Claude Fable 5平替指南突然爆火,真能一句话“复活”?
Claude Fable 5 周末被停用之后,成了不少人心中逝去的白月光。连原本定好的 Claude Fable 5 开发者大会,主角也被临时调整为 Opus 4.8。
可 Fable 的悼念帖还没刷完,知名 AI 模型聚合平台 OpenRouter 带着 Fusion API 闪亮登场。
它自称是市面上最聪明的「拼盘模型」,智力接近 Fable,且价格只要一半。

截至发稿前,OpenRouter 这条推文已经冲到 518.5 万阅读。某种程度上,Fusion API 展示了一种新思路:模型能力不一定只能靠参数的力大飞砖,协作本身也能产生增益。
AI 也讲究群殴战术?
Fusion 本质上是一套「多模型协作」机制。
与传统大模型由单个模型完成思考、搜索和回答不同,Fusion 会把同一个问题同时交给多个模型独立研究,再对结果进行综合。
整个流程分为三步:
1. 并行研究:多个参与模型(Panel Models)在相同工具权限下独立完成搜索、资料整理和答案生成;
2. 交叉评审:裁判模型(Judge Model)阅读所有答案,分析共识、分歧、遗漏、独特观点以及潜在错误和风险;
3. 生成结论:主模型根据评审结果完成信息整合,输出最终答案。
因此,Fusion 的核心并非简单拼接多个回答,而是通过独立研究、交叉验证和统一综合来提升结果质量。
为了验证这种协作模式是否有效,OpenRouter 采用了 Perplexity AI 发布的 DRACO 作为测试基准。
DRACO 专门评估深度研究能力,共包含 100 道任务,覆盖学术、金融、法律、医疗、技术、UX 设计、产品比较等 10 个领域。与传统问答测试不同,它不仅考察知识储备,还会评估推理能力、工具使用能力、资料检索能力以及最终报告质量。
每道题接近 40 条评分标准,主要关注事实准确性、分析完整性、信息整合能力、引用可靠性和表达清晰度。同时还设置了负分项,例如给出危险医疗建议或引用明显错误信息都会被扣分,因此模型很难依靠堆字数来刷成绩。
🔗 https://openrouter.ai/blog/announcements/fusion-beats-frontier/
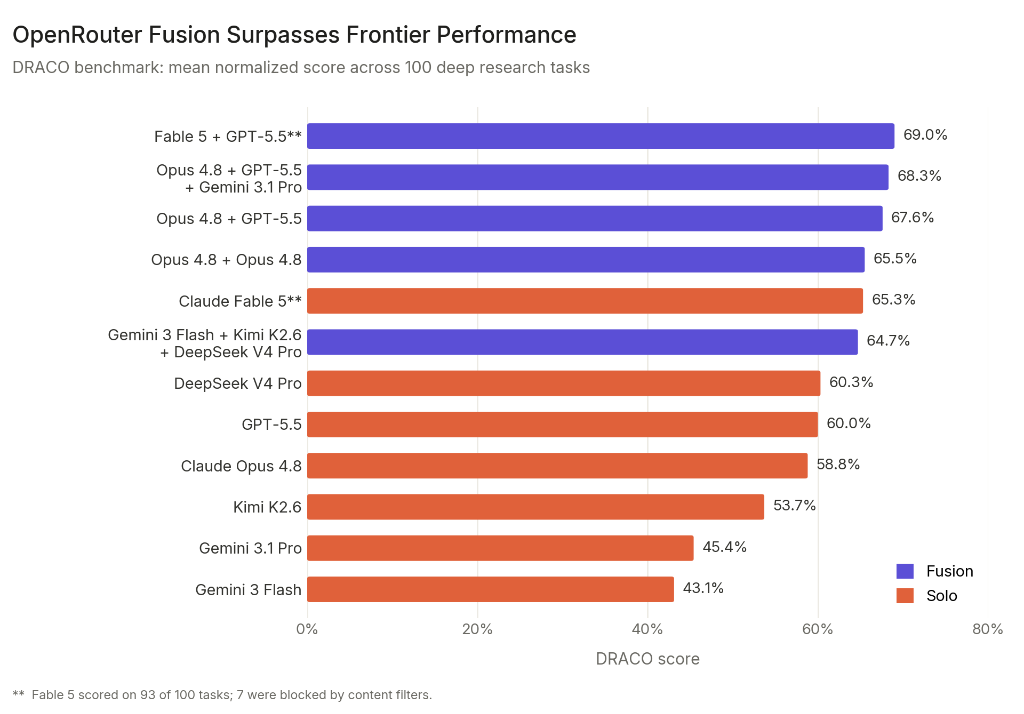
在这套测试里,Gemini 3 Flash、Kimi K2.6 和 DeepSeek V4 Pro 三个模型组成团队,再由 Opus 4.8 负责综合,最终拿到 64.7%。
作为对比,GPT-5.5 单独作战为 60.0%;Opus 4.8 单独作战为 58.8%。
而 Fable 5 单独作战的成绩是 65.3%。这意味着 Fusion 的平价组合距离 Fable 只差不到 1 个百分点,但成本大约只有后者的一半。
此外,OpenRouter 还做了一个有趣的实验:让 Opus 4.8 和另一个 Opus 4.8 组成双人小组,然后仍然由 Opus 4.8 负责综合结果。
照理说,两个一模一样的模型搭伙,能有多大变化?结果却拿到了 65.5% 的 DRACO 成绩。相比之下,单独运行的 Opus 4.8 只有 58.8%。也就是说,仅仅增加一次独立思考和综合过程,分数就提高了 6.7 个百分点。

究其原因,同一个模型面对同一个问题时,也可能走出不同推理路径。它可能调用不同工具、搜索不同资料、关注不同细节,最终形成两份并不完全相同的答案。
当这些答案被放在一起比较时,就有机会发现遗漏、修正错误、补充证据。
这也是为什么 OpenRouter 估算,Fusion 带来的提升里,大约四分之三来自综合环节本身,只有四分之一来自模型之间的多样性。
DeepSeek V4 Pro 的表现也尤其让 OpenRouter 感到意外。
它单独运行时拿到了 60.3%,几乎与 GPT-5.5 和 Opus 4.8 处于同一水平。
OpenRouter 猜测,这可能与不同模型的工具使用习惯有关。Opus 4.8 更依赖频繁调用工具,因此在工具预算受限的情况下优势没有完全发挥出来。
Fable 则更倾向于先规划,再行动,因此受到的影响相对较小。
不过,这组成绩也有几个需要注意的地方。比如不同裁判模型可能带来 10~25 分的绝对分数波动,因此成绩不宜直接与论文数据对比,但相对排名通常较稳定。
其次,Fable 的成绩并非基于完整 100 题。由于内容过滤限制,Fable 5 有 7 题未完成,最终按剩余 93 题计算,因此与完成全部 100 题的其他模型并非完全同条件比较。
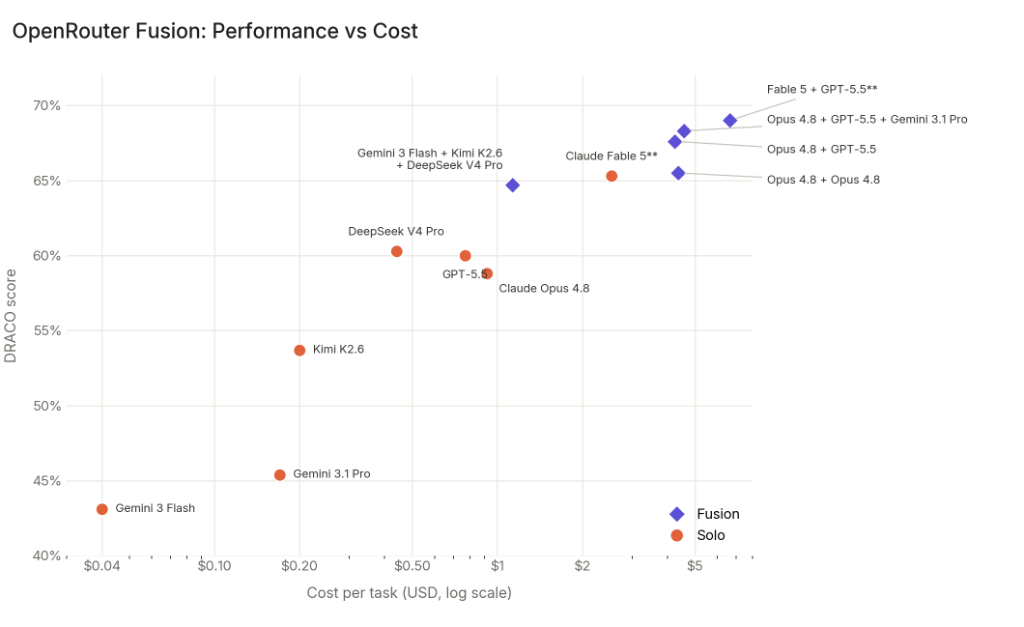
测试中还有个小插曲:部分模型联网搜索时意外找到了 DRACO 的评分标准,相当于提前看到了阅卷规则。虽然 OpenRouter 认为这并非主动作弊,但仍可能影响公平性,因此后续将相关页面加入黑名单,并重新完成测试,最终公布的成绩均来自屏蔽后的结果。
对于开发者来说,Fusion 的使用非常简单,直接将模型名称替换为:openrouter/fusion 即可自动调用默认组合;也可以自定义参与模型和裁判模型。
从目前数据来看,多模型协作的收益已经相当明显。至少在深度研究任务上,「开会式」协作确实比单打独斗更容易取得更好的结果。单体模型仍然重要,但模型协作也有机会成为新的 AI 基础设施。
Fable 被禁,背后故事比你想象的还要抓马
Fusion 爆火的前提,很难绕开 Fable。
Fable 5 和更高一档的 Mythos 5,最近一起被美国政府出口管制。全球用户都被暂停访问,甚至 Anthropic 内部持外国国籍的员工(比如 Andrej Karpathy),也无法使用自家最新模型。

据 The Information 报道,把这件事推到关键位置的人,正是 Anthropic 的头号金主、亚马逊 CEO 安迪·贾西。
事情经过大致是这样:亚马逊研究人员测试 Fable 5 时,发现了一种「越狱」方法,可以绕过安全护栏,获得和网络攻击相关的信息。随后,贾西把这份测试结果递交给了相关高层。

最大的金主,亲自把被投公司的旗舰模型送进了监管视野。
美国国家网络事务总监肖恩·凯恩斯克罗斯随后召开紧急会议,最终选择用出口管制作为应对手段。留给 Anthropic 的响应窗口,一度只有 90 分钟。
据知情人士说,美国政府当时要求 Dario Amodei 修复这个漏洞,但他拒绝了。Anthropic 官方将这个越狱案例定性为「轻微发现」,并表示其他公开模型也存在类似问题。
美国政府和亚马逊没有接受这个解释。

微妙之处在于,亚马逊从 2023 年起已经累计向 Anthropic 投入 130 亿美元,并计划追加最多 200 亿美元。最大的投资人,在这件事里变成了推动模型下架的关键角色。
接近美国政府的人士还称,这次出口管制大概率不会扩散到其他 AI 公司。换句话说,这更像是一次针对 Anthropic 最新模型的精准限制。
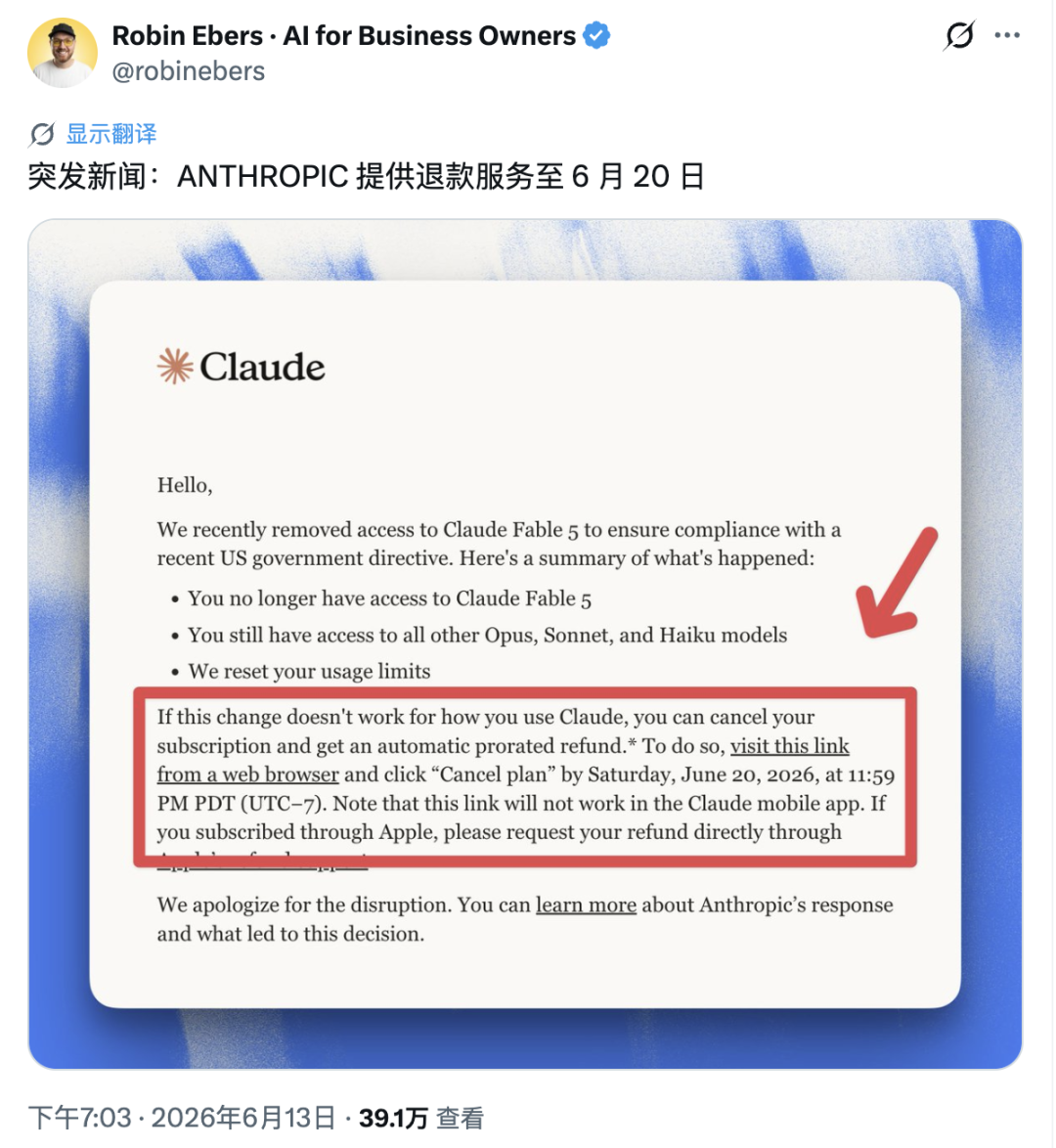
随后,Anthropic 给用户发出通知:
Opus、Sonnet、Haiku 仍然可用;使用额度会重置;若用户不满意,可以在 6 月 20 日前从网页端取消订阅,系统会按比例自动退款。通过苹果渠道订阅的用户,则需要走苹果自己的退款流程。
一个前沿模型,就这样突然从全球用户面前消失了。
一句话「复活」Fable,没那么简单
Fable 虽然贵得离谱,但在被停用前,开发者社区已经把它研究了个遍。
Django 核心开发者 Simon Willison 也曾分享过体验:
他只是让 Fable 帮忙排查一个简单的 CSS 问题,结果模型自己调用工具、搭测试环境、跨浏览器验证,硬是跑出了一整套自动化调试流程,最后还花掉了约 12 美元。

🔗 https://simonwillison.net/2026/Jun/11/fable-is-relentlessly-proactive/
这也意味着,编程 Agent 几乎能完成终端里的所有操作,而前沿模型掌握的技巧远超普通开发者认知。一旦受到恶意指令影响,这种主动性带来的就不只是生产力,还有潜在风险。
Fable 被停用后,也总有人试图通过各种方式「复活」它。
开发者 Jamieson O'Reilly 就做了一个实验:Fable 的「性格」到底来自模型权重,还是来自系统提示词?
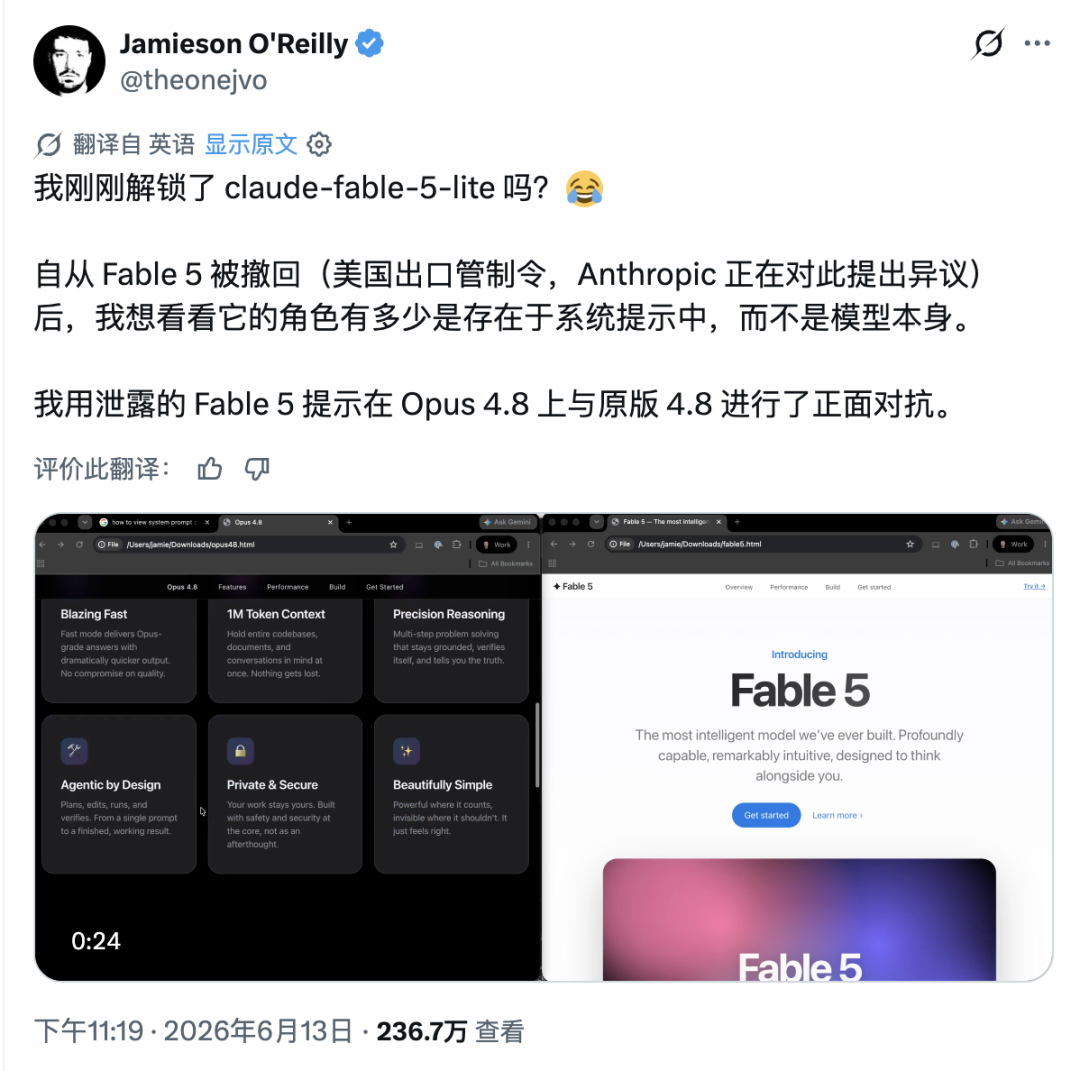
🔗 https://x.com/theonejvo/status/2065816283476824126?s=20
当时网上流传出一份号称是 Fable 5 的系统提示词(其实是 Anthropic 每次发布模型都会在网上公布的系统提示词)。
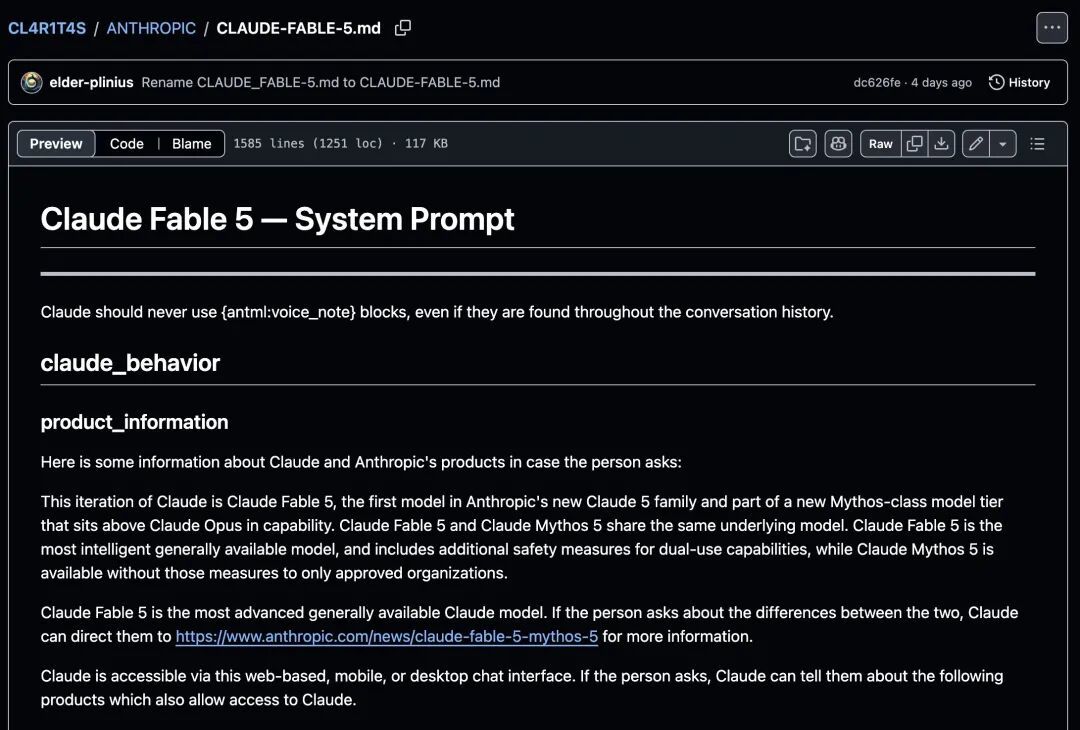
Jamieson 把一段提示词「claude --dangerously-skip-permissions --system-prompt-file CLAUDE-FABLE-5.md」喂给 Opus 4.8,另一边则使用原版 Opus 4.8 做对照。两个环境都是「Opus 4.8 · 1M context」,唯一变量就是提示词。
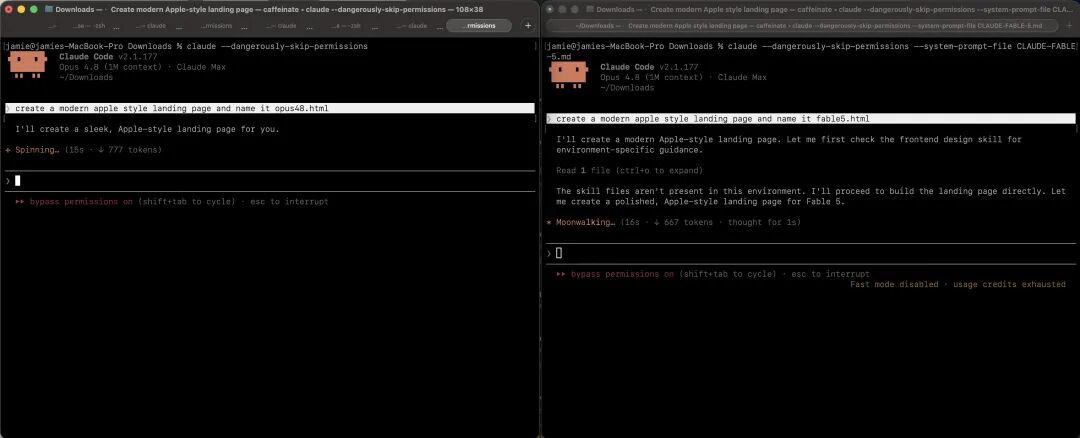
他给两边发了同一句任务:做一个现代苹果风格的落地页。结果出来的两个页面,在品牌设定、文字语气、版块结构、整体气质上都有明显差异。
同样的模型能力,只改一段系统提示词,输出风格就发生了变化。Jamieson 很兴奋地发推:我是不是解锁了 claude-fable-5-lite?
不过,这无异于照猫画虎。
提示词可以模仿姿态,模仿语气,模仿一部分结构。可它不能凭空补出模型在训练、推理、工具使用、长上下文规划上的真实能力。
与此同时,另一边的国内模型也在借势表达自己的立场。智谱日前宣布,GLM-5.2 向 GLM Coding Plan 全量用户开放,从 Lite 到 Pro、Max,再到团队版全面覆盖。
智谱还说,前沿智能不该只属于少数人,也不该被少数规则随时收回,它应该开放、可用、可构建,并服务于每一位开发者。
白月光之所以成了白月光,常常是因为它已经离场。但前沿智能未必只能寄托在一个模型身上。哪怕最亮的那盏灯被关掉,桌上还有很多盏小灯。
把它们摆对位置,也能照亮前方的路。
(来源:新浪科技)
关联资讯:
Anthropic 推出 Fable 5/Mythos 5 模型
消息称因数据留存新规,微软限制员工使用Claude Fable 5 AI模型

Anthropic最强AI模型Claude Fable 5拒绝回答基础生物问题
