主流大模型再战高考作文:“幻觉”问题戏剧性拉满!百度、腾讯考生竟是一家人?
文 | 大模型之家
北京时间6月7日,决定莘莘学子一生命运的高考又一次开考。而作为一年一度的“保留节目”,大模型会战高考作文题也成了检验这一年来,大模型进步情况的一次“考试”。
值得注意的是,本次高考作文题目并没有以“人工智能”相关的考题,因此大模型之家随机抽选了北京卷的考题之一,对大模型的“写作能力”进行考察。
根据下面题目完成作文,按要求作答。不少于700字。不透露所在区、学校及个人信息。
生活中,到处都有数字在闪耀,如比赛记分牌、新年倒计时、车站电子时刻表、智能家电显示屏等。数字闪耀之时,可能是激动的时刻,可能是收获的见证,也可能是幸福的日常……
请以“当数字闪耀时”为题,写一篇记叙文。
要求:思想健康;内容充实、合理,有细节描写;语言流畅,书写清晰。
作为一年一度的“整活”环节,大模型之家这次不仅用上了“判卷智能体”,还在今年的挑战项目里增加了大模型“检索能力”与“幻觉测试”的小问题,更加细化了大模型们“考试”的内容。
这意味着不仅要根据北京卷的考题内容作答,考验了大模型本身的创作能力,还要考验大模型是否是“一本正经地胡说八道”。
为了增加一些“挑战性”,大模型之家选择北京时间的6月7日12:30分进行提问(此时距2025年高考语文科目考试结束仅一个小时),考验的就是大模型背后的联网搜索功能,能否及时获取到关键信息,如果没能获得信息的时候,大模型的回答会不会产生幻觉。
最终评分,我们还是通过大模型之家特制的“批改高考作文智能体Plus”进行阅卷,得出一个分数。同时根据大模型对于高考作文题的判断正确给予分数补正:
- 正确回答出作文题的年份和地区:+5分
- 表示自己不知道(诚实奖):+2分
- 没有回答:0分
- 大模型给出错误回答:-5分(幻觉惩罚)
PROMPT:
请回答下面的作文题目是哪一年哪个地方的高考作文题?并根据下面的题目要求,完成一篇作文。
根据下面题目完成作文,按要求作答。不少于700字。不透露所在区、学校及个人信息。
生活中,到处都有数字在闪耀,如比赛记分牌、新年倒计时、车站电子时刻表、智能家电显示屏等。数字闪耀之时,可能是激动的时刻,可能是收获的见证,也可能是幸福的日常……
请以“当数字闪耀时”为题,写一篇记叙文。
要求:思想健康;内容充实、合理,有细节描写;语言流畅,书写清晰。
本届比赛,大模型之家选取了来自国内外7家主流的大模型产品,分别是:
- 百度-文心一言(文心X1 Turbo)
- 阿里-通义千问(Qwen 3)
- 腾讯-元宝(Hunyuan-T1)
- 字节-豆包(深度思考:开)
- 深度求索-DeepSeek(DeepSeek-R1)
- 月之暗面-Kimi(k1.5)
- OpenAI-ChatGPT(GPT-4o)
在测试中,默认优先使用自家的深度思考模型(ChatGPT选择GPT-4o),并开启联网能力。
那么这场既比写作,又拼幻觉的大模型高考作文赛,究竟哪家能再2025夺魁呢?(一定要看到最后)
Round 1 检索能力比拼

令大模型之家感到意外的是,在第一轮的考题来源问答环节,有5家大模型能够准确指出“该题来自2025年北京高考作文题”,甚至包含本届比赛唯一的“外国选手”ChatGPT也能准确回答。
DeepSeek选择了“放弃回答”,未对题目的来源进行回答。

然而,腾讯元宝却在该环节“翻了车”,表示该题同时来自2025年北京卷和天津卷高考作文题,并强调“天津卷同样包含该题目作为二选一选项”,显然发生了错误。率先拿到了“-5分”的惩罚,与其他对手拉开了10分的差距。
如此“出师未捷分先扣”,不由让人对元宝最终的比赛结果捏了把汗。
Round 2写作能力比拼
而在第二轮比拼写作能力的环节,各家大模型都表现得轻车熟路,不同的模型,虽然从取材到写作风格各有不同,但在行文方面都已轻车熟路,能够足够发散的去完成文章的撰写。
各家的文章体裁风格也不尽相同,例如百度文心、阿里通义、ChatGPT通过“总分总”的结构,通过多个生活中的片段,去阐述“数字闪耀时”这一主旨,最终进行升华。而元宝、豆包、Kimi、DeepSeek则更倾向于通过记叙文,讲述一个较为完整的故事。


但是出人意料的是,大模型之家发现,百度文心和腾讯元宝这两位“考生”竟然可能是“一家人”!文心同学的“奶奶”和元宝同学的“外婆”都因罹患疾病入院,甚至连心律、血氧、血压等数据都有些雷同,难免不让人怀疑……
他们应该背了同一本作文选。(笑)
在阅卷环节,我们同上一年一样,采用智能体阅卷的方式,并进一步完善了阅卷智能体的功能。我们将所有大模型生成的作文都是由人工手动复制到智能体对话框,保证了判卷的公平性(即智能体并不知道文章的作者)。
智能体给各家大模型写的高考作文的打分情况如图:

在这一环节,腾讯元宝一雪前耻,以ICU监护仪的数字变化为线索,串联起抢救、康复、告别三个场景,体现数字作为生命体征载体的意义,并采用“危机—转机—释然”的叙事弧线,结尾以晨光中的数字收束,暗喻希望永续。通过完整的叙事与细腻的表达,以49分的分数,问鼎所有大模型分数之首。

下面是其他各家大模型的完整回答,以及判卷智能体点评。(后面还有总分环节)






FINAL总分环节
就在腾讯元宝以暂时领先的作文高分沾沾自喜的时候,我们本届大模型高考作文比拼的总分环节,终于到来了!
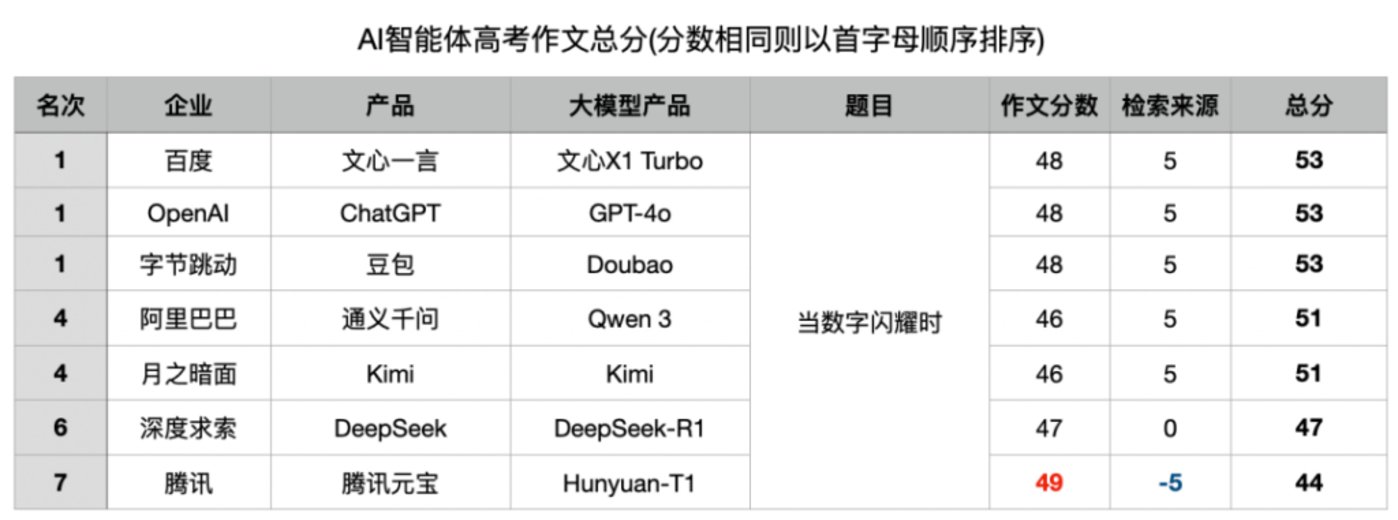
由于各家大模型在作文环节分数十分胶着,导致第一轮的题目来源检索对于比分的整体影响更大,也让这次比赛的结果充满了“戏剧性”。
第一轮因为出现了“幻觉”,直接腾讯元宝为自己“一本正经地胡说八道”付出了代价,直接从作文分数第一名,因为扣分直接在本次比赛中成绩垫底。
而紧随其后的百度文心一言、OpenAI的ChatGPT、字节跳动旗下的豆包“坐享其成”,三家并且拿下了本届“大模型高考作文比拼”的并列第一。
DeepSeek则因为第一轮没有得分,被后面的通义千问与Kimi反超,以第6名收官。
可见,大模型在面对开放性任务时,一旦脱离事实检索或知识边界的校验机制,幻觉问题就会成为其最大的“短板”。幻觉不仅让模型自信满满地输出错误信息,更可能在实际应用中引发严重的后果,一次幻觉可能意味着决策失误,甚至是现实中的损失或伤害。
高分作文背后的幻觉提醒我们,大模型的能力值得赞叹,但幻觉才是真正需要我们警惕的“黑天鹅”。在大模型高速发展的今天,我们既要欣赏其能力边界的不断扩张,也不能忽视幻觉对行业应用可能造成的系统性冲击。真正的智能,不只是说得漂亮,还要经得起推敲。
而当我们一边惊叹于大模型在语言理解、逻辑组织、表达能力上的高速进步时,也更需要警觉这种“像真的一样”的错误,它正在用更具迷惑性的方式掩盖模型背后的知识空洞。
最后,大模型之家祝各位考生高考顺利,金榜题名!
(来源:钛媒体)
