狂揽7.1k Stars!武装你的龙虾和“爱马仕”,YC总裁开源AI记忆外挂

智东西
作者|江宇
编辑|漠影
智东西4月13日报道,昨日,YC总裁Garry Tan开源的“AI记忆外挂”——GBrain,迎来新一轮更新,版本迭代至0.9.0。自4月10日发布后短短数天,该项目已在GitHub狂揽约7.1k星。
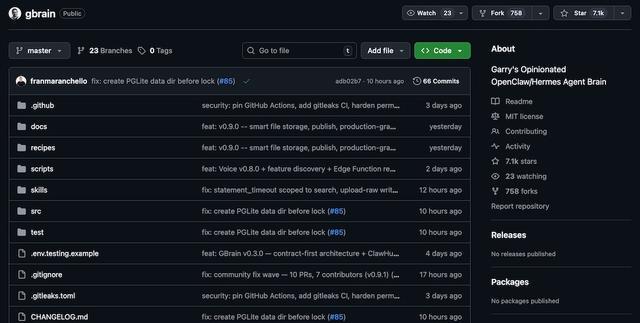
借助这套系统,用户的笔记、开过的会议、收发的邮件、刷过的社交平台记录,乃至通话记录,都可以被持续写入同一套系统,并完成结构化整理与索引。
当这些信息积累到一定规模后,再次提问时,AI可以直接调取过往记录参与判断。常见用法包括回溯某个人的历史往来、梳理一段持续演进的思考脉络,或在会议前自动聚合相关背景信息。
这正好踩在当前AI的一个共识问题上:容易“失忆”。Agent侧的memory主要记录偏好和配置,大模型的上下文又有长度边界,一旦跨任务、跨时间,信息往往难以延续。GBrain补充上的,正是这一层长期、可累积的数据能力,尤其适合已经在使用OpenClaw、Hermes这类持续运行Agent的用户。
它将原本分散在各处的数据,整理为一套可以被读取、写入并持续更新的“长期记忆层”。Garry Tan也直言,这套系统的目标,是让Agent具备“对上万份文档的完整记忆能力”。
他在分享这一项目时提到:“如果你希望你的Agent能够完整记住上万份文档,GBrain就是为此准备的”,并补充称,“希望它能帮你搭建属于自己的mini AGI”。
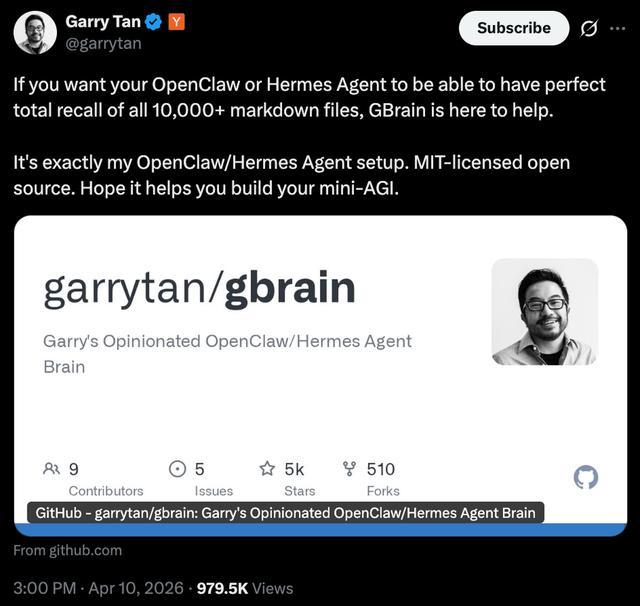
在最新版本中,GBrain新增多项确定性命令与生产级技能,包括知识反向链接检查、自动修复LLM生成错误、结构化报告生成以及大文件分层上传等能力,同时进一步强化知识图谱构建与长期维护机制。
如果已经部署了OpenClaw、Hermes Agent等持续运行的Agent,用户只需将指令交给Agent执行,安装、配置与数据导入等流程即可自动完成。一个基础版本的“脑库”(即围绕用户自身信息建立起来的长期记忆库),通常在30分钟左右可以跑通,本地数据库也可以在几秒内初始化完成。
开源地址:github.com/garrytan/gbrain
一、脱胎于卡帕西的“大模型维基百科”,进化出“自进化的知识库”
GBrain并不是一个刚刚冒出来的新项目。早在4月10日,Garry Tan就已在X上密集披露这一项目,并正式对外开源。他将其定义为一套“可被Agent直接读写的长期记忆系统”,核心目标是解决AI在个人数据层面的“失忆问题”。
按照Garry Tan的说法,这套方案提供了一种“the easiest, best, guided way(最简单、最好且带引导的方式)”来复现个人AI系统。
这套系统已在Garry Tan的个人环境中长期运行,管理过超10000份Markdown文件、3000+人物档案、13年日历数据以及5800条Apple Notes记录,并持续接入会议、邮件、社交信息与原始想法等多类数据,形成一个可被Agent持续调用与更新的个人知识“脑库”。
4月12日,Garry Tan还进一步放出Skillpack配方、语音接入方案以及完整部署路径。此版本能在15分钟以内,完成基础搭建,并以更接近“Personal AI software(个人AI软件)”的形态产出——由Agent根据个人数据与需求动态生成与演化,而非一款固定功能的工具。
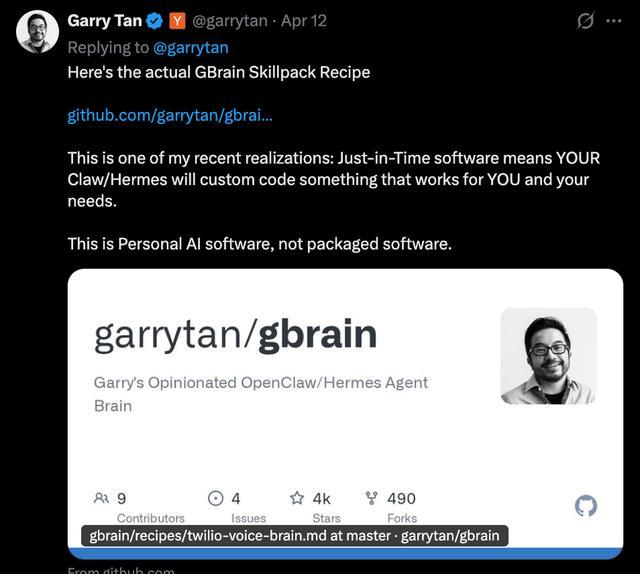
同时,他也公开展示了GBrain在语音交互、数据接入与知识沉淀等场景中的实际运行方式。
而这一项目的思路,也与AI大神卡帕西(ndrej Karpathy)提出的LLM Wiki一脉相承,可看作“大模型维基百科”的一次延展。
在4月5日,这一项目的雏形首次被提及。Garry Tan当时提到,他此前基于Karpathy提出的LLM Wiki范式,构建了一套以Markdown为核心的个人知识系统。但随着数据规模快速增长,这一体系很快触及瓶颈——其知识库已膨胀至约2.3GB,Git管理方式开始变得低效甚至“吃不消”。
在这一背景下,他开始引入数据库与向量检索能力,对原有结构进行重构,逐步演化出GBrain这一方案。GBrain在底层加入了Postgres与pgvector等组件,使其能够支撑更大规模的数据检索与结构化查询。
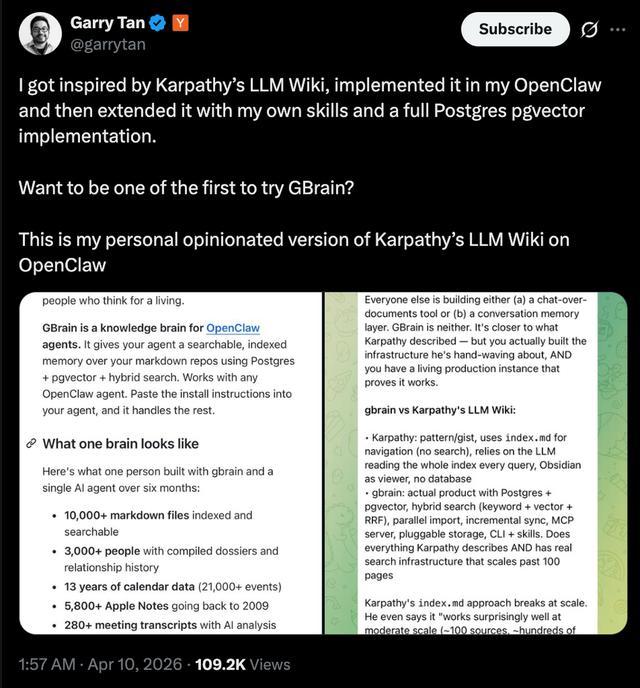
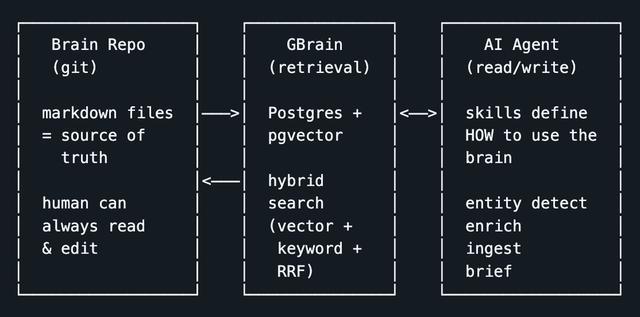
整体来看,GBrain是一套围绕“个人长期记忆”的完整Agent架构。从个人笔记、日程、社交关系到会议与原始想法,所有数据被持续写入、索引与回读,形成一个可被Agent调用的知识系统。
二、先别急着谈“记忆”,GBrain先把一套“脑子”搭出来
AI Agent也许已经很聪明,但它并不了解你的生活。会议、邮件、推文、日历事件、语音通话、原始想法,这些真正构成个人上下文的信息,过去大多散落在不同工具和不同账号里,模型每次对话都只能“临场发挥”,很难持续积累。
GBrain要做的,就是把这些数据统一流入一个可搜索的知识库,让Agent在每次回应前先读,在每次对话后再写,久而久之,这个系统逐渐形成对你个人世界的长期理解。
这一点也是GBrain的核心价值所在——长期记忆,其管理的是“world knowledge”,也就是人物、公司、会议、概念、交易和用户自己的想法。
Agent自身的memory_search更偏向操作状态,比如偏好、决策和配置;当前会话则负责处理即时上下文。以上两层分工之后,再由GBrain来承担“长期记忆”这一层。
三、30分钟上“脑”,部署、扩展和迁移一条路打通
如果用户已经有OpenClaw、Hermes Agent或其他持续运行的Agent,只需要把指令块丢进去,剩下的流程由Agent自己读文档、执行安装、询问API key并完成配置。
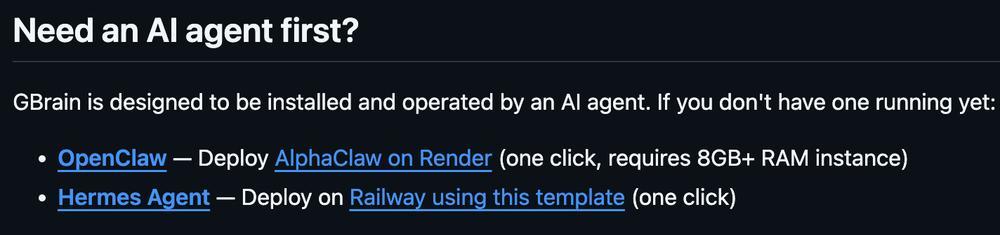
一套基础版“脑库”大约30分钟可以跑通,其中本地数据库PGLite在2秒内就能初始化,后续的schema建立、文档导入、embeddings生成和各类集成配置,则根据“脑库”大小不同,大约需要15到30分钟。
GBrain默认使用PGLite作为本地数据库方案。用户执行gbrain init之后,就能得到一个嵌入式的Postgres“脑库”,不需要单独购买服务器,也不要求先准备外部数据库,属于“零配置启动”。
如果后续“脑库”继续增长,比如超过1000份文件、需要多设备访问,或者要通过远程MCP给别的AI客户端调用,再用gbrain migrate –to supabase迁移到托管版Postgres。
这套方案既保留了本地部署的低门槛,也给大规模使用留出了升级空间。
此外,其搜索能力在不接OpenAI和Anthropic API key的情况下也能运行,但只能做关键词检索;接入OpenAI之后,才能启用向量搜索;补齐Anthropic之后,则可以进一步获得多查询扩展和更好的搜索质量。
目前,GBrain主要针对Claude Opus 4.6和GPT-5.4 Thinking这类frontier model测试,小模型大概率撑不起整套方案。
四、邮件、日历、电话都能往里灌,化身“个人脑库”
如果说本地Markdown和数据库是GBrain的底座,让这套系统真正活起来的,是GBrain持续“进数据”的配方体系——“Getting Data In”。
GBrain提供了一组recipes,让Agent自己读取安装说明、向用户索要凭据、校验授权并完成接入。从目前提供的方案看,GBrain已经覆盖了几个最核心的数据入口。
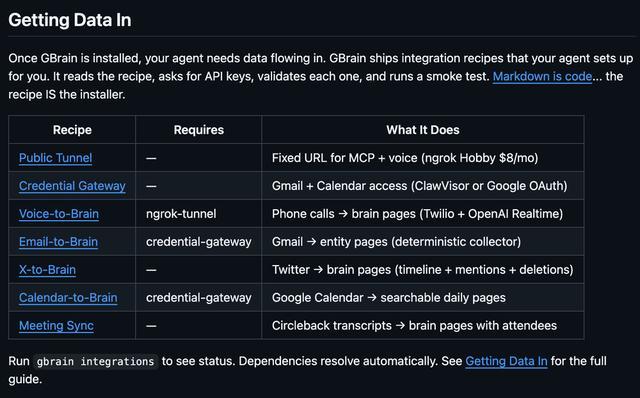
1、通过Credential Gateway可以接入Gmail和Google Calendar,把邮件和日历流入“脑库”;
2、通过X-to-Brain可以持续同步X上的timeline、提及和删除记录;
3、通过Meeting Sync可以将Circleback生成的会议转录写入人物和会议页面;
4、Voice-to-Brain则更进一步,允许用户通过Twilio和OpenAI Realtime搭一个真正能接电话的AI号码。电话打进来之后,Agent先读取来电者相关背景,再在通话结束后自动生成包含转录、实体识别和交叉引用的新页面。这套语音能力已经能在真实号码上运行,未知来电也可以被筛选。
这套接入机制最关键的地方,是它让记忆系统不再停留在一批静态文本上。邮件、会议、社交记录和电话,Agent每处理一次互动,就会把相关信息重新写回“脑库”。对用户来说,这种体验和传统知识管理软件或许已经不太一样了。
五、记忆开始“滚雪球”,Agent用得越久信息越完整
在项目中,Garry Tan将一道机制称为“The Compounding Thesis(复利式记忆机制)”。
当新的信息进入系统后,Agent会先识别其中涉及的人物、公司和概念,再优先到“脑库”中检索相关内容,结合已有上下文完成回应,随后把这次新增的信息写回脑库,并同步更新索引。
这个“读取—写入—更新”的循环不断重复之后,系统逐渐形成连续的上下文积累,Agent也不再依赖单次对话的信息,而是可以调动历史数据完成判断。
Garry Tan也给出了一些典型使用场景。比如,“我该邀请谁来吃饭,同时认识Pedro和Diana?”,背后依赖的是数千个人物页面及其关系网络的交叉调用。
再比如,“我过去是怎么谈‘羞耻感与创始人表现之间关系’的?”,检索范围来自用户自身过往的记录和思考。
在更贴近日常使用的场景中,如果30分钟后要与Jordan见面,系统可以提前整理该人物的资料、过往互动记录、近期动态以及未完成事项,生成一份会前brief。此类能力依赖的是前期持续沉淀的数据,在需要时被重新调取和组合。
为了让这套机制能够稳定运行,GBrain在知识组织结构上也做了相应设计。每个页面被划分为“compiled truth”和“timeline”两部分。前者记录当前阶段对某个人、公司或概念的综合理解,后者按时间顺序追加事件、来源与变化轨迹。
Garry Tan对此称:“综合结论是答案,时间线是证据”。这一设计让系统在不断更新认知的同时,也保留了信息来源和演变路径。对于长期记忆系统来说,这种结构更有利于持续修正与复盘,而不是简单叠加记录。
六、30个工具之外,“怎么用”尤为重要
GBrain是一个开源仓库,包含CLI、MCP server、TypeScript库,以及一整套命令与接口。但进一步展开可以发现,这个项目的重点并不只在工具本身,还包括一整套明确的使用方式。
其中,GBRAIN_SKILLPACK.md被放在核心位置。相比列出有哪些能力,这份文档更多在规定Agent的行为方式,包括什么时候读取“脑库”、什么时候写入信息、如何做数据富化,以及如何维护整个系统的状态。
这一设计让GBrain和常见的功能型项目有所区分。项目中不仅提供了30多个MCP工具,还将brain-agent loop、实体检测、会议写入、来源追踪、定时巡检以及夜间“dream cycle”等运行逻辑一并写入Skillpack中。
具体来看,系统要求Agent在每次消息到来时优先进行brain-first lookup,对新出现的人物、公司和概念进行实体捕捉,并以固定周期执行数据同步与embedding更新。同时,还设定了每日更新检查与夜间批处理流程,用于补全实体、修复引用并整理已有记忆。
在这一套机制下,GBrain将一整套长期运行的流程固化下来,让Agent在使用过程中持续积累、整理并更新信息。
也正因为如此,GBrain更接近一套Agent基础设施。它既可以独立作为CLI工具使用,也支持通过MCP接入Claude Code、Cursor、Windsurf等客户端,并可通过远程MCP服务实现跨设备访问。
对于OpenClaw或Hermes这类持续运行的Agent,它承担的是长期知识层的角色;对于其他MCP客户端,则提供一个可查询、可修改、可扩展的个人知识库。
从整体结构来看,Garry Tan此次开源的GBrain是一套围绕“个人长期记忆”构建的完整实现框架。
结语:长期记忆有了新方案,但门槛还在
在现有体系中,大模型负责生成,Agent负责执行,但跨任务、跨时间的信息积累,一直缺乏稳定方案。上下文会被截断,memory更多停留在偏好与配置层,很多信息难以自然延续。
GBrain提供了一种相对完整的方法:把分散数据持续写入、结构化整理,并在后续反复调用。这套机制本身并不“轻量”,对模型能力、数据规模和系统运行都有一定要求。
从这个角度看,长期记忆这件事已经有了可以运行的版本,但距离“随手可用”的形态,还有一段距离。对更广泛的用户来说,一个更轻量、更易部署的方案,可能仍然是接下来需要被解决的问题。
(来源:新浪科技)
