谷歌用 AI“杀死”谷歌,这场发布会看得人缺氧
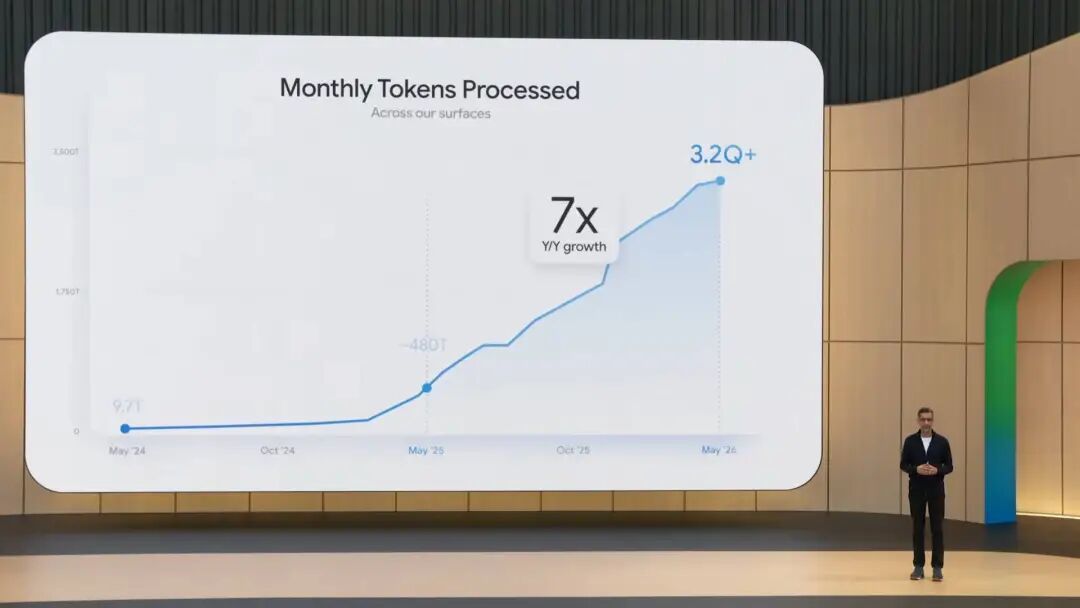
Gemini App 月活超 9 亿,月 Token 处理量每月 3200 万亿,Nano Banana 生成超过 500 亿张图片……
在今天凌晨刚刚结束的 Google I/O 大会上,Google CEO Demis Hassabis 上来就抛出了这些数字。
过去一年,AI 成了所有行业的主旋律,Gemini 在 Google 的定位,也开始从一个独一的 App,成了所有 Google 产品里的最重要的 AI 底层能力。
这次发布会也先从模型开始,进一步带到 Coding 和 Agent 产品。
Gemini Omni 把 Google 的视频生成推向「世界模型」方向,Gemini 3.5 Flash 则是和 AI 编程工具一起推向 Agent 开发平台。
这两个能力随后进入 Google 的完整生态,搜索、Gemini App、Flow、Spark、Chrome、XR 眼镜和电商场景。
Gemini Omni 登场,视频界的「Nano Banana」时刻来了
发布会最先被重点展开的是 Gemini Omni。我们做了一组和 Seedance 2.0 的对比视频,看看两者的差别。
Google 则是将 Gemini Omni 描述为一个能够「从任何输入创造任何内容」的新模型。
它把 Gemini 的推理能力与 Google 既有的生成式媒体模型结合起来,目标是提升模型对世界的理解、多模态生成能力和编辑能力。

Google 强调,Veo、Nano Banana、Genie 等模型已经能生成视频、图片和交互式模拟,但 Gemini Omni 更进一步,开始处理动能、重力等更接近物理世界的问题。
发布会现场展示的案例包括蛋白质折叠解释视频。用户只需要输入类似「生成一个关于蛋白质折叠的黏土动画解释」的提示,Omni 就能把抽象科学概念转化成视频内容。

它还支持更自然的视频编辑。用户可以上传自己的视频,再用对话方式修改风格、加入元素、调整细节,甚至把一个普通圆形转成黑洞,把夜晚散步场景变成更具戏剧感的画面。

Google 的说法是,Gemini Omni 先从视频开始,之后会逐步走向「任意输入到任意输出」。这也是 Google 一直把 Gemini 设计成多模态模型的原因。
首个 Omni 家族模型 Gemini Omni Flash 已在上线到 Google 产品中,Omni Pro 会在之后公布更多信息。Gemini App 中的 Omni 功能也面向 Google AI Plus、Pro 和 Ultra 订阅用户开放。
这意味着,Gemini Omni 不只是一个视频生成模型。Google 想把它放进「世界模型」的叙事里:模型不仅生成画面,还要理解画面中的物理关系、运动关系和场景逻辑。
在进入 Gemini App、Google Flow 和 YouTube Shorts 这些应用之后, Omni 也会让 Google 的生成式创作工具从图片编辑扩展到视频编辑。
Gemini 3.5 Flash 上线,AI 写代码进入极速模式
如果 Gemini Omni 对应的是生成和编辑,Gemini 3.5 Flash 对应的就是速度、成本和执行能力。

Google 在发布会上推出 Gemini 3.5 Flash,称它是 Gemini 3.5 系列第一批模型之一,重点面向 agentic coding、长周期任务和真实工作流。
相比 3.1 Pro,3.5 Flash 在几乎所有基准测试中提升明显,尤其是代码能力,以及 GDPVal 这类更接近真实经济任务的评测。
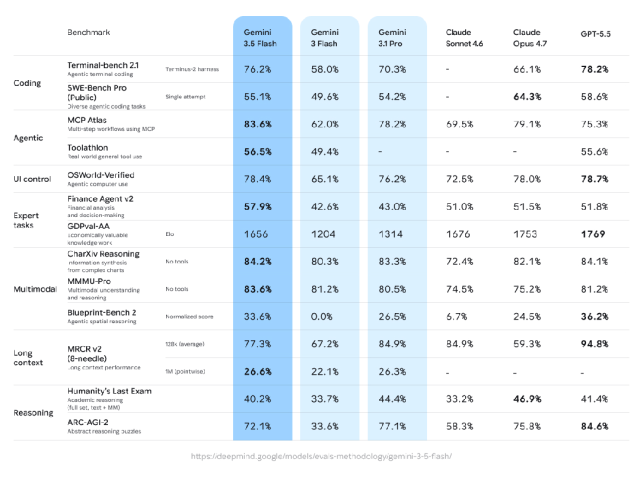
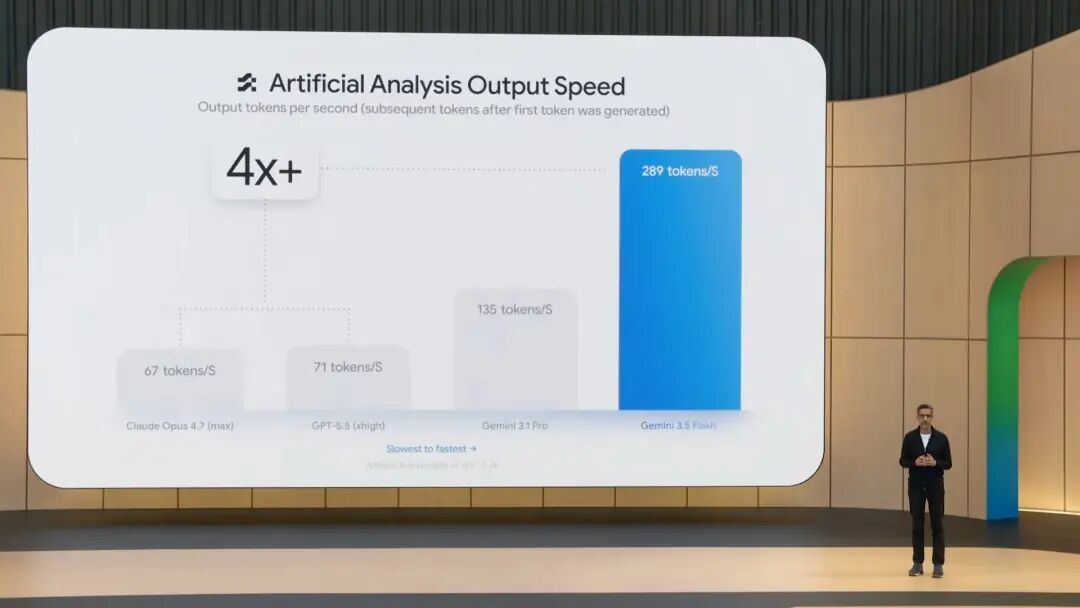
除了基准测试表现不错,3.5 Flash 在输出 tokens 速度上比其他前沿模型快 4 倍,在 Antigravity 中经过专门优化后,速度可达到 12 倍。
值得一提的是,今年 3 月,Google 内部开发相关任务每天处理约 5000 亿 tokens,之后每隔几周翻倍,目前已经超过每天 3 万亿 tokens。Google 把这称为一个反馈循环,用大规模真实使用继续改进 3.5 Flash。
与模型同步推出的是 Antigravity 2.0。
它从原来的 agent powered IDE,升级为一个独立桌面应用,重点转向 agent first。用户不再只是让 AI 在编辑器里辅助写代码,而是通过 Agent 对话、Agent 产物和多 Agent 协同来完成开发任务。
Antigravity 2.0 加入完整 CLI、Antigravity SDK、Gemini 音频模型原生语音支持,并集成 Android、Firebase、Google AI Studio 等服务。Antigravity 2.0 作为独立桌面应用,也已经面向全球用户开放。
Google 在现场用一个高强度演示解释 Antigravity 2.0 的方向:让 Agent 从零构建一个可运行操作系统。这个任务由 93 个子 Agent 并行执行,持续 12 小时,发起超过 1.5 万次模型请求,处理 26 亿 tokens,从空项目生成调度器、内存管理、文件系统等核心模块。
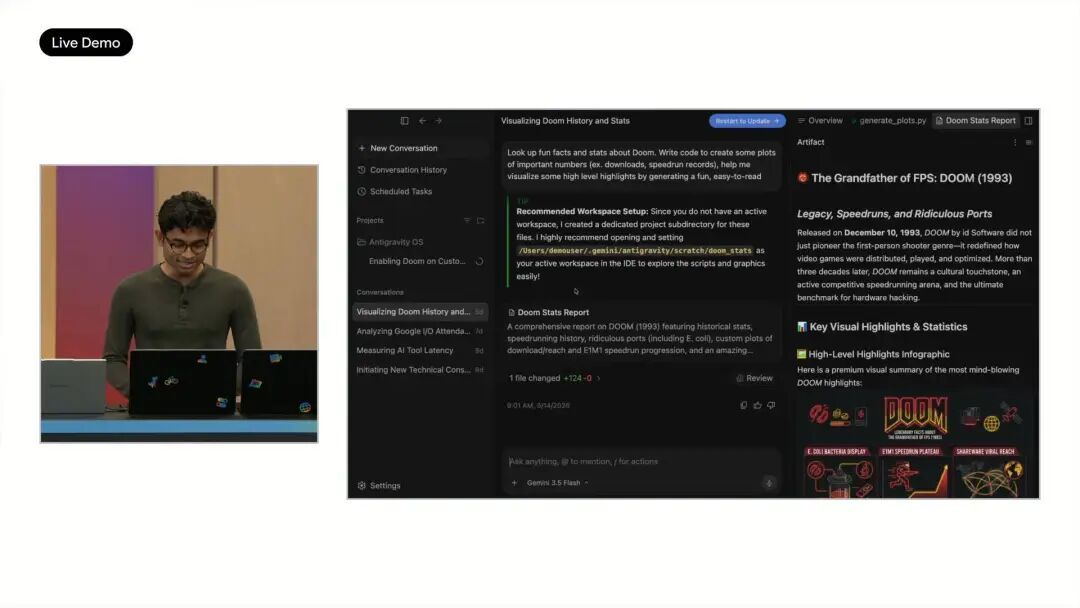
Google 称,这件事在 Gemini 3.1 Pro 上无法完成,而使用 Gemini 3.5 Flash 消耗不到 1000 美元 API credits。
现场还演示了这个系统运行 SL 小火车程序和 Doom。由于系统最初缺少视频和键盘驱动,Antigravity 又继续生成相关代码并修复,让 Doom 能够运行。Google 还称,类似方式已经测试过照片编辑套件、实时消息应用、多用户协作平台等项目,原本需要多天的工程工作被压缩到数小时甚至更短。
Gemini 3.5 Flash 已面向所有用户开放,覆盖 Google 产品和 API。Gemini 3.5 Pro 仍在内部使用和改进中,预计下个月开放。
从搜索框到信息 Agent,Google 重做 AI 搜索
模型和开发工具之后,Google 把重点转向搜索。Google 搜索也就是 AI 搜索。

Google 表示,AI Mode 已经超过 10 亿月活,查询量自推出以来每季度翻倍。
今天起,AI Mode 升级到 Gemini 3.5。新的智能搜索框也从当天开始推送。它支持文本、图片、文件和视频输入,并在用户输入问题时给出 AI 建议。
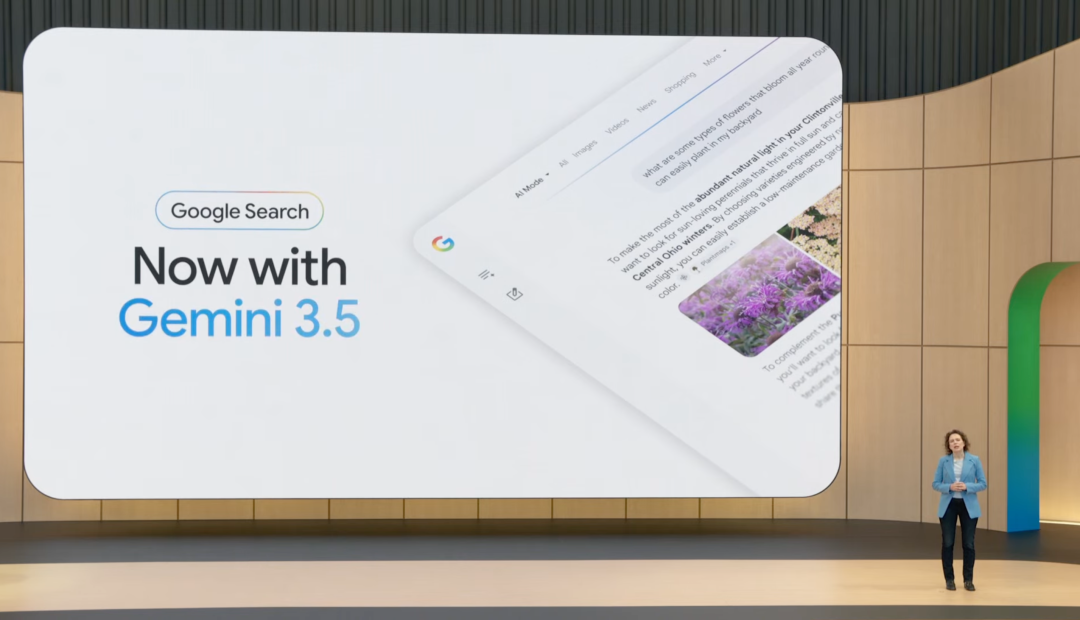
AI Overviews 和 AI Mode 也被合并成更连续的 AI 搜索体验。用户可以先在主搜索结果页看到 AI 回答,再进入 AI Mode 继续追问,上下文会被保留。这个新搜索体验已在发布会当天面向全球桌面端和移动端上线。
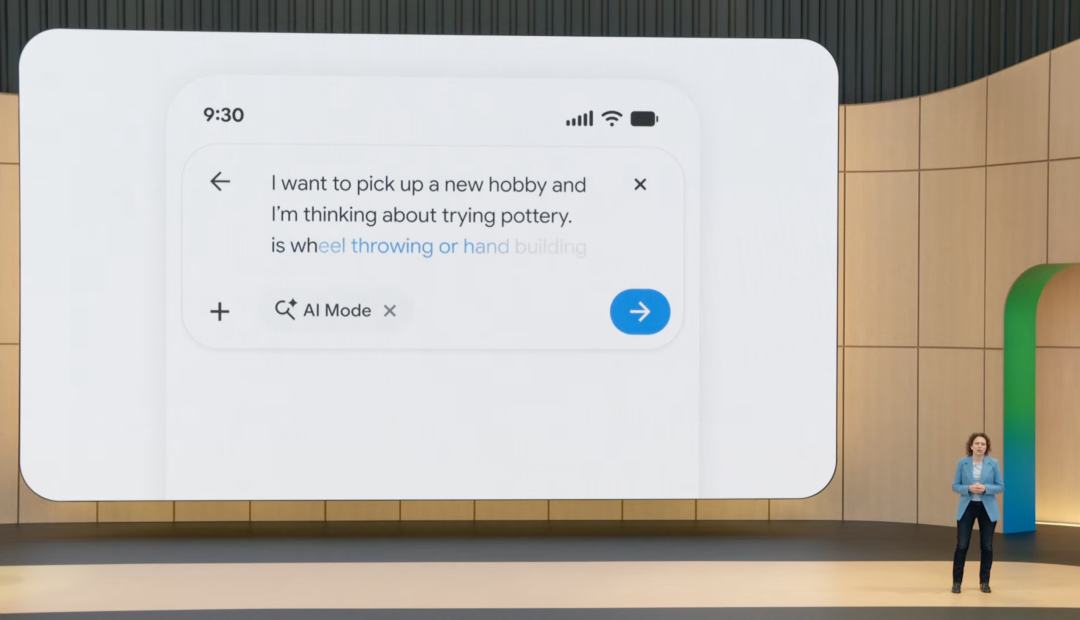
更大的变化是搜索 Agent。用户今年夏天将可以在 Search 中创建信息 Agent,让它持续跟踪某类信息。
例如,用户可以让它监控市盈率低于 15、现金流为正、负债较低的大型生物科技股票;也可以让它长期跟踪租房信息、球鞋联名和商品上新。当条件变化时,Agent 会给用户发送综合更新。

Google 还把 Antigravity 的 agentic coding 能力带入搜索。
之后搜索不只返回网页、摘要或卡片,也能为具体问题生成交互界面。比如用户问「黑洞如何影响时空」,Search 可以生成一个交互式视觉组件;继续追问「双黑洞如何产生引力波」,Search 会重新生成一个可调参数的动态界面。Generative UI with Antigravity 将在今年夏天面向所有用户免费推出。

更复杂的自定义体验也在路上。
Google 现场展示了一个周末计划器,Search 会结合天气、地图、用户偏好、Gmail、Calendar 等信息,生成一个可以继续修改、分享和同步日历的小型工具。这类自定义体验将在未来几个月先面向订阅用户开放。
关机也能跑,Gemini Spark 把 Agent 能力搬进个人生活
消费端最重要的新产品是 Gemini Spark。

Gemini Spark 是一个个人 AI Agent,运行在 Google Cloud 的专用虚拟机上,可以全天候执行任务。它由 Gemini 3.5 和 Antigravity harness 驱动,支持长时间后台任务。
用户关掉电脑后,Spark 仍能继续工作。它先接入 Google 自家工具,未来几周会通过 MCP 接入第三方工具。

发布会展示了 Spark 的几个典型场景。
用户可以让它汇总过去一周 Gemini Live 的发布和进展,从 Docs、Gmail 和聊天记录里提取信息,再用个人写作风格生成团队邮件。
也可以让它管理街区派对,维护 Google Sheets RSVP 表格,跟踪谁带了什么东西,给没报名的邻居生成提醒邮件草稿,并自动生成 Google Slides 宣传页。
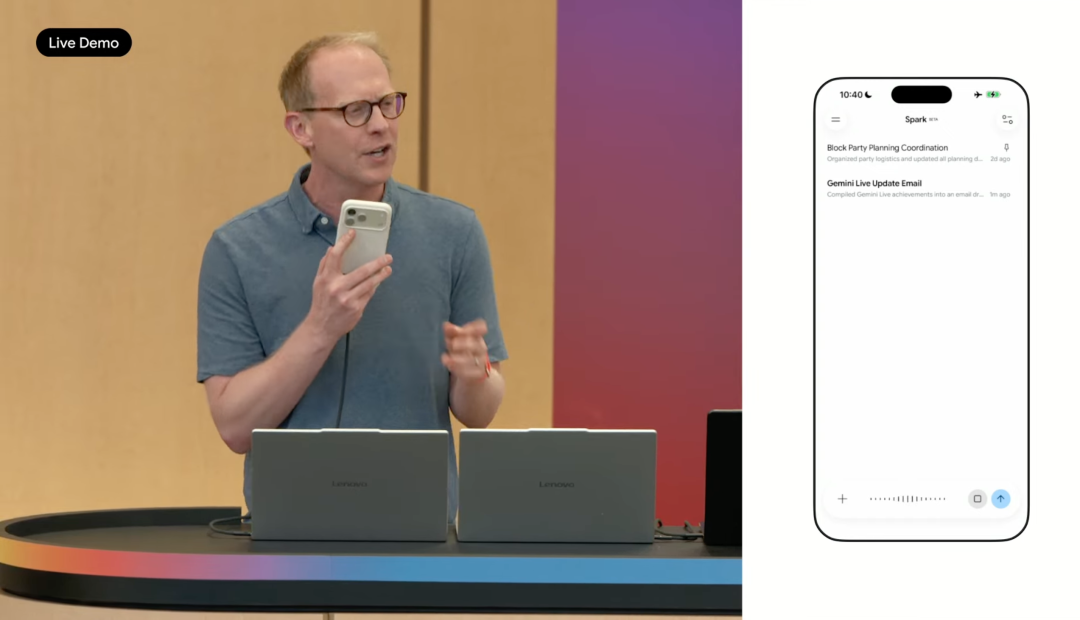
Spark 还支持手机端语音输入。
用户可以一次说出多项任务,比如把所有与 Sundar 的会标成亮粉色,给新邻居写邀请信,创建孩子学年结束前待办文档。Spark 会把这些内容分成多个独立任务,并在后台执行,结果可以在手机和电脑之间同步。
Gemini Spark 本周面向部分测试者开放,下周以 beta 形式面向美国 Google AI Ultra 订阅用户推出。

Google 同时推出每月 100 美元的新 Ultra 计划,并把最高档 Ultra 计划从每月 250 美元降至 200 美元。
今年夏天晚些时候,Spark 将进入 Chrome,成为能在网页中执行任务的智能体浏览器。

Gemini App 大改版,还有 Google 版「AI 晨报」
Gemini App 本身也迎来了一次脱胎换骨的大改版。
Google 引入了全新的设计语言 Neural Expressive,加入流体动画、鲜艳色彩、新字体和触觉反馈。
新版 Gemini App 不再把回答呈现为大段文字,而是会根据内容实时生成更适合阅读和操作的布局,包括交互图片、时间线、嵌入式视频等。Neural Expressive 现在已经在 Android、iOS 和网页端全球推送。
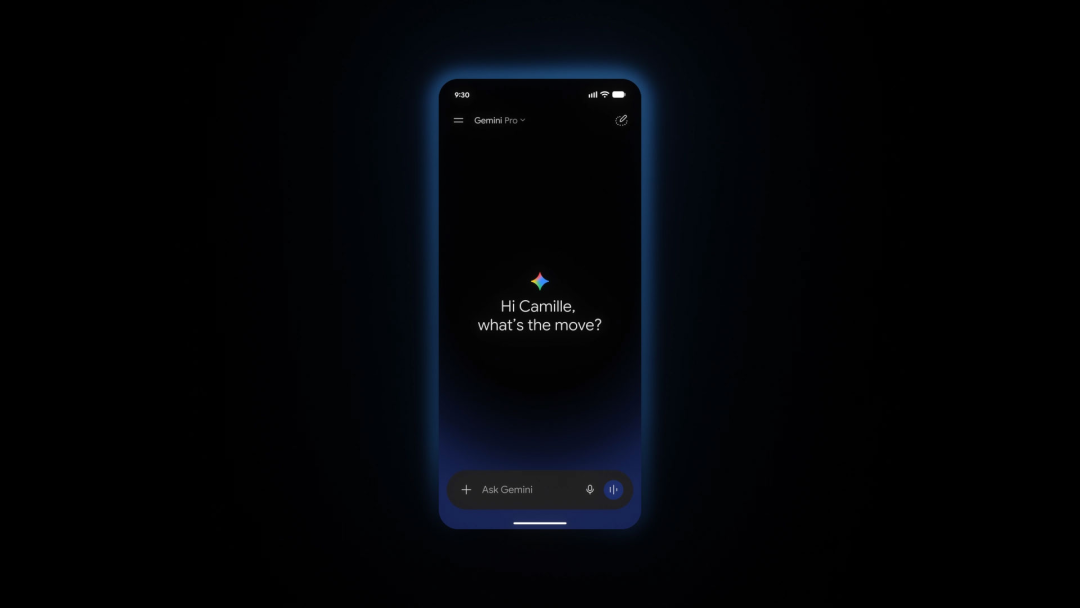
Gemini Live 也被重做,打开后可以直接进入实时对话。区域口音选择将在未来几周推出。
Gemini App 还加入 Daily Brief。这是一个面向早晨使用的个性化摘要 Agent,会综合 Gmail、Calendar、Tasks 等信息,整理用户当天需要关注的事项,并给出下一步行动入口。
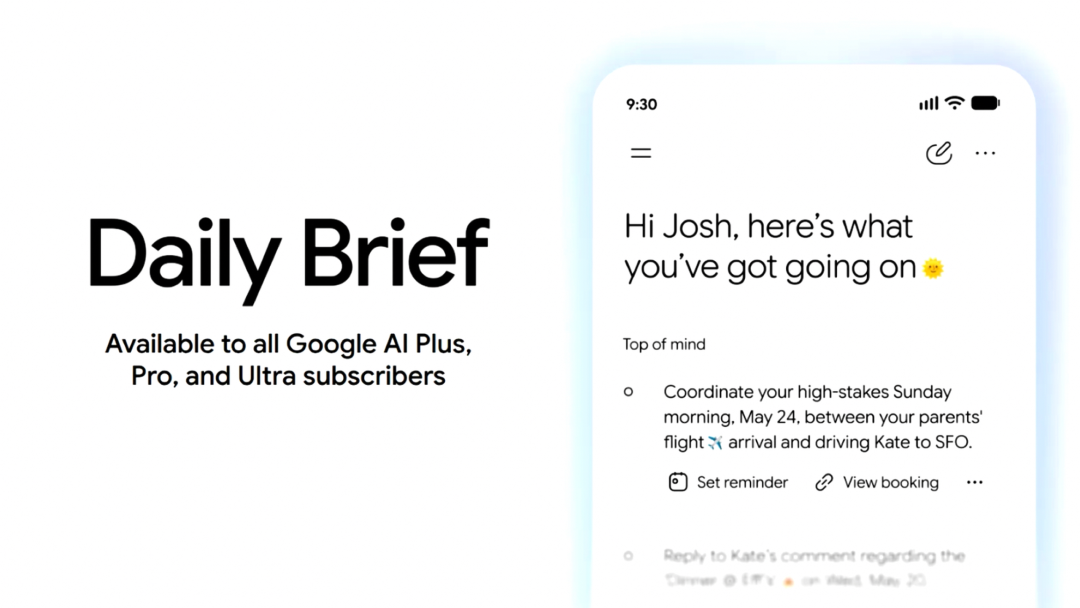
Daily Brief 今天起面向美国 Google AI Plus、Pro 和 Ultra 订阅用户推出。
在更大的 Gemini 叙事之外,Google 也更新了几个日常产品。
Google Maps 最近完成十年来最大升级,并加入 Ask Maps。它允许用户提出更长、更复杂的问题。例如,发布会举了一个场景:孩子掉进鸭塘,婚礼 30 分钟后开始,用户想知道哪里可以步行买到新裙子。

Docs 也获得新的语音创建能力。用户不需要输入精确提示词,可以直接用语音把想法说出来,让 Gemini 从 Drive 调取简历,从 Gmail 找到活动信息,再生成 Google Docs 草稿。这个能力将在今年夏天面向 Pro 和 Ultra 订阅用户推出,同类语音能力也会进入 Gmail。
生成能力升级后,内容来源识别也变得愈发重要。
Google 称,SynthID 推出三年来,已为超过 1000 亿张图片和视频,以及相当于 6 万年时长的音频加上不可见水印。接下来,SynthID 和内容凭证验证会扩展到 Search 和 Chrome。

用户可以通过圈选搜索,或者在 Chrome 中右键询问内容是否由 AI 生成,系统会显示内容来自 AI、相机,还是曾被生成式 AI 工具编辑。
Google 还宣布,OpenAI、Kakao 和 ElevenLabs 将采用 SynthID 2。此前英伟达已经加入 SynthID 体系。对 Google 来说,SynthID 不只是安全功能,也是争取 AI 内容透明标准的一部分。

Google 创作全家桶,开始围攻图片、设计和视频
在创意工具领域,Google 密集发布了多款重磅产品。
Google Pics 是 Google Workspace 中的新图片创建和编辑产品,面向派对海报、信息图、宣传图等场景。用户可以从一张基础图开始,删除元素、调整对象大小、编辑文字和翻译文字。Pics 生成内容会带有 SynthID 水印。Google Pics 将在今年夏天推出。

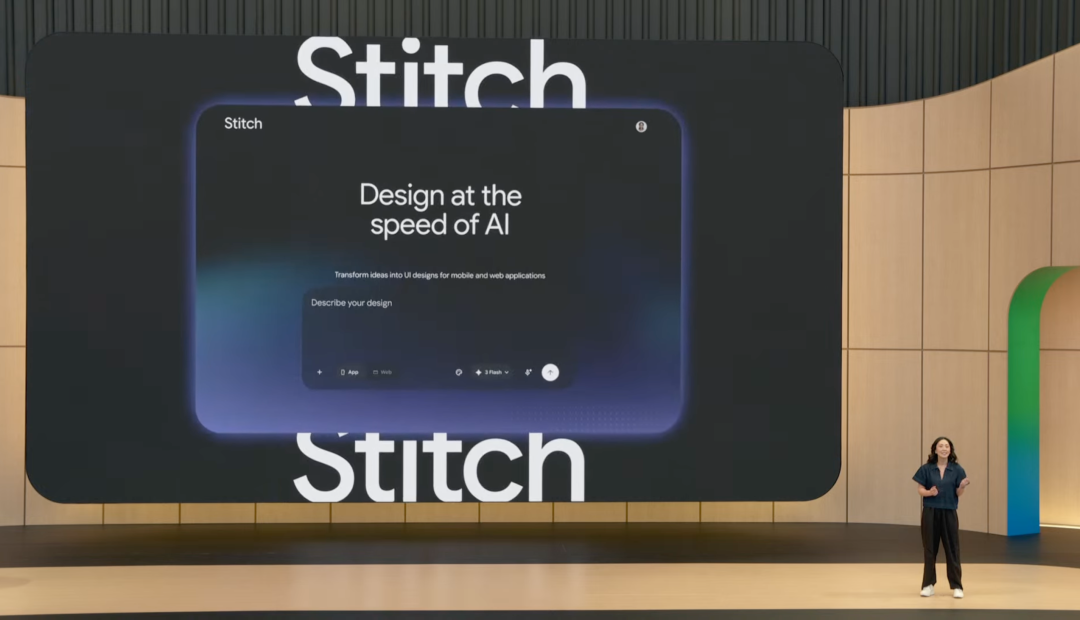
设计产品 Stitch 也迎来更新。用户可以通过一句 prompt 生成网站或应用界面,再通过文字或语音继续修改,比如放大标题、调整菜单、突出更多披萨选项。Stitch 支持把设计导出为代码,或直接发布网站,相关更新现已发布。
Google Flow 的更新尤为关注。Gemini Omni 进入 Flow 后,用户可以基于原始视频改变环境、添加视觉效果、加入新角色,同时尽量保留原有表演。
Flow 还加入新 Agent,支持一次执行多个动作。比如从单张图片生成 16 个不同机位的视频,或把一组清晨场景批量改成深夜场景。

Flow Tools 则允许用户在 Flow 中创建自己的创意工具,比如视频特效、手绘动画和文字分层工具,并支持分享和 remix。
Google Flow Music 可以把一段钢琴 riff 扩展成带风格方向的音乐 demo。Google Flow 和 Google Flow Music 的这些新功能已上线。
押注智能眼镜,Google 再闯下一代入口
硬件部分,Google 也把 Android XR 这个操作系统级平台,从头显、XR 设备,进一步扩展到智能眼镜形态。
Android XR 是 Google 与三星合作,并针对 Qualcomm Snapdragon 优化的平台。

Google 表示,AI 眼镜会分成两类:一类是带小型镜片的显示眼镜,另一类是音频眼镜。显示眼镜去年已在 I/O 展示,今年首批开发者已经开始创建显示体验,可信测试者计划将在今年晚些时候扩大。
更早上市的是音频眼镜。
首批音频眼镜将在今年秋季推出,由三星参与硬件和体验构建,Warby Parker 与 Gentle Monster 负责眼镜设计。这些眼镜连接手机,支持 Android 和 iOS。Gemini 的回答通过耳机私密播放,而不是显示在镜片上。

发布会上,演示者可以通过眼镜让 Gemini 导航到上周和朋友见面的地方,中途加入咖啡店;也可以让 Gemini 打开 DoorDash 自动下单咖啡,等待用户确认;
还可以让它总结静音消息,并把家庭晚餐写入日历。眼镜还可以与手表配合,让用户拍摄现场照片,并用 Nano Banana 生成卡通图像,再在手表上预览。
发布会最后,Gemini 的使用场景也延伸到了网络安全场景。
Google 介绍了 CodeMender。它是一个代码安全 Agent,能够自动寻找和修复关键软件漏洞。Google 将邀请一批专家测试 CodeMender API,之后会更广泛推出。

整场发布会看下来,信息量大到让人有些缺氧。只是当这些 AI 功能真正开放给几千万、几亿人使用时,一个最现实的算账问题就直接摆在了面前:这笔庞大的算力开销,Google 要怎么挣回来?
过去二十多年,Google 代表的是一种典型的免费互联网模式。用户用注意力和数据换服务,Google 用广告和分发赚钱。这套模式让 Google 成为互联网时代最强的基础设施公司。
但大模型推理的成本,和查询一次搜索结果完全不在一个量级。
长上下文记忆、多模态生成、跨应用 Agent、企业级自动化,这些能力背后都是持续运行的算力消耗。AI 越深入,Google 越难继续用「免费功能升级」的方式来消化成本。
这就是为什么整场发布会下来, Google I/O 看似讲的是体验升级,背后指向的却是订阅、企业合同、算力账单和长期服务费。
免费入口当然不会消失,因为那仍然是 Google 获取用户、数据和生态位置的基础。但在这些入口之上,Google 正在叠加一个新的智能服务层:更强的模型、更长的记忆、更深的系统权限、更复杂的任务执行,以及更稳定的企业级服务。
换言之,Google 正在从免费互联网服务公司,进一步变成 AI 订阅基础设施公司。
只是,问题也随之而来,用户愿意为搜索付费吗?通常情况下,不会。
可是,如果这是一个能替你全天候处理邮件、统筹任务、分析报表、接管智能家居,甚至还能帮你写代码开发 App 的「超级全能助理」呢?你愿意为它每月掏出几十上百美元吗?
这,正是今年 Google I/O 迫切想要验证的核心商业命题。而环顾如今狂热的市场,答案似乎早已不言而喻。
(来源:新浪科技)
关联资讯:
谷歌 Gemini Spark 个人智能体发布:一句话让 AI 干几份活


