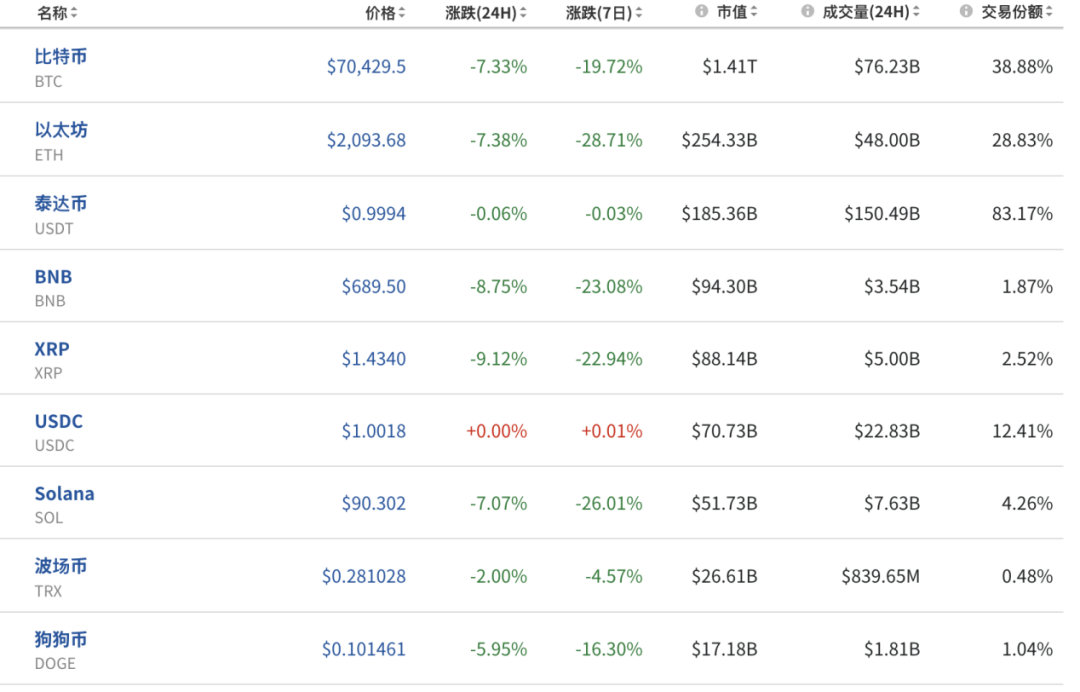
CoinGlass数据显示,过去24小时加密货币市场共有超17万人被爆仓,爆仓总金额为8.3亿美元。
消息面上,美国财政部长贝森特在国会听证会上表示,美国政府将保留通过资产没收获得的比特币,但不会在市场下行时指示私营银行增持比特币,也无权“救助比特币”。在与加州众议员、加密货币长期批评者Brad Sherman的问答中,贝森特强调其本人及金融稳定监督委员会(FSOC)均无相关权限,并披露政府持有的被没收比特币价值已由约5亿美元增至逾150亿美元。
对于比特币的走势,加密货币做市商Efficient Frontier的业务发展主管Andrew Tu指出,过去一周加密货币市场遭受重创,目前市场情绪极度恐慌。“如果比特币无法守住7.2万美元,那么,很可能会跌至6.8万美元,甚至在最初的反弹之后可能跌回到2024年的低点。”
据CoinDesk分析,一项被称为“比特币盈亏供应量”的链上指标显示,当前市场可能正在接近历史性的底部区域。该指标通过对比处于盈利和亏损状态的比特币数量来衡量市场整体持仓成本与价格的关系。
“大空头”迈克尔·伯里本周也警告称,比特币已暴露出其纯粹投机资产的本质,未能像贵金属那样建立起对冲功能。

(来源:天天基金网)
