读2万字论文秒出播客,发个链接就能唠!揭秘豆包最新语音模型技术

作者 | 陈骏达
编辑 | 漠影
国产语音模型又进化啦!
智东西6月12日报道,昨天,在火山引擎Force原动力大会上,豆包语音模型家族迎来上新,豆包·实时语音模型全量上线火山方舟,并对企业客户开放使用。
在豆包端到端语音对话系统基础上打造的豆包·语音播客模型,也在会上正式亮相。这一模型可在数秒内生成双人对话式播客作品,效果自然,具有互相附和、插话、犹豫等播客节奏,为用户带来了以假乱真的收听体验。

以上2款模型只是豆包语音模型家族的冰山一角。
在昨日大会期间举办的AI应用专场论坛中,字节跳动语音产研负责人叶顺平透露,目前,字节语音技术涵盖了音频生成与创作、音频理解与生成和音乐理解与生成三大能力矩阵,可在语音助手、智能客服、在线教育、虚拟陪伴、有声内容生产等场景发挥价值,日均语音处理量达到约150亿次,应用到超30个行业。

亮眼数据背后,是字节在语音技术方面的持续投入。端到端架构的应用为语音交互注入了“灵魂”;数据收集、预训练、后训练的协同作用,赋予了模型情感表现力和洞察力;强化学习等技术的引入,也为模型的持续优化和智能水平提升提供了有力支持。
这些技术突破共同推动了豆包语音模型家族在实时语音交互、语音播客等场景下的出色表现,也让我们看见了国产语音模型的广阔前景。
一、语音交互人机感太重?用端到端架构给AI注入“灵魂”
过去的AI语音交互系统大多采用多阶段级联架构,包含语音识别、文本生成和语音合成三大模块,冗长的处理链路限制了响应速度、控制能力和多模态一致性。
此外,由于各模块独立运行,此类系统难以理解语音中的情绪、语气和停顿等副语言信息,使得语音交互始终“人机感”浓重。
随着大模型技术的发展,如今的语音交互实现了语音理解与生成在同一模型中的协同完成,能够更自然流畅地进行对话。
去年,GPT-4o向世界展示了“真人感”语音交互的可能性,但在中文表现上仍有局限。而火山引擎今年年初发布的豆包·实时语音模型,凭借更强的中文理解力和高情商反馈,展现了中文语音交互的理想雏形。
要与这款实时语音模型对话,用户仅需在豆包App中点击右上角的电话按钮。在实测中,这款模型的“拟人感”让人印象深刻,在语气、用语、思考方式上更接近人类,可根据用户情绪和语境提供实时的高情商回复,还能演会唱,支持打断和主动搭话。
下方案例中,豆包不但根据“5岁孩子”的语境信息调整了所传达的信息,使用了极具亲和力的语气,二者相辅相成,很好地完成了交互的目的。模型生成这段语音的速度极快,在实际使用中用户对延迟的感知并不明显。
豆包·实时语音模型的端到端语音系统框架是实现这一切的基础。这一框架面向语音生成和理解进行统一建模,实现多模态输入和输出效果,从根本上避免了传统级联系统的种种劣势。
更进一步,豆包实时语音模型具备丰富的高阶语音控制与演绎能力。它不仅能根据用户的复杂指令进行语音风格的精细调控,如语速、语调、节奏等,还拥有不错的情绪演绎能力,能在喜怒哀乐之间自然切换,并在讲故事、角色对话等任务中表现出极强的表现力和声音创造力。
令人惊喜的是,得益于预训练阶段的大量数据泛化,模型已涌现出初步的方言与口音模仿能力,显示出语言迁移与适应能力。
豆包·实时语音模型即将上线的“声音复刻”能力,可以视作是上述高阶能力的延申。声音复刻实现了从“复刻音色”到“复刻表达”的全面升级,不仅能通过少量语音样本高度还原用户音色,更能在对话中根据语境复刻情绪与语气,实现情感一致、自然拟人的语音表达。
二、AI播客赛道热度不减,国产方案如何打造差异化优势?
豆包语音模型家族在不断扩展,其最新成员之一是于今年5月下旬推出的豆包·语音播客模型。
这一模型的推出,恰逢播客市场的蓬勃增长。《2025播客营销白皮书》显示,2024年,全球播客听众数量约为5亿人,播客市场规模预计突破300亿美元,同年,中文播客听众数量的增速达到43.6%,位居全球第一,2025年预计这一数字预计将突破1.5亿。
无论是对行业头部的专业创作者和机构,还是个人创作者而言,高度拟真的AI播客模型,都有望降低制作成本,扩展内容的丰富程度,提升创作效率。
其实,在过去很长一段时间内,AI播客届的明星产品一直是来自谷歌的NotebookLM。在智东西的日常体验中,NotebookLM能围绕既有材料和信息,以双人播客形式输出内容,但是内容的自然度、流畅度上仍稍显欠缺,在中文场景尤为明显。
这正是豆包·语音播客模型想要解决的问题。这一模型在实时语音模型的基座之上,对中文播客场景做了针对性优化,使播客内容、结构和对话推进更符合中文特点,包括口语化、双人互动等,对话节奏和感觉也更接近真人主播。
目前,这一播客模型已经可在豆包PC端、扣子空间等产品中体验。在豆包PC端,用户可上传PDF文档或是添加网页链接来生成播客。这一模型的生成速度极快,在智东西上传一篇论文后,豆包在几秒内便返回了可供收听的播客。
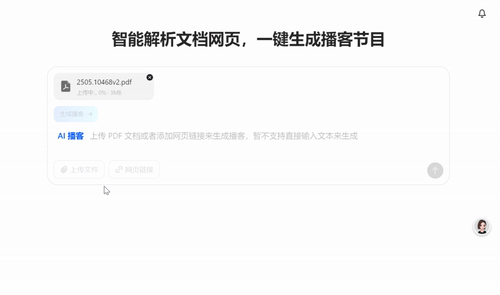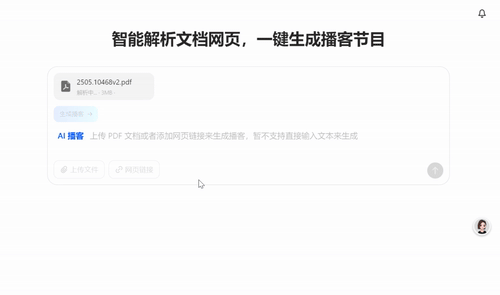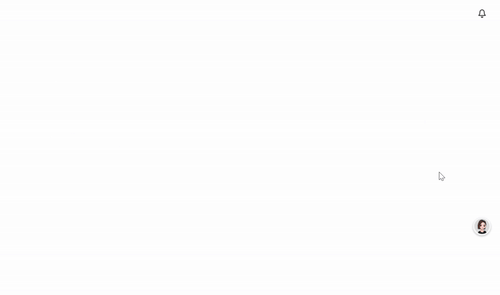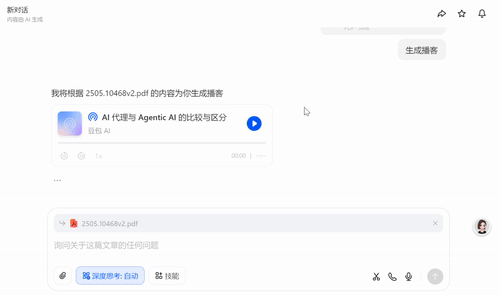
用户还可在地址栏的右侧找到网页播客按钮,点击后便可立即收听AI播客。
豆包·语音播客模型能对用户上传的信息进行改造,使其更适合听众消费。例如,智东西上传的这篇长达2万余字的论文本身采取了相对结构化的写作模式,如果照搬原文行文逻辑,播客的收听体验将会大打折扣。
但模型并未受到原文本的影响,会以问答的形式推进播客。每个问答的长度适中,凝练的问题为听众提供了更为清晰的收听体验,不会在长篇大论中失去方向。
豆包生成的播客文稿中有大量的语气词、附和、停顿,这很好地模拟了真人专业博客中的口语习惯,有效提升了拟人程度。

▲豆包·语音播客模型所生成播客的部分文字稿
为实现上述效果,豆包·语音播客模型先是对播客这一内容形式进行了详细的体验拆解,分析真人对话的节奏、自然度、信息密度等维度,基于这些认知,对模型的输出效果进行调整。
专业播客创作者也参与到了这一过程中,与模型团队共同探索和生产高质量数据,并在评测中不断优化模型生成的内容。
除了依赖豆包·实时语音模型在预训练阶段培养的拟人化交互能力,有监督微调(SFT)也对播客模型交互性、真实感的提升起到了重要作用。该团队对数据进行了细致的打磨与标注,为模型学习真人交互感提供了重要参考。
三、字节加速语音能力对外输出,合成、识别、翻译能力全面提升
在昨日下午的AI应用分论坛上,叶顺平向外界透露豆包语音模型家族未来的发展方向。在全量上线后,豆包·实时语音模型将会提供更多音色,玩法方面扩展音色克隆、歌唱能力等等。近期,豆包在歌唱场景的指令遵循、音准等属性已迎来提升。
近期爆火的豆包·语音播客模型,已在实践中展现出了几大可优化的方向。未来,这一模型生成的播客信息密度会进一步提高,用于提升对话自然度的语气词、句式会更加多样化,不仅只有简单的承接,还能有观点的交流与碰撞。
当下,豆包·语音播客模型提供了一男一女两个音色,不过不同风格的音色已经在开发中。未来,这款模型还可能探索更为丰富的音色组合,例如给娱乐、科技等不同细分领域的播客提供不同音色,提升收听体验。

豆包·语音播客模型未来或将支持单口播客、多人对谈播客等形式,甚至探索互动播客的形式——允许用户在收听过程中插话,甚至影响播客的内容走向。
通过提供种种更多的选择,豆包·语音播客模型有望进一步释放用户在播客和泛音频内容场景的消费潜力。
字节还在近期将其语音合成模型Seed-TTS升级至2.0版本,进一步提升模型表现力,提供给用户更丰富的指令控制能力;Seed-ASR语音识别模型基座再次升级,支持更友好的上下文理解能力,识别准确率进一步提升;端到端同声传译模型已经在豆包和飞书内部落地,在教育、金融、体育等等领域的中英互译效果已媲美人类译员。
未来,字节跳动将大力加速语音能力对外输出。相关举措包括全量开放豆包·实时语音模型、提供更多豆包同款音色,播客模型也有望在近期对外部客户开放。对业内企业而言,字节语音模型家族近期的集中上新,意味着革新业务的机遇。
结语:押注下一代交互入口,字节抢占领先身位
语音交互的庞大潜力,已在业内成为共识。这一交互形态原生的沉浸感、陪伴感,使其在语音助手、AI硬件、内容制作与消费等领域展现出独特的优势和广阔的应用场景。随着生成式AI驱动的语音技术不断进化,语音或许有望成为下一代人机交互的主要入口之一。
作为国内少数在语音模型侧和语音交互产品侧都占据行业领先身位的玩家,字节有望通过底层技术的持续提升和真实数据指导下的能力优化,为行业和用户带来更加智能、便捷和自然的语音交互体验。
最后,我们还将这篇文章发送给豆包·语音播客模型,一起来听听这一模型是如何阐述豆包语音模型家族最新进展的吧。
(来源:新浪科技)
