终于,具身智能的“真机数据”难题有了新解法

©️深响原创 · 作者|林之柏
2026年,具身智能迎来新一轮空前热潮。
春晚舞台上宇树“人机共武”、魔法原子“实景演出”相继出圈,荣耀“闪电”则在北京亦庄人形机器人半程马拉松刷新人类男子半马世界纪录,公众热情被一再点燃。资本侧同样反应积极,中国市场上估值超过100亿人民币的具身智能公司已超过20家。技术也在持续突破:从VLA到世界模型的迭代、到灵巧手的进展,具身智能逐步从Demo(演示)走向Deployment(实际部署)。
但不得不说的是,热闹背后,一个核心难题始终横亘在行业面前:高质量真机数据极度匮乏。
中国信通院报告明确指出,具身智能是一个“由数据驱动的智能系统”。对于具身智能而言,数据是决定行业发展上限的关键变量。如果缺乏高质量数据,机器人就无法实现精准操作和场景泛化。
国家发改委相关新闻发言人也在最近的发布会上表示,下一步将加快具身智能训练基础设施建设,更好地支撑数据采集和“大小脑”模型训练,以提升具身智能在不同场景的通用能力。
而且不同于大语言模型能规模化爬取文本数据,具身智能所需的描述人类运动、精细操作的真实数据少且难得。目前,全球文本数据早已达到万亿token级别,但高质量真机操作数据仍停留在百万小时规模。
在这个战略重地,成立于2025年2月、已累计完成数亿元融资的灵御智能选择了一条另类的路线:它不加入本体长相的内卷,而是定位为做面向具身智能的高精度物理世界数据基础设施提供商,为行业提供高质量的本体和数据服务。


具身智能的数据困局与
「不可能三角」
具身智能的数据困局由来已久,这是行业运行惯性、早期技术局限等一系列因素共同造成的。
目前,业内获取数据的方式主要有四种。
第一种是仿真数据,即在模拟环境中生成机器人操作数据。这种方式最大问题是“虚实鸿沟”,仿真环境就算再精细,也很难准确还原现实世界的各种物理细节,比如物体之间的摩擦力、传感器运行时的噪声等。这些细节误差,可能导致机器人无法适应真实工作环境。
第二种是人类行为数据,主要来源于视频,让机器人学习人类的操作动作。但人类的身体结构和机器人的机械结构存在差异,这就形成了“构型鸿沟”:人类的动作很难直接映射到机器人身上,比如手指灵活度、肢体协调性,数据实用性大打折扣。
第三种是人类示教数据,通过手持设备、动捕系统,或者拖动机械臂进行操作示教。这种方式更贴近机器人运动习性,但依然无法完全解决“构型鸿沟”,而且采集效率低,很难实现规模化。
第四种是真机遥操数据,由人类远程控制机器人完成任务,同时记录整个操作过程。这种方式优缺点都很明显:优势是更接近真实物理世界,获得更高质量、多模态、可泛化的数据;短板在于采集成本高。
市面上品质较高的真机遥操机器人售价普遍偏高,按照行业通用的一年使用期计算、加上各类杂项成本,单任务每次的数据成本大概在3-5元,这还没算大量设备、场地、操作人员开销。

面对数据困局,巨头与学术界的探索同样未能提供公用解法:
比如特斯拉采用的封闭生态模式,数据质量够硬,但仅供自身使用;斯坦福大学研发团队推出的ALOHA方案,借助远程操控系统,由用户同时控制底座和两个机器手臂来完成更多样的任务,数据精细,只可惜更偏向实验室场景,难以满足工业级需求;国内的本体厂商则大多采用重资产模式,自搭场地、系统,投入大、效率偏低。
上述种种数采模式的优劣,业内争议不断,但无论哪种路线,似乎都无法突破具身智能数据的“不可能三角”:高质、高效、高性价比。
正因此,行业急需一种“工业化、标准化、低成本”的数据生产方式——而这,正是灵御智能试图解决的核心问题。

打破「不可能三角」
灵御智能的另类解法
不同于很多强调“拟人化”表达、通用展示能力的机器人企业,灵御智能不执着于“做一个最像人的机器人”,反而关注一个更实际的问题:如何让机器人稳定、高效地进入真实任务场景,持续产生高质量数据。
这种差异化定位,让其跳出了主流赛道,在“高质、高效、低成本”这三个看似矛盾的需求之间,找到平衡点。
首先是提升效率,更注重动作采集执行速度和稳定性。
在第二届中关村具身智能机器人应用大赛上,灵御的机器人在每个实际场景中的操作时间,都是同类竞品的30%甚至更低,展现出极强的执行速度。
而得益于更强的动作完成能力、力控柔顺性,灵御的机器人具备更高稳定性。力控柔顺的机器人,能像“人”一样自带细腻“手感”,敏锐感知细微的受力分布、找准发力点。这让机器人更自如地应对复杂任务,单日有效采集时间达10小时以上,任务完成条数超800条,大大提高采集效率。

第二届中关村具身智能机器人应用大赛测试项目
其次是成本控制。灵御智能的核心产品TA机器人售价在10万-20万元区间,加上人工和各类杂项成本,单年成本控制在30万元以下,每小时成本仅100-150元,单任务每次的数据成本约0.6元,和umi数据采集成本相当。
为什么灵御智能可以做到“低成本”?关键有两点。
一是不盲目死磕昂贵硬件,而是从算法层面寻找突破口,这与SpaceX用不锈钢替代钛合金的思路很像,主打“花小钱办大事”。
比如受力监测,业内通常会给每个关节配备谐波减速器和六维力传感器,就像在机器人身上安装一个高精度“电子秤”,靠物理手段监测不同运动状态下的受力变化,数据极尽精细,但硬件成本很高。
灵御智能则采用低减速比的行星减速器,通过监测电机电流变化来估算受力。这套方案胜在“实在”:电流反馈的物理精度不如传感器,但配合500赫兹的控制频率,系统每两毫秒就能获取一次受力数据,实时调整刚度;再加上高精度标定和全局逆解算法,用更高性价比方案,实现了全柔性力控下的毫米级定位精度。
齿轮背隙优化也是同理。传统机械方案要做到极小背隙,不仅要把齿轮的加工精度拉满,中心距、预紧力甚至需要逐台人工微调校准,成本高,还容易受温度变形影响出现故障;灵御智能用廉价传感器监测齿轮相对位置,通过算法实时补偿背隙,最终实现的等效精度反而更高。
这些做法,其实是对机器人行业“硬件为王”思维的修正:过度依赖高端机械部件来提高数据精度,不仅推高了成本,还限制了生产力。算法+硬件的相互配合,节省成本之余,也并不会影响数据稳定性。
二是在产品设计逻辑上,始终以数据采集效率为核心进行优化。
比如砍掉脖子关节,用广角摄像头提供接近人眼的大视野,操作员无需控制机器人扭头,就能覆盖全部视野;采用模块化设计,最容易磕碰损坏的小臂和手腕部分可以快速拆卸更换、无需整机返厂大修,大幅降低了维护成本和停机时间。

此外,还有更为关键的高数据质量。
灵御智能TA机器人集中发力时间、空间和信息密度三个维度。
时间维度上,TA机器人实现了S100、x86、激光雷达、相机全硬件亚微秒级同步,从系统底层保证多传感器数据在统一时间轴上的高度一致性,杜绝“相机已经拍到动作,传感器还没记录受力”等情况。
灵御智能联合创始人、首席科学家莫一林透露,团队把端到端的流程拆分成20个环节,每个环节的耗时都用示波器精确测量。
同时,相机提供严格的曝光开始时间、6 路相机触发实现纳秒级同步,从相机曝光到数据进入内存的整体延迟最低可控制在40毫秒。为此,灵御智能从CMOS选型阶段就与供应商联合开发、定制曝光时间等参数,从源头保证时间精度、对齐多模态数据。相比之下,很多公司仍在使用通用USB摄像头、内置预处理芯片,无法精准把控延时效果。
这和苹果、特斯拉等厂商的思路是一致的。苹果iOS生态的流畅性、稳定性为什么一直有口皆碑?正是因为它从芯片、系统到镜头等零部件一手抓,高度集成、高度统一。
信息密度上,TA机器人对力控数据、头部4k双目视觉数据、腕部2k双目视觉数据和遥操作眼动数据全覆盖,整体数据topic数量为行业最多。
空间精度上,TA机器人实现了0.1mm的重复定位精度和1mm的绝对精度,均处于行业领先水平。重复定位精度保证了单台设备在重复执行任务时的稳定性,绝对精度则确保不同机器人之间的数据一致性,避免了因设备差异造成偏差。
不得不说,TA机器人的高质量数采,正正解决了行业的大难题。
此前业内很多公司都存在重复定位精度不足、不同设备采集数据不兼容、过于追求单一维度的精确度等问题。好不容易采集到数据,要么动作、受力存在偏差,要么精度达标但传感器数据不同步、信息残缺,以至于数据看起来丰富,但无法准确反映真实操作场景。
更重要的是,在传统操作思路里,数据采集、上传、清洗、标注、模型训练等环节容易出现脱节,低质量数据不仅无法提高训练质量,还会成为“负资产”。
而灵御智能对空间、时间和信息密度的兼顾,能最大限度避免数据脱节、信息单一,且数据集无需额外校准,可直接用于模型训练,既节省了后续成本,也真正实现了数据的可泛化价值。

灵御智能数据采集平台
立足于效率、成本和数据质量三重支撑,灵御智能显然迈出打破「不可能三角」的关键一步。在这基础上,灵御智能得以更进一层:构建“数据飞轮”,形成难以替代的核心竞争力。
过去,大部分机器人数据采集都属于纯投入模式:企业需要专门搭建采集场地、组织人员、运行设备,再把采集到的数据回流给模型团队,流程繁琐、效率低下。而灵御智能改变了这一逻辑——在它的方案中,机器人本身既是执行终端,也是数据入口。
在灵御智能的端云协同架构中,云端并不是简单承担远程控制角色,而是与端侧实时控制、本体执行、任务调度和专家模型形成协同。机器人在真实场景中完成任务的同时,视觉、力控、关节状态等多模态数据持续回流,进入清洗、标注和训练流程,反过来推动模型能力迭代。
其中,灵御TA机器人承担着进入真实场景的物理执行角色,自研的低延迟通讯架构负责连接云端智能与机器人本体,而高质量真机数据飞轮则持续反哺模型训练和能力迭代。
这就形成了“部署—数据—训练—进化”的完整闭环:部署规模越大,真实场景越丰富,系统获得的数据就越多;数据越多,模型能力就越强,进而提升机器人的执行能力,反过来又能采集更多高质量数据,实现自我强化。
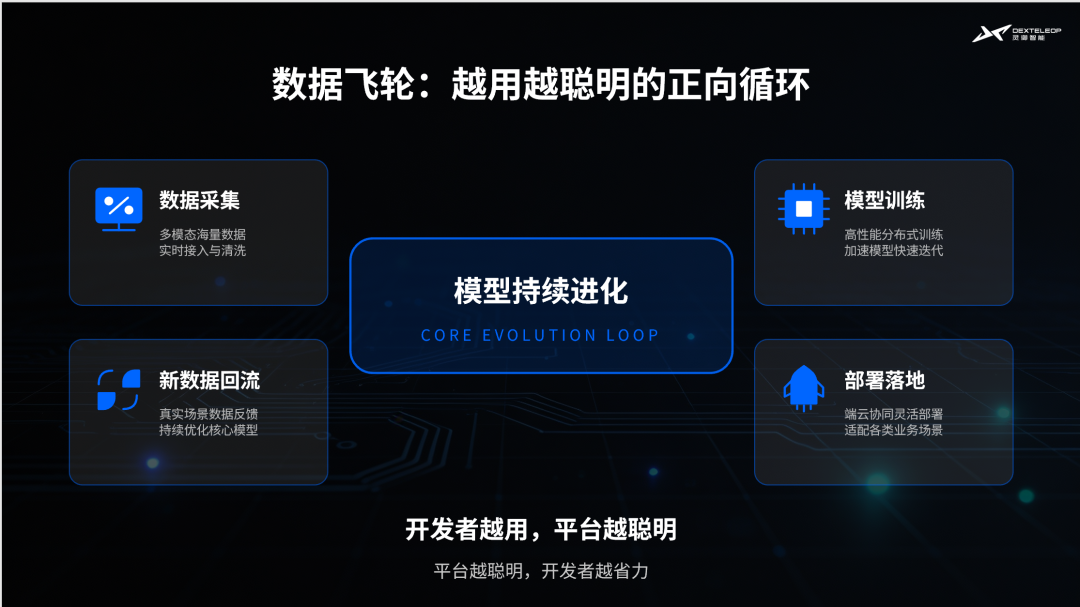
“数据飞轮”的成型,离不开全链路的协同能力,这是灵御智能独有的竞争壁垒。
行业内很多公司能做好机器人本体,但不一定能把云端AI稳定接入真实物理任务;有些公司能做好模型,但缺乏低延迟通讯技术和可落地的执行本体,而灵御智能实现了各环节的深度协同。
灵御智能和英特尔的合作是典型例子。此前,英特尔已开始使用灵御机器人开展模型训练和数据采集,并提供云边协同、数据处理与算力支持。双方合作跑通了“数据—模型—执行”的闭环雏形:从真实任务中采集高质量数据,用于云端模型训练,再将优化后的模型下发到机器人本体,进行执行验证。
往后,类似的合作案例可能会越来越多,这也印证了其技术路线的可行性。

灵御智能 X 英特尔合作测试项目

从卷模型到卷数据
打破具身智能能力上限
随着具身智能逐步告别概念炒作和样机演示,进入规模化量产、商业化落地的关键阶段,行业也从“卷模型”转向“卷数据”。竞争重心正发生彻底改变,决定系统能力上限的,不再只是模型本身,而是它是否拥有足够丰富的真实场景数据。
这种产业演进轨迹,与自动驾驶行业高度重合。正如特斯拉的核心壁垒从来不只是自动驾驶算法,还有其庞大的车辆部署规模,持续采集海量、真实路况数据。这些数据,才是调优算法应对极端天气、突发路况等长尾问题的关键。
具身智能正走向类似的路径:机器人只有走进各种复杂环境,持续与真实世界交互,才能获得足够的数据。
这便能看出灵御智能的独特性:形成从设备、部署到数据交付的完整闭环,服务于科研机构、数据采集中心及复杂非结构化场景客户,推动机器人数据从实验验证走向标准化、规模化生产。这让其成功获取了物理世界的数据入口,为机器人进入更复杂、更真实的任务环境提供数据基础设施。
就像大模型时代的Scale AI,其价值不仅仅在于提供数据标注服务,更在于帮助行业建立了标准化的数据生产体系;在具身智能的领域,行业也需要灵御智能这样的企业填补基础设施层的空白。
灵御智能这种成为“基础设施”的决心也贯穿在CEO金戈设定的2026年度目标中:全年出货量突破800台机器人;完成商业闭环验证,在1-2个真实工作场景中,证明机器人能够为客户带来正向ROI;构建数据资产,一年内为行业提供至少百万小时、经过标准化处理、可直接用于模型训练的高质量真机数据集。
灵御智能机器人应用于工业物流场景
这三个目标其实是环环相扣的:只有机器人部署规模上去,才能产生足够丰富的场景数据;只有跑通商业闭环,才能证明基础设施的商业价值;只有数据飞轮转起来,才能发挥基础设施的网络效应——而这背后,或许也藏着整个具身智能行业未来几年的真实发展方向。
未来,真正成熟的机器人,不会只存在于实验室和演示视频里,它们会走进餐厅、仓库、医院、工厂、商场,持续与真实世界发生交互;它们也会像今天的联网汽车一样,在工作过程中不断学习、不断进化;而每一次抓取、移动、任务失败与修正,都会成为下一轮模型迭代的养分。
届时,机器人产业真正重要的,可能不再是“制造机器人”,而是如何建立一张持续连接物理世界的数据网络。谁能率先建立数据基础设施,谁就更有机会找到这张数据网络的入口。
(来源:新浪科技)


