Gemini 3.0发布:从“工具辅助”到“主动代理”,谷歌做了这几点
当地时间周二,Alphabet旗下的谷歌宣布发布其最新的人工智能(AI)模型Gemini 3。这款被业内称为 “全能型选手” 的模型,以百万级上下文窗口、断层领先的多模态理解、颠覆式的 Agent 开发平台和全栈技术生态支撑,不仅实现了对前代产品的代际级超越,更在多个核心基准测试中对标甚至超越GPT-5.1、Claude 4.5等竞品,标志着AI从“工具辅助”向“主动代理”的跨越式演进。
据悉,Gemini 3将被整合进Gemini应用、谷歌的AI搜索产品AI Mode和AI Overviews,以及其企业级产品。该模型将自周二起向部分订阅用户开放,并将在未来几周更大范围上线。
在2025年11月的财报电话会议上,谷歌CEO桑达尔・皮查伊就已确认Gemini 3的发布计划,他当时强调:“前沿模型的进一步发展需要更多时间,我们既要追求迭代速度,更要确保显著的能力突破”。这种“慢工出细活”的策略,在Gemini 3的产品形态中得到充分体现——它不是对2.5 Pro的简单微调,而是从架构、能力到生态的全面重构。
推理是AI解决复杂问题的核心,Gemini 3在这一领域实现了双重突破:基础性能的全面提升与推理模式的产品化创新。在基础推理能力上,Gemini 3 Pro在多个权威基准测试中创下新高:GPQA Diamond(研究生级推理)测试准确率达91.9%,Humanity’s Last Exam(多步逻辑推理)无工具状态下得分37.5%,SimpleQA Verified(事实准确性)以72.1%的分数领跑业界。
这些数据意味着模型在科学研究、专业咨询等需要深度思考的场景中,可靠性达到了新高度。例如它能独立完成托卡马克装置等离子体流动的可视化代码编写,并同步创作诠释聚变物理学精髓的诗歌,实现理性与感性的结合。
在多模态推理方面,Gemini 3同样表现出色,在MMMU-Pro测试中获得81%的分数,在Video-MMMU测试中达到87.6%。这意味着该模型能够高度可靠地处理科学和数学等广泛领域的复杂问题。
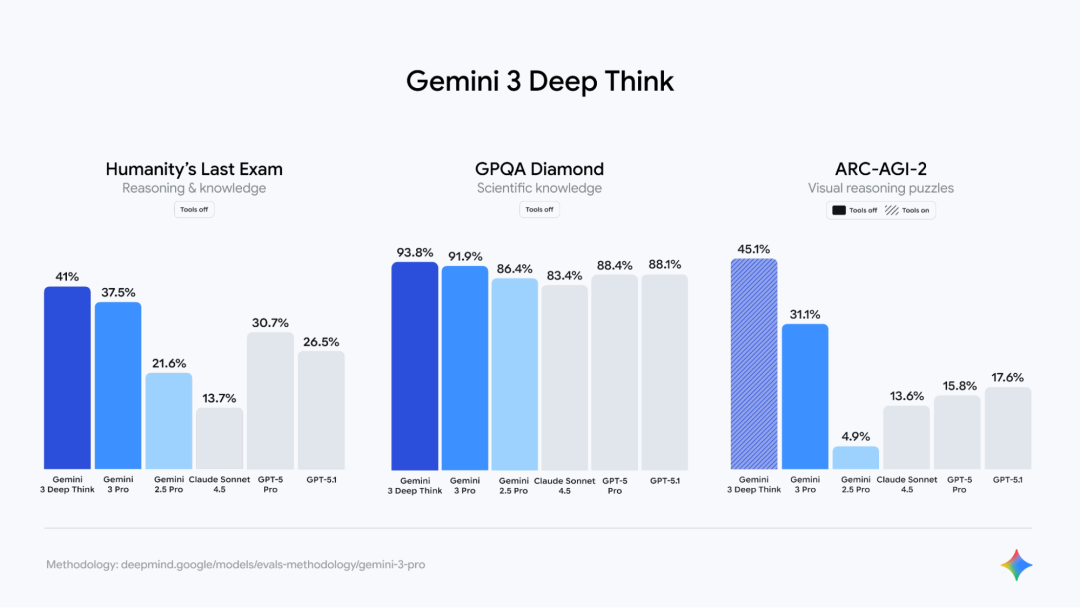
除标准版本外,谷歌还推出了Gemini 3 Deep Think增强推理模式,通过“思维签名”和“思考等级”两大创新,将思维链(Chain of Thought)技术产品化:思维签名会在API返回中包含加密的推理过程,确保长链路任务中逻辑不跑偏;思考等级则允许开发者根据任务复杂度配置模型“思考时间”,实现速度与精度的平衡。
数据显示,增强推理模式在Humanity's Last Exam测试中达到41.0%的成绩,在GPQA Diamond测试中获得93.8%的分数。在ARC-AGI-2测试中,Deep Think模式创下了45.1%的前所未有成绩,展示了其解决新颖挑战的能力。谷歌表示,该模式正在接受额外的安全评估,将在未来几周内向Google AI Ultra订阅用户开放。
长上下文处理是AI从“短对话”迈向“复杂任务”的关键。Gemini 3.0 Pro最令人震撼的特性,莫过于其支持高达100万tokens的超长上下文长度(约相当于700页英文书籍或2小时的4K视频),这一数字远远超过当前主流模型——GPT-4 Turbo的128K tokens和Claude 3.5的200K tokens,较谷歌自身的Gemini 2(12.8万token)提升7倍,且保持90%以上的信息保留率。
而在多模态方面,Gemini 系列从诞生之初就以“原生多模态”为核心优势,Gemini 3则将这一优势推向新高度,实现了从“处理多模态” 到 “理解多模态关联”的跨越。在权威基准测试中,Gemini 3 Pro 的多模态能力全面领跑:MMMU-Pro(多模态综合推理)得分81%,Video-MMMU(视频理解)以87.6%的成绩重新定义行业标准,成为 “世界上最先进的多模态理解模型”。
如果说推理和多模态是Gemini 3的“大脑”,那么编码与Agent能力就是它的“双手”。谷歌通过 “代理式编码(Agentic Coding)”和“可视化编码(Vibe Coding)”两大创新,彻底重塑了开发者与AI的协作模式。
在代码生成领域,Gemini 3被谷歌称为"迄今构建的最佳vibe coding和智能体编码模型"。该模型在LiveCodeBench Pro(接近 ICPC/Codeforces 难度的竞技编程测试)中,模型以2439的Elo得分远超GPT-5.1的2243和Claude 4.5的1418,逼近专业程序员水平。
Agent能力的跃升是Gemini 3最具颠覆性的更新。模型不再是被动响应指令的工具,而是能自主规划、拆解任务、调用工具的 “数字代理”。在Terminal-Bench 2.0测试(终端操作能力)中,它以54.2% 的得分展现出强大的工具使用能力;而在Vending-Bench 2测试(长程规划能力)中,Gemini 3 Pro在模拟运营自动售货机业务的年度周期中,通过一致的决策和工具使用实现了更高回报,位居测试榜首。这种长程规划能力让AI能独立完成复杂工作流,例如自动爬取数据、分析趋势、生成报告并部署可视化界面,全程无需人工干预。
为了让 Agent 能力落地,谷歌同步推出了全新的开发平台 Google Antigravity,让开发者得以在更高抽象层级上进行任务导向型编程。谷歌实验室与Gemini副总裁Josh Woodward表示,Gemini 3是谷歌有史以来最契合“氛围编程”的模型。氛围编程指一个快速兴起的AI工具市场,允许软件开发者通过提示词即可生成代码。
谷歌称,新模型将支持“生成式界面”,以类似数字杂志的方式呈现某些答案。例如,新模型被要求结合梵高生平背景解读其作品,系统为每幅画作生成了图文并茂、色彩丰富的阐释。
在Gemini 3.0模型发布之前,网上就已有不少针对该模型的测试。测试结果显示,该模型在专业领域的测试结果显示出突破性进展。加拿大劳瑞尔大学历史学教授Mark Humphries通过Google AI Studio测试了疑似Gemini 3.0的未发布模型,发现其在识别18世纪手写文稿方面接近完美,字符错误率仅为0.56%,词错误率为1.22%,相比前代Gemini 2.5 Pro提升50%-70%,达到专家级人类水平。
测试结果显示,前代Gemini 2.5 Pro在这些复杂文档上的字符错误率约为4%,大致相当于专业人类转录员的水平。新模型将字符错误率降至0.56%,词错误率降至1.22%,达到专家级人类表现标准。
更值得注意的是模型展现出的推理能力。Humphries发现模型能够自发进行逐步符号推理,例如在18世纪商人账本中将"145"推断为"14磅5盎司",这不仅是文本识别,而是对生成这些记录的经济和文化系统的理解。
对于谷歌而言,Gemini 3.0的发布具有战略意义。自2022年底ChatGPT发布以来,谷歌一度被认为在AI竞赛中处于追赶状态,甚至内部发布了"红色警报"。Business Insider援引内部人士称,新模型可能让谷歌有机会夺得领先地位,特别是在OpenAI的ChatGPT-5未能立即产生重大影响之后。
尽管谷歌在AI竞赛中起步较慢,但其仍拥有OpenAI等初创公司所没有的众多优势:自研专用芯片;在在线搜索中拥有约90%的市场份额;以及数以百万计的Gmail、Google Docs等用户,如今这些产品正逐步被注入AI功能。谷歌上月还公布了创纪录的收入,并计划在AI建设上投入数十亿美元。
对于企业和开发者而言,Gemini 3的价值不仅在于其强大的能力,更在于它提供了一个“可扩展、可定制、可落地”的智能基座。随着生态的完善,我们有理由相信,Gemini 3将加速AI从“实验室”走向“生产线”,最终渗透到每个人的生活与工作中。
对于行业而言,Gemini 3的发布不是竞争的终点,而是新的起点。它将倒逼竞争对手加速技术创新,推动AI行业在推理能力、多模态融合、Agent开发等领域的全面进步;对于用户和开发者而言,Gemini 3带来的不仅是更强大的工具,更是全新的工作和交互方式。
(文|Leo张ToB杂谈,作者|张申宇,编辑丨盖虹达)
(来源:钛媒体)
关联资讯:
一文详解|Gemini-3,及配套的Antigravity、Gemini CLI、生成式 UI、Otter、Firebase..
Gemini 3全面断崖式领先,单个模型横扫多模态、推理、Agent三大战场,Google王者归来
谷歌Gemini 3深夜掀翻牌桌:数理满分、视力碾压 GPT-5,程序员的“自动驾驶”时代真的来了

