央企牵头 这个AI开源社区要让大模型跑遍“中国芯”
「造芯」不易,「用芯」更难。
大模型加速落地,国产芯片需求日盛,但模型真正能在国产芯上「开箱即用」者寥寥无几——这关键的「最后一公里」,谁来铺路?
现在,有个社区牵头 「组队攻坚」 ,给出了一种解法。
6 月 30 日,百度文心大模型 4.5 系列正式开源,并同步登陆 AI 开源社区——魔乐社区( Modelers.cn )。
趁热打铁,魔乐社区同步正式发起「模型推理适配协作计划」(以下简称「适配计划」),集结开发者、算法团队、芯片厂商与推理工具伙伴,共建开源协同生态。
目标只有一个:让大模型跑遍中国芯。
开源模型如何跑遍中国芯?
先拆解一下「适配」这件事到底在适配什么。
一个大模型顺利实现推理应用落地,要跨越三道槛儿:
适配推理引擎:先让引擎「读懂」模型,能解释其结构、识别其算子;
适配计算平台:让芯片「听得懂」引擎分发的任务,高效完成各类操作;
适配上层调度:让模型能被业务系统便捷接入调用,真正上线服务。
当前,业界已发展出多样化的工具来支持大模型推理和适配的各个环节。
比如,vLLM 等高性能推理引擎,CANN、MUSA 等计算架构,FastDeploy、FlagServing 等部署工具,以及众多开源的模型转换、量化、融合工具等……这些工具在各自领域都发挥了重要作用,整个工具链其实已经相对完整。然而,挑战在于如何有效连接和协同这些分散的工具链与适配经验。因此,亟需一个跨环节的协作平台与机制,把这些资源组织起来,解决「最后一公里」的适配难题。
于是,魔乐社区推出「模型推理适配协作计划」,并动手做了几件事。
第一件事,是把原来的「镜像中心」升级为「工具中心」,位置也从「更多」菜单一跃来到首页 C 位,对标模型库、数据集 ——
这一调整绝非简单的位置迁移,而是将开放的工具链提升至与模型、数据同等重要的生态基座地位。
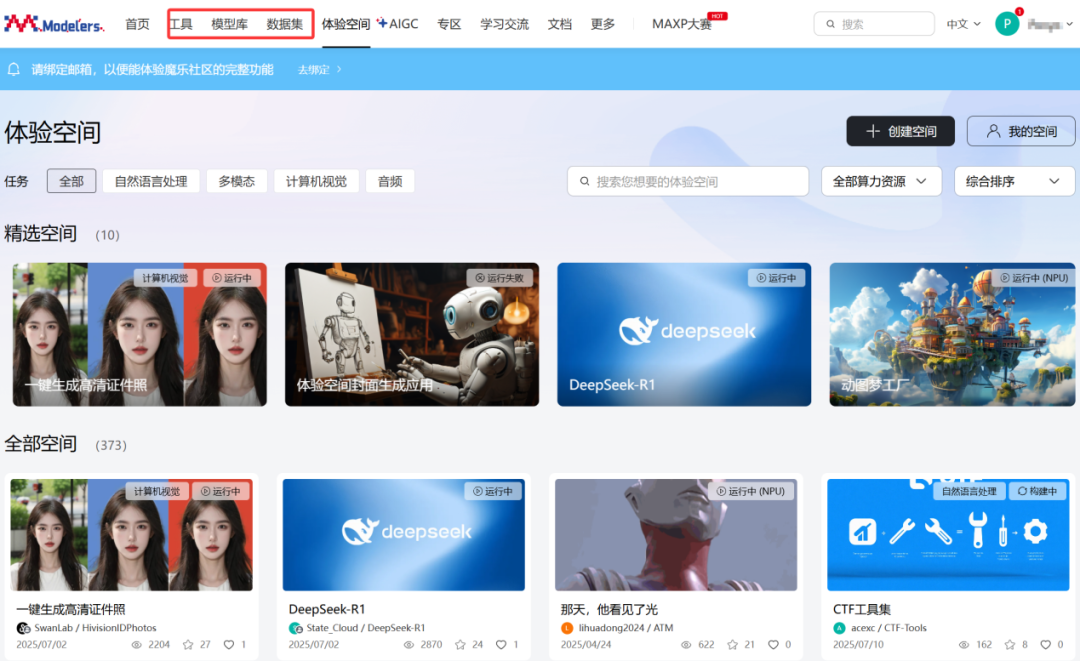
现在,开发和部署工具,与模型库、数据集并列首页「C位」。
类似模型库的运作逻辑,「工具」中心将提供模型转换迁移工具,也将支持开发者上传自己适配好的推理镜像、工具链和运行环境,还可以对已有镜像进行更新。
每次发布需社区审核,确保质量稳定、可复用。
与此同时,「工具」依旧保留了代码托管能力,方便开发者在魔乐生态内实现适配共享。
换句话说,升级后的板块就是想让「环境跟着模型走」,将碎片化的适配经验沉淀为标准化、可复用的结构化基础设施,让后续开发者无需重复造轮子,直接站在已有成果上推进适配和性能优化,大幅降低协作成本。
另一件事,是把托管板块升级为协作空间。
以前,模型架构和权重文件一经上传,基本就「尘埃落定」。但像 Readme 文档、适配好的推理代码等内容,却得随着芯片、工具链适配进展不断更新。
比如,今天模型适配了一个芯片,明天又支持了另一种,这些信息和代码都得有人来更新和上传,并且不同开发者的适配成果可能分散在各处,难以汇总复用。
现在,在「协作空间」——
所有用户均可提交 PR(代码合并请求),共同参与文档撰写、适配代码开发与推理配置优化。
文档即代码:Readme 不再是静态说明,而是支持多人实时编辑的协作载体,适配进展、使用指南等信息实时同步。
比如,模型开发者上传了一个大模型到魔乐社区,不止模型权重,还有配套的推理工具链。一旦模型被标记为「基础模型」, 模型卡片就会自动开启「协作」入口。
这时候,开发者可针对不同芯片上传独立的适配代码分支,形成版本清晰的 「芯片适配库」。
例如,如果有工程师想将模型适配跑在某款芯片上(例如昇腾),只需要点开「协作」按钮,选择目标推理引擎,新建一个「Ascend」文件夹,提交适配后的推理代码,提个 PR,就能提交到社区。
社区会有审核机制,一旦验证通过,就能被正式合入模型项目中,成为社区认可的适配版本。
每一个适配版本,就是一个独立的子工程,版本分明,职责清晰,协作记录也都有迹可循。
除代码外,适配过程中产生的量化权重、优化配置等资产也可通过 PR 提交,形成完整的技术方案。
这种机制将分散的适配工作聚合到统一平台,支持一键下载与二次开发, 避免了成果碎片化,让每一次适配进展都能沉淀为社区共享的资产。
为了让「适配计划」真正跑起来,魔乐社区广泛联动产业力量。
一方面联动壁仞科技、海光、华为(昇腾)、摩尔线程、沐曦、算能、燧原科技等国产算力厂商(按中文首字母排序,无先后顺序),为开发者提供硬件、工具和技术支持。
另一方面,整合多元化适配和推理软件生态,并联合工具伙伴,助力开发者快速掌握适配工具链,实现跨硬件平台与引擎组合的深度推理性能调优。
与此同时,还牵手伙伴共建教程、补文档、传经验,手把手帮开发者跑通流程、填平坑点。
接下来,「适配计划」 将持续开放,持续吸纳更多芯片厂商、模型开发者与开发者加入;SIG(特别兴趣小组)技术组也将进入常态化运作,聚焦适配技术攻坚与标准制定。
若此协作机制成功运转,将有望解决国产芯片生态最棘手的 「协同短板」—— 让模型与芯片的适配从 「零散突破」 走向 「体系化落地」,为国产 AI 算力生态的闭环构建提供关键支撑。
「适配计划」背后
很多人还记得,DeepSeek-R1 爆火出圈后,一件不太常见的事发生了:国产芯片厂商「组团发声」,纷纷宣布已完成对该模型的适配,并表示正在推进更多大模型的适配工作。
国产模型火了,国产算力也想借势出圈。背后的逻辑其实很直接——
只有模型真能在国产芯片上稳定跑起来,芯片才有机会真正用起来。
但现实却很尴尬:大模型加速落地,随着金融、政务、制造等重点行业对「自主可控」的需求越来越强,国产芯片的出场机会越来越多,然而,真正能做到「即拿即用」的大模型,依旧寥寥无几。
为什么会这样?
首先,这和开源模型本身的特点有关。
开源大模型不是一个「装好就能跑」的整包,它往往拆成模型架构、权重和推理代码三块。HuggingFace这样的开源平台聚焦模型分发和训练等,并不侧重构建异构算力的协同适配机制。
其次,是技术层面的现实难题。
国产芯片之间架构差异大,很多都有自己独立的推理引擎。同一个模型,想让它在不同芯片上跑得通、跑得快,就得「量身定制」——专门做适配、调度、优化。
比如,有的芯片需要做量化来压缩模型体积,有的要进行算子融合来提速。
现在,这些活儿是谁在做?
一部分由模型厂商亲自下场,但资源有限,很少有团队会专门为不同国产芯片配专属工程师。
更多时候,是芯片厂商主动出击。随着大模型推理结构的日趋标准化、算子体系逐步统一,「自己动手」的门槛已显著降低。就像 DeepSeek 爆火之后,一些厂商为了尽快跑通,从芯片指令集到内存管理、数据传输都做了大幅调整。
还有一类,就是开发者出于兴趣或业务需求自发适配。但这类工作高度分散、重复投入严重,质量也参差不齐。
对比之下,为什么 Hugging Face 上的模型大多都能在英伟达 GPU 上开箱即用?靠的不是单一厂商的「单点突破」,而是整个生态高度打通,工具链成熟完善。
这也是魔乐社区「适配计划」要解决的核心问题——
不再单打独斗,通过构建统一的协作框架,串联模型开发者、芯片方、工具方与开发者,形成生态合力,一起把模型从「能发布」推到「即插即用」。
魔乐:AI 开源的「中国样本」
为什么是魔乐来牵头做这件事?
答案要从它的「出身」和「使命」说起。
2024年 8 月,在央企巨头、中国电信天翼云的牵头下,魔乐社区正式上线。与很多主打「模型集市」的开源平台不同,魔乐从一开始就瞄准了另一个更现实、也更棘手的问题:
开源 AI 发展,要的不只是「代码开放」,还得「能协同、能落地」。
模型当然重要,但真正推动国产 AI 落地的,不只是一个个模型,而是支撑它们生长的底座系统——包括开源数据集、适配工具、部署引擎,乃至合规、调度、治理等基础能力。
因此,魔乐选择做一个中立、公益的开源社区,扮演「国产 AI 落地的基础设施」。
他们从零搭出一套覆盖模型、数据、工具、应用与算力五大板块的开源协作体系。
社区已汇聚 1000+ 优质大模型、涵盖 TeleChat、DeepSeek、Qwen、智谱等大模型,其中多数都已经适配好国产算力。
依托天翼云及「算力朋友圈」供给,社区可提供公益性国产化算力资源。
最直观的体现就是魔乐推出的「在线体验空间」:
基于社区提供的模型和算力,开发者可通过 Gradio 等主流 SDK 快速搭建 AI 应用,并一键部署、分享。
还有线上、线下的学习交流活动。
魔乐社区不只有在线平台,最近还正式成立了理事会,进一步规范社区管理与生态共建。
「中国样本」,步步为营
不到一年时间,魔乐就搭起了生态的基本盘——
已聚合超过 20 家深度合作伙伴,托管模型、数据、工具等各类开源项目累计突破 1 万个;
首发多个昇腾适配大模型,推动模型实现国产化原生适配;
模型、数据与工具融合共建,已上线 200 多个国产化 AI 应用。
更重要的是,这套生态始终围绕「产学研协同」展开,AI 落地的挑战正在被「共建、共享」的生态范式一点点瓦解。
魔乐社区致力于发掘、打造和推广好的项目。一方面,深耕高校等原生创新场景,定向发掘一批基于国产算力起步的潜力项目。
另一方面,通过「国产算力应用创新大赛」等机制,实战中筛选优质标的,推动它们与底层算力平台的深度适配与融合。
找到好项目只是起点,更关键的是——放大价值。
魔乐为项目提供从算力资源、工具链到调度框架、落地渠道的全栈支持,推动它们从 demo 走向产品、从实验室走向产业化,让每一个「跑得通」的应用都有「火出圈」的可能。
例如 Stable Diffusion WebUI、ComfyUI 虽在设计创作领域早已成名,但缺乏系统的国产适配支持。魔乐正加大力度,推动它们与国产工具链深度融合,加速落地,近期正式上线了 AIGC 专区,已实现基于国产算力的快速专业生图。
如今,全国已有多个有影响力的 AI 开源社区,都在不断推进国产 AI 能力的积累。
但这只是开始。
随着大模型快速普及、国产软硬件协同需求走强,AI 社区或将迎来真正的「井喷时刻」。
而魔乐选择了一条更难、但也更有价值的路——不止做模型的「集市」,更要做模型、算力、工具的协作平台。
坚持中立、公益、开放的定位,魔乐正推动大模型在「中国芯」上真正跑起来,成为国产AI算力生态自主可控与高效协同的重要支撑。
(来源:新浪科技)
