“大模型六小虎”被曝获20亿融资,放出首个推理模型技术秘籍

作者 | 程茜
编辑 | 李水青
智东西7月15日消息,近日,“大模型六小虎”之一MiniMax新动向频发。
昨日,据晚点报道,MiniMax接近完成近3亿美元(折合人民币约21.5亿元)的新一轮融资,投后估值超过40亿美元(折合人民币约287亿元)。“大模型六小虎”中,智谱、百川智能、月之暗面估值均超200亿元,零一万物、阶跃星辰超100亿元。
上个月,MiniMax前脚宣布启动“发布周”,一口气发了推理模型MiniMax-M1、视频大模型海螺02、通用智能Agent MiniMax Agent、端到端视频创作Agent海螺视频Agent、语音设计工具;后脚外媒彭博社就爆料,MiniMax正在筹备赴港上市。
MiniMax成立于2021年11月,去年3月获得6亿美元A轮融资,当时估值约为25亿美元(约合人民币180亿元),该轮融资由阿里巴巴集团领投,红杉中国、高瓴资本参投。此前,腾讯、米哈游等公司也参与了MiniMax的融资。
今日,MiniMax放出了其在7月10日的M1全球技术闭门会的技术实录,M1团队与香港科技大学、滑铁卢大学、Anthropic、Hugging Face等技术人员,围绕RL(强化学习)训练、模型架构创新、长上下文展开探讨,主要干货信息如下:
1、针对有限上下文长度,RL能赋予模型新能力;
2、RL训练可以让模型获得范围广阔的知识;
3、只在数学和代码上进行RL训练,模型更容易产生幻觉;
4、Latent reasoning(隐性推理)可能是让模型用图像进行思考的一个方向;
5、Reward Modeling(奖励建模)、多智能体、AI自动化研究、非token空间推理是RL领域令人兴奋的挑战;
6、长上下文在Agent工作流中有巨大潜力;
7、混合架构将成为主流;
8、大模型领域,脱离硬件的纯粹算法研究正逐渐失去关注度。
如今大模型领域呈现出激烈的竞争态势,DeepSeek等模型引发行业震动的同时使得国产大模型格局深度洗牌,大模型六小虎纷纷调整战略求生存,在此背景下,MiniMax得到资本青睐,拿下大额融资、被曝冲刺IPO,其对于大模型在长文本处理能力、低成本训练等方面的有哪些创新点?这次技术闭门会有哪些独到见解能为业界提供参考?我们试图从其精华整理中找到答案。
一、揭秘M1背后闪电注意力机制,推理模型自我反思的关键是高效利用计算资源
今日放出的技术闭门会实录提到,MiniMax研究人员针对MiniMax-M1采用的混合线性注意力以及推理模型是否已经具备推理和自我反思能力进行了探讨。
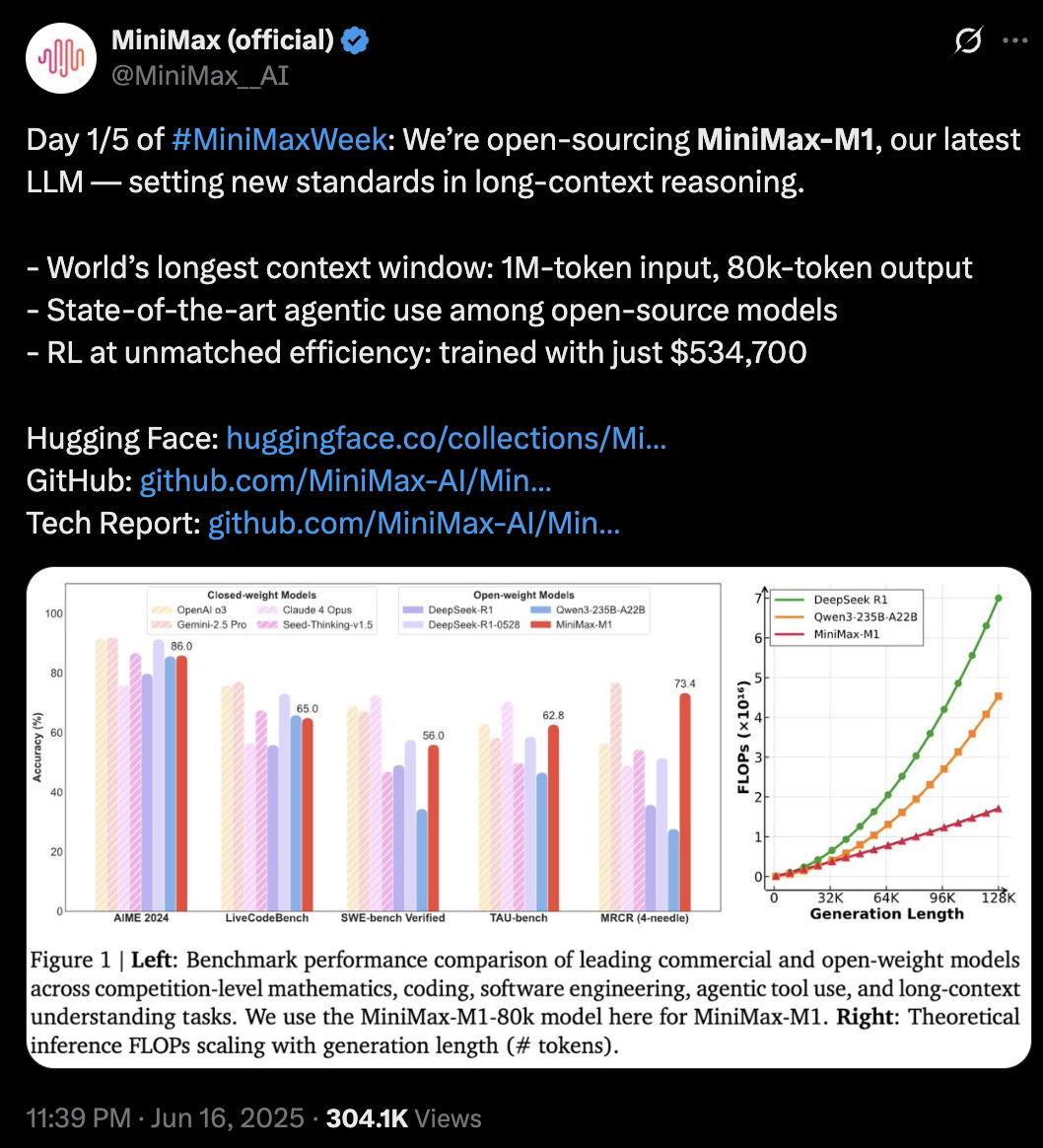
MiniMax-M1是其发布周最先更新的模型,作为全球首个开源大规模混合架构的推理模型,参数规模达到4560亿,每个token激活459亿参数,原生支持100万上下文输入以及业内最长的8万token推理输出,输入长度与闭源模型谷歌Gemini 2.5 Pro一致,是DeepSeek-R1的8倍。此外,研究人员训练了两个版本的MiniMax-M1模型,其思考预算分别为40K和80K。
MiniMax在标准基准测试集上的对比显示,在复杂的软件工程、工具使用和长上下文任务方面,MiniMax-M1优于DeepSeek-R1和Qwen3-235B等开源模型。
其博客提到,在M1的整个强化学习阶段,研究人员使用512块H800训练了三周,租赁成本为53.74万美金(折合人民币约385.9万元),相比其一开始的成本预期少了一个数量级。
M1是基于MiniMax-Text-01模型开发,采用了混合专家(MoE)架构和闪电注意力机制。
M1的闪电注意力机制可以高效扩展测试时计算。例如,与DeepSeek-R1相比,M1在10万个token的生成长度下只需消耗25%的FLOP,使得M1适合于需要处理长输入和广泛思考的复杂任务。
对于混合线性注意力会如何影响使用RL的推理模型的性能,技术探讨会中提到,在训练过程中,当其扩展到可处理数万token上下文长度的模型时,遇到了RL训练停滞不前,奖励信号在仅几百步后就不再增长的问题。这与线性注意力架构在这种规模下固有的训练不稳定性有关,会导致某些层激活值爆炸等,并使模型在训练和推理时的行为出现严重错位。
这使得其发现混合线性注意力的一个根本性权衡:效率极高,单位token的计算成本非常低,但通常需要生成更多的 token(即更长的推理路径)才能达到与full attention模型相同的性能。其工作证明:通过适当规模的RL以及合适的推理时算力,混合注意力模型能实现媲美Full Attention(全注意力)架构性能。
这对未来架构设计的一个关键启示——评估方法的重要性。为了公平地比较混合模型与其他模型,研究人员应该基于在给定任务下、固定总计算预算内的性能来进行评估,而不仅仅是比较固定输出长度下的效果。
被问及推理模型是否已经具备了System 2推理和自我反思能力,研究人员称,System 2推理和自我反思,可以被理解为从大语言模型基本原理中涌现出的、可被观测的模式。
首先其核心驱动力,是有效利用更大的计算资源来获得更好性能的能力。高级推理能力,是扩展这些资源后的直接结果,而非其根本原因。本质上,为模型提供更多的计算能力去“思考”,使得这些复杂的模式得以涌现。
其次,这种高级推理可以被看作是一种自动化的Prompt Engineering。对于数学或编程等复杂任务,模型学会了生成自己的内部思考过程,这实际上取代了人类提供详尽、分步式指令的需要。
对于写作等任务,模型在思考过程中会先对问题进行分析,并对写作步骤进行专业化拆解。它会独立地执行诸如规划和对问题进行更深层次分析等操作。这使得模型能够通过创建详细推理路径来“像专家一样思考”。
因此System 2推理和自我反思,实质上是如何高效地利用并扩展计算预算(Computation Budget),同时也是模型自动深化用户问题的体现。
二、从MiniMax-M1到大模型产业核心议题:模型架构创新、RL训练、长上下文应用
从MiniMax-M1出发,MiniMax团队成员与其他技术专家还探讨了当下大模型行业的其他核心话题,如模型架构创新、RL训练、长上下文应用等领域探讨了当前的前沿话题,有以下8大核心要点:
1、RL训练可增强有限上下文长度模型能力
首先需要定义模型的基础能力:对于给定上下文长度的模型,在一组特定问题上无限次尝试下的通过率(pass@k, k→∞)是多少,如果通过率为1,就表示这个模型能解决这类问题,通过率为0,则表示模型解决不了。
如果模型的生成长度,即模型思考过程的长度无限,RL无法赋予模型新能力,所有能用自然语言表述的问题,理论上模型都可以通过有限次的采样尝试来解决。
如果针对有限上下文长度,RL能赋予模型新能力。因为RL所做的是改变模型输出的分布,预训练后,模型可能需要至少10W tokens才能解决某个问题,但经过RL微调后,它可能只需要10K tokens。如果模型有限上下文长度是50K tokens,那么RL的确赋予了模型新能力。
在有限上下文长度下, pass@k是一个好的衡量指标。K的取值很重要,这取决于如何定义模型能力,如果定义是“模型至少有一次能解决这个问题”,那么应该用尽可能大的k来衡量pass@k;但如果定义是“模型能否在4次尝试内解决问题”,那应该去衡量pass@4。
目前Reward(奖励)是RL scaling的核心瓶颈,特别是如何为那些不基于结果的奖励(Non-outcome-based Reward)进行建模,比如,人类可以从别人写的一段文字或反馈中获得正面或负面的感受,但目前并没有很好的方法来对这种主观感受进行建模。
2、预训练的价值在于更多样化的数据分布
原则上可以,只要有足够的信息源就可以用RL来替代任何过程。某种意义上,预训练只是RL的一种特例,任何监督学习都可以被看作是一种特殊的强化学习。现阶段,RL训练阶段的数据分布,要比预训练数据的分布狭窄得多,这正是目前进行预训练能带来的最大收益——它让模型获得了范围远为广阔的知识。
但在当前阶段,预训练的价值在于可以在预训练阶段接触到更多样化的数据分布。目前RL研究的核心挑战之一是如何拓展至Reward清晰的环境之外。奖励建模(Reward Modeling)可能是一种解决方案,但更为通用的奖励信号依然是行业在探索的方向。
3、只在数学和代码上做RL训练更易产生幻觉
关于通用推理,至少在今年二月左右,大多数RL数据都来自于数学或编程领域。事实上,只在数学和代码上进行RL训练,模型更容易产生幻觉。SimpleQA等事实性基准、MMLU等多学科问答基准上模型的性能都会显著下降。
因此研究人员做通用推理数据集的动机之一,就是创建更多样化的RL训练数据。WebInstruct-verified数据集旨在为所有领域构建更大规模的RL训练数据,以便模型能够在不同领域取得进步,而不仅是数学和编程。
现在MiniMax尝试进一步扩大这个规模,之前,通过在预训练数据集中搜索可用的RL数据来扩大规模,其已经将其扩展到50万量级,现在正尝试通过检索更大规模的预训练数据集,从中获取越来越多样的RL数据,并采用在Mid-training(中期训练)进行RL的范式,而不仅仅是作为后训练。
4、隐性推理是让模型用图像思考的可能方向
目前很多视觉推理范式,核心大都集中在文本形式的思维链上,视觉部分固化为一个ViT(Vision Transformer)编码器,无法让模型在编码图像上花费更多计算资源。像视觉语言模型Pixel Reasoner或其他研究,正试图帮模型重新审视图像的特定区域,并对其进行重新编码,从而在关键区域上投入更多算力。
但这并不是从底层提升模型能力的方法,现阶段更像是权宜之计。因为现有的视觉编码器太弱,无法很好处理高分辨率图像,所以才尝试用其他操作操纵图像表示,然后从输入中重新调用并在此基础上进行推理。现阶段,重新调用帧或高亮显示等工具,实际上都只是在增强感知能力。
其他更复杂的图像生成技术等工具,能从根本上改变图像,其已经超越了单纯增强感知的范畴,比如在几何问题中画辅助线。这种方法如果奏效,未来或成为“用图像思考”的更强大版本。
但仍需解决其根本的瓶颈问题:如何更好地编码视觉像素,以及如何以更好的方式在抽象潜在空间(Latent Space)中进行视觉推理。
Latent Reasoning(隐性推理)可能是一个方向。机器人或具身智能领域的视觉推理需要在空间中思考,在这些涉及空间感的场景下,很多推理过程是隐式的,无法被清晰地表述或言语化。
5、多智能体、AI自动化研究是RL领域挑战
RL面临挑战之一是Reward Modeling,特别是如何超越那些结果容易被评估的环境;另一个可能很重要的领域是多智能体,多智能体目前更多受限于基础设施,而非理论研究;另一个领域是AI自动化研究——让模型自己训练自己,这与AGI的定义相关,即当模型可以在没有人类干预的情况下,自我训练并自我提升;非token空间的推理也存在机会。
6、长上下文是Agent的破局点
长上下文在Agent工作流中有巨大潜力,Agent完成某个任务时,能将整个代码库、API参考文档、历史交互数据等等,全部一次性喂给它。这种任务不能分几次调用来处理,因为智能体完成任务时掌握的关于这个项目的信息越多,产出的质量就越高。
研究人员有望从目前在大多数情况下,只能处理相当孤立任务的智能体,发展到那些能够管理复杂项目、同时保持完整上下文感知的智能体。
M1超长上下文模型的真正价值在于解锁了全新的企业级应用场景。例如,法律行业客户需要把文件一块一块地喂给大语言模型,并用一些窍门来优化检索和上下文管理。这样问题在于,可能错过埋藏在某个随机法律文件某一页中的关键细节。1M token的上下文窗口就可以一次性处理整个案件历史、所有相关判例以及所有其他信息源。
7、混合架构将成为主流
对比纯线性注意力和Full Attention,混合注意力机制(Hybrid Attention)是最有前景的方案。纯线性注意力机制有很多根本性局限,因为它的状态大小是固定的,因此,在处理长序列建模问题时表现不佳。
Full Attention虽然提供了灵活性,但其代价也显而易见:KV缓存大小会随着序列长度线性增长,并且训练复杂度也是平方级的。当序列不断变长时,高昂的推理和训练复杂度就会成为瓶颈。
混合架构将会成为模型设计的主流,因为随着对大规模部署和低延迟需求的增长,人们会越来越关心推理效率和模型的推理能力。未来如何进一步拓展混合注意力架构的空间,研究人员可能需要探索不是简单地用固定的比例来交错堆叠Softmax注意力和线性注意力层,或许需要更多样的混合架构形式。
在大模型领域,脱离硬件的纯粹算法研究正逐渐失去关注度。如果一项技术无法规模化,或者不能被高效地部署,那它就很难获得关注、形成势能。一个算法不仅要在理论上站得住脚,还必须在硬件上——尤其是在GPU或TPU这类加速器上高效运行。如今的算法研究者们还应该掌握一些底层的GPU编程工具,这才是当今在大模型领域做算法研究的正确方向。
混合架构目前的瓶颈在于基础设施。混合模型的有效性在去年就已经得到了很好的验证,但没有公司投入更多资金进行大规模验证。
8、混合架构推理速度对现实应用至关重要
在推理层面,随着混合注意力架构越来越流行,为了在SGLang或其他推理引擎中充分利用缓存感知和缓存复用等特性,研究人员需要为普通架构和混合架构设计统一的抽象层,这样才能简单地将所有优化应用到混合模型上。
此外当前MiniMax模型7+1层交错的架构可能会带来一些工程挑战,特别是在用计算图优化(Graph Optimization)进行部署时,因为不同层的计算和内存访问模式是不同的,这会导致GPU利用率不平衡。可能需要用一些技术来解决它,比如批处理重叠(Batch Overlapping)或者更先进的Pipeline策略。
从支持混合架构的技术层面来说,首先需要一个混合分配器(Hybrid Allocator),有助于管理混合架构的KV缓存。这些状态的生命周期与全注意力层的KV缓存并不同步,所以需要设计如何让它与现有的缓存机制、预填充、解码等环节协同工作。
其次,批处理重叠(Batch Overlapping)会很有帮助。采用了混合架构后,如果能将两个微批次(Micro-batches)重叠起来处理,只要比例计算得当,理论上任意时刻都会有一个微批次在执行计算密集型的Full Attention 操作,从而最大化GPU利用率。
从生产部署的角度来看,混合架构的推理速度对现实应用至关重要。例如,有一个客户,需要并发处理多个几十万token的请求。但对于使用二次方复杂度注意力的传统模型,在这种输入大小和并发量下,生成速度都会变得极慢。
结语:“大模型六小虎”发力
作为MiniMax推出的首个推理模型,MiniMax-M1是其在模型架构、算法创新上的最新探索。未来大语言模型在测试或推理阶段,往往需要动态增加计算资源或计算步骤来提升模型性能,尤其在Agent发展加速的当下,模型需要进行数十到数百轮的推理,同时集成来自不同来源的长上下文信息,才能执行任务。MiniMax在M1上的技术探索,对于推理模型能力、长上下文处理能力的突破或许均有可复用性。
与此同时,“大模型六小虎”之一的月之暗面也放出了其最新一代MoE架构基础模型Kimi K2,总参数量达到1万亿(1T),在预训练阶段使用了“MuonClip”优化器实现万亿参数模型的训练优化。
可以看出,被DeepSeek冲击的“大模型六小虎”现在正在卯足劲头,竞相通过技术创新开发更实用、更低成本的模型。
(来源:新浪科技)
