梁文锋与DeepSeek的十万亿美元棋盘

新智元报道

【新智元导读】DeepSeek正用开源、降价和底层架构创新,重画AI硬件生态的成本曲线,把目标指向十万亿美元产业与AGI的星辰大海。
DeepSeek最近动作频频。
先是5月22日,彭博社爆出他们正在推进700亿元人民币的融资,投前估值高达450亿美元。

同一天,DeepSeek官宣V4-Pro API永久降价75%——把促销价直接焊死成正价。
一边向投资人要钱,一边向开发者让利。这操作,多少有点让人迷糊。
那么问题来了,DeepSeek到底要靠什么赚钱,而且还要赚很多很多钱?
毕竟,AGI可不是能口嗨出来的。
这正是x博主@bookwormengr最近研究的一个狠问题。
他在长文《DeepSeek's 10 trillion USD grand strategy》中提出一个非常大胆的判断:DeepSeek真正的星辰大海,可能不是卖编程套餐,不是卖语音助手,而是参与塑造一个价值10万亿美元级别的AI硬件生态,并在这个生态里冲击万亿美元级估值。

仔细读完@bookwormengr的这篇万字长文,你会发现:梁文锋不是疯子,他是棋手。
而且是高手,他下的是一盘价值10万亿美元的棋。

英雄之旅
一场反共识的技术长征
回顾DeepSeek的成长轨迹,用「英雄之旅」来形容不为过。
在所有人都在堆Dense模型、卷参数量的时候,DeepSeek去啃最难训的MoE(混合专家模型),用更少的计算量撬动更高的智能。
别人用PPO做强化学习,他们从第一性原理出发,发明了更便宜的GRPO算法。
别人还在讨论RLHF的天花板,他们已经跑通了RLVR(基于可验证奖励的强化学习),把推理能力拉上了新台阶。
MLA、DSA(解耦稀疏注意力)、mHC(流形约束超连接)、CSA和HCA——这些都不是论文里的花拳绣腿,每一项都在回答同一个问题:怎样在有限的硬件条件下,榨出最大的AI算力?
英雄从来不是一开始就知道自己的使命。他在路上不断战斗、不断发现,最终找到了自己的终极宿命。
DeepSeek的宿命,从来都不是卖API套餐。
一道有趣的数学题
KV Cache的秘密
让我们从一个具体的数字开始讲这个故事。
打开kvcache.ai的在线计算器,输入100万token上下文、8bit KV精度、16bit索引精度,你会看到一组让人瞠目的对比:DeepSeek V4仅需 5.48GB HBM。
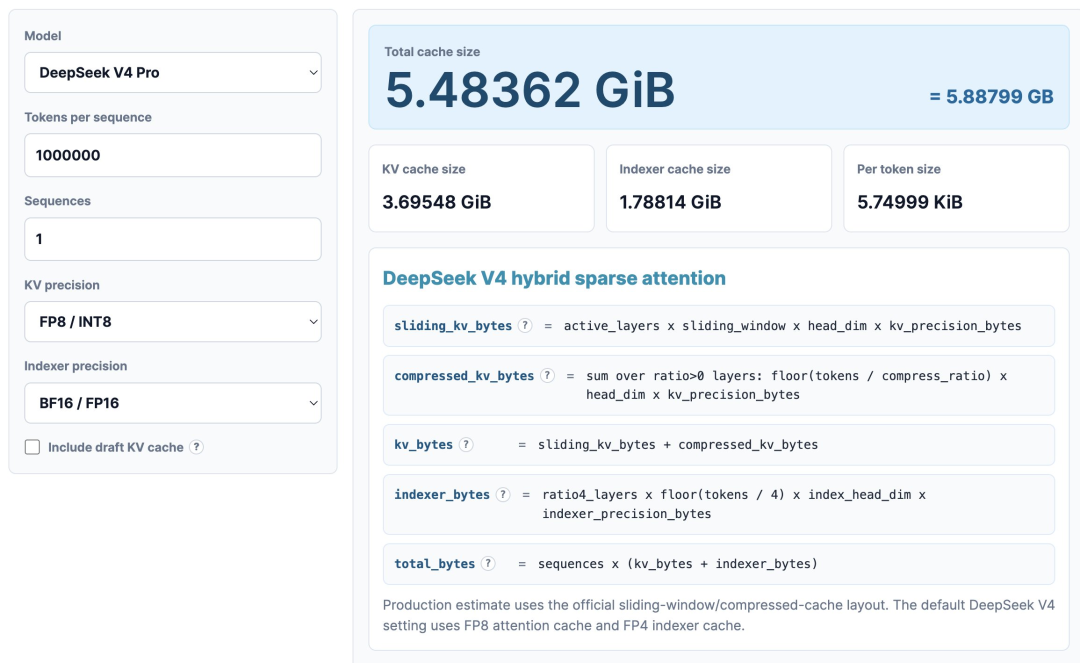
相比之下,其他顶级开源模型则动辄需要 60GB HBM。
注意,DeepSeek V4是一个1.6万亿参数的模型,体量远大于其他开源模型,KV Cache占用却只有它们的零头。
这意味着DeepSeek可以把缓存命中的价格定到一个令人发指的低位——V4-Pro缓存命中价仅0.025元/百万Token,不到Claude Sonnet 4.6同类价格的3%,而且可以持续缓存数小时。
永久降价后,输入缓存未命中3元/百万Token,输出6元/百万Token,全部是原价的四分之一。
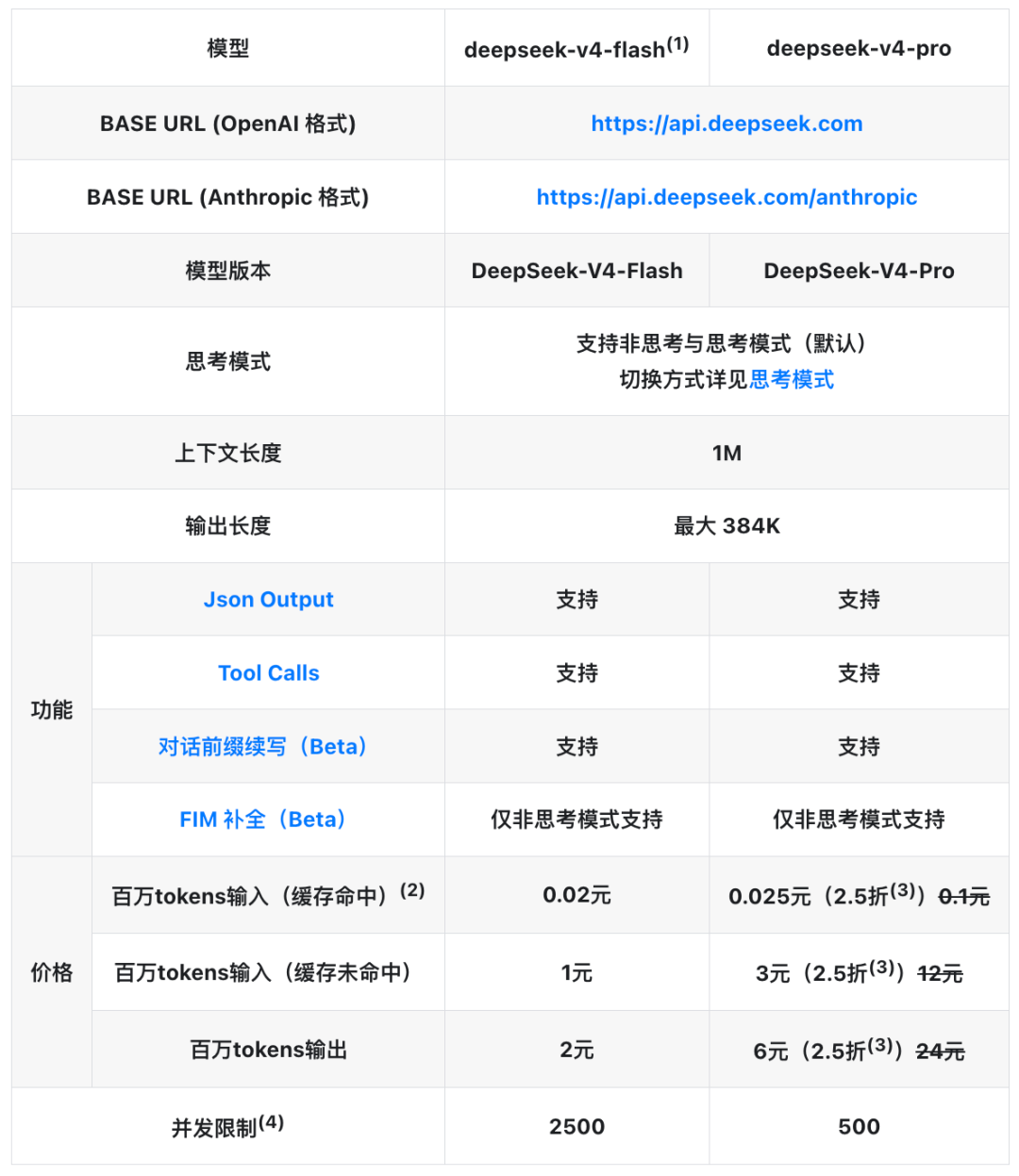
梁文锋两年前就说过DeepSeek的定价哲学:我们的原则是不贴钱,也不赚取暴利。
现在看来,他说的是实话——当你的KV Cache只有别人的十分之一,你的成本就是别人的零头。
但更深的问题是:这个红利到底流向了哪里?
十万亿美元的棋盘
硬件生态的重构
答案藏在三个缩写里:SSD、LPDDR、HBM。
第一层:SSD与NAND闪存。 KV Cache被压缩到极小之后,可以高效地卸载(offload)到SSD上,等需要时再快速加载回HBM。
DeepSeek在Dual Path论文中还专门优化了从SSD加载KV Cache的速度。这直接减少了对昂贵HBM的依赖。
谁是SSD和NAND闪存的大玩家?DeepSeek每压缩一分KV Cache,就在为NAND和SSD创造一个庞大的新市场。
第二层:LPDDR内存。SGLang团队发表的研究表明,LPDDR完全可以作为「权重暂存区」——模型权重先放在LPDDR里,需要时再流式传输到HBM中,大幅缓解HBM的容量压力。

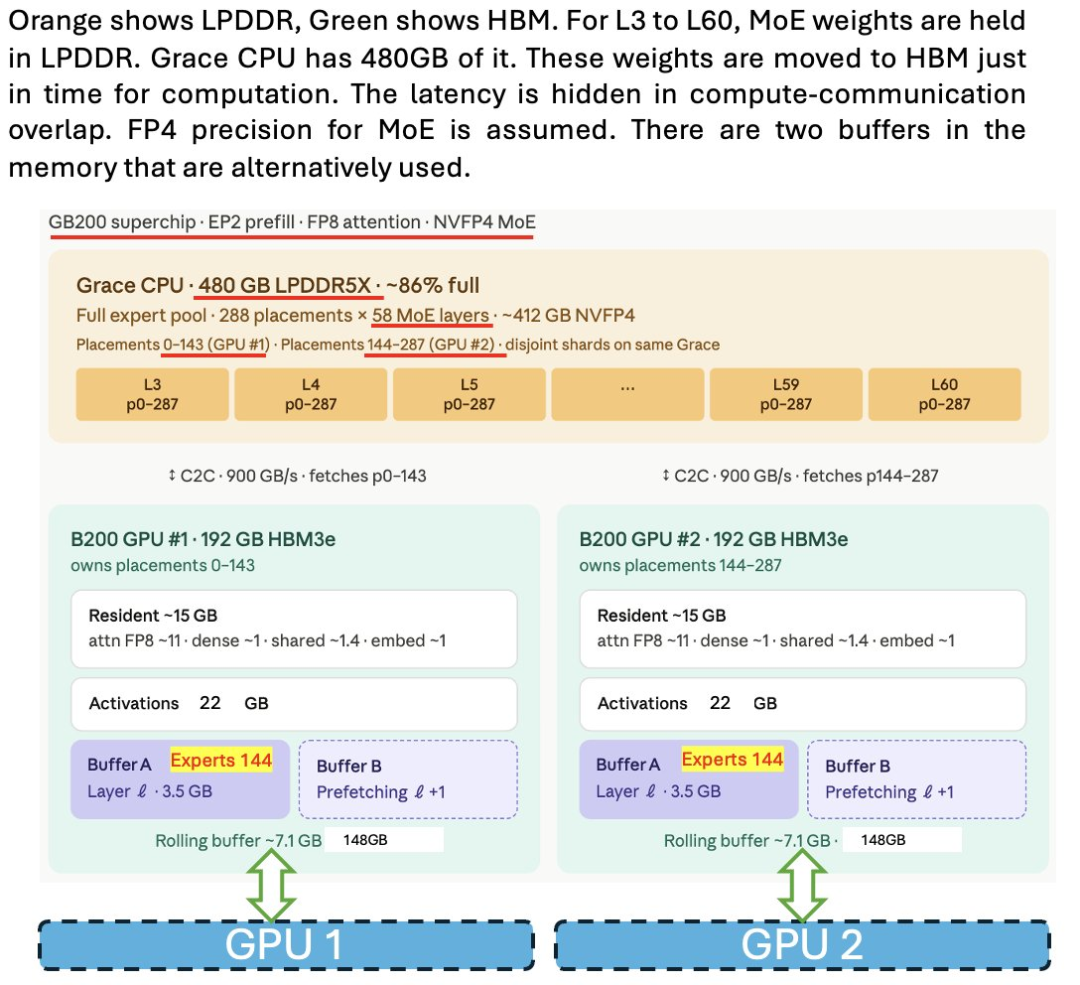
DeepSeek的MoE架构天然适配这个方案:专家数量多、权重可以4bit量化,流式加载非常高效。
谁在做LPDDR?国产速度只落后0.5代,密度落后1代,追赶的脚步已经很近。
第三层:GPU/ASIC的减压。 Engram模块用LPDDR中的哈希查表替代Transformer的前向传播计算,本质上是用每比特成本极低的「内存读取」替代每比特成本极高的「GPU运算」。
这对中国AI芯片意义重大——由于EUV光刻机受限,国产GPU在原始FLOPs上落后。但如果你能用更多的便宜内存来替代更少的昂贵算力,那这种「换道超车」就变得合理了。
再加上TileLang——DeepSeek投资的跨硬件内核编译框架,可以让一套计算代码同时跑在多种硬件平台上,相当于绕过了「CUDA护城河」。国产芯片厂商,都有可能因此获得生态层面的突破。
现在你明白了吗?DeepSeek做的每一项技术创新,都在指向同一个方向:降低对顶级硬件的依赖,让中国现有的存储、芯片、网络生态变得足够用,甚至好用。

@bookwormengr算了一笔大账:全球AI相关股票的总市值早已远超10万亿美元。
如果DeepSeek能帮助中国构建一个等量级的AI硬件生态,它自己在这盘棋里拿到1万亿美元的估值,完全合乎逻辑。

不赚快钱的逻辑
回头看DeepSeek的所有「不做」——不做多模态(V4.1才开始试水图像和音频)、不做语音模型、不做视频模型、API一降再降——就说得通了。
不是「不会赚钱」,而是「暂时不屑于赚这种钱」。
@bookwormengr提出了一个精彩的类比:OpenAI拿到了AMD和Cerebras的股权认购权证,只要达成算力采购里程碑就可以低价买入股票。这本质上是「用承诺换股权」——你帮我造芯片,我给你订单,我们一起把蛋糕做大。

DeepSeek完全可以复制这个模式。
只不过它面对的不是AMD和Cerebras,而是整条国产AI硬件产业链。
梁文锋是量化基金出身,被称为「 Jim Simmon的忠实粉丝」。这样一个人,不可能不懂资本运作的精妙之处。
事实上,融资消息传出前,他已经在2026年4月完成了一次关键的股权调整——通过直接与间接持股控制公司约84.29%的股权,表决权100%。

宁德时代投DeepSeek——它要锁定未来AI数据中心的储能订单。京东、网易入局,各有各的战略诉求。
国家大基金下场,更是把DeepSeek定位成了国家级AI基础设施。
这些投资者看到的,不是一个卖API的小生意。他们看到的,是一个可能重塑全球AI硬件格局的战略支点。
终极使命
大规模强化学习与AGI
但如果你以为DeepSeek的终点是「做中国AI硬件生态的发动机」,那可能还是低估了梁文锋。
据彭博社报道,梁文锋在投资者会议上明确表态:DeepSeek的主要目标是推动技术边界,追求AGI。
硬件生态是手段,AGI才是目的。
逻辑是这样:当更多硬件选择变得可用、当算力需求本身被技术创新大幅压低,DeepSeek就能以更低的成本启动更大规模的训练——特别是强化学习(RL)后训练和递归自我改进(RSI)。
大规模RL意味着模型需要生成海量的推理轨迹——万亿级token的生成量,计算成本极其恐怖。而100万上下文的长程任务,要求轨迹本身也足够长。
如果没有极致的硬件效率优化,这种训练根本跑不起来。
RSI则更加大胆——让AI自己设计实验、执行实验、分析结果、改进自身。这是一个试错密度极高的过程,对算力的需求是无底洞。
但如果DeepSeek通过重构硬件生态把算力成本打下来,这条路就变得可行。
从MoE到MLA,从DSA到CSA,从Engram到TileLang,从KV Cache压缩到LPDDR流式加载——所有这些创新,最终都汇聚到同一个终点:让AGI的训练从「烧不起」变成「烧得起」。
梁文锋与DeepSeek的星辰大海,从来不是海面上的浪花,而是洋流本身。
(来源:新浪科技)
关联资讯:
DeepSeek推进700亿元融资,梁文锋承诺坚持开发开源AI模型而非追求短期商业化目标

