云知声Unisound U1-OCR大模型发布,开启OCR 3.0时代
DoNews2月26日消息,就在刚刚,云知声正式推出 Unisound U1-OCR 文档智能基础大模型。作为首个工业级文档智能基座,该模型凭借 “性能 SOTA、可信可验、开箱即用、高效部署、强适配” 五大核心优势,打破传统文档处理边界,树立起行业新标杆。
技术跨越:从 OCR 2.0 迈向 3.0
文档智能(Document Intelligence)是指利用人工智能技术自动阅读和理解文档影像,并进行内容的读取、理解、分类及关键信息提取。
传统视觉方案(OCR 1.0,以CRNN 为代表)仅能识别文字,新一代多模态方案(OCR 2.0,以VLM为代表 )具备端到端版面理解能力和文字识别能力。
而 Unisound U1-OCR 则正式开启 OCR 3.0 时代——在理解版面的基础上,进一步洞察文档深层语义,实现自动分类与业务级信息抽取,完成了从“字符感知”到“文档认知”的质的飞跃。
实力领跑:多项权威评测稳居全球第一梯队
Unisound U1-OCR是一款达到国际顶尖水平(SOTA)的文档智能理解模型,其核心优势在于突破了传统模型“只读文字、不懂排版”的瓶颈,能够像人类专家一样“看懂”复杂文档。
为适应OCR 3.0 时代对于文档业务级结构化抽取的新要求,Unisound U1-OCR 采用 ViT + LLM 架构,其中视觉编码器部分采用 NaViT 架构,实现文档分辨率动态处理,模型参数规模 3B 量级,兼顾模型计算效率与文档深层语义信息理解的能力要求。除此之外,模型还提出了多项创新举措:
首先,它拥有“先懂结构,再读内容”的智慧。传统模型往往按顺序死板阅读,而Unisound U1-OCR首创了“语义驱动+动态聚焦”策略。
如同人类阅读习惯,先梳理文档目录、标题的层级关系,再按需提取内容。模型能自动构建文档的“语义地图”,精准识别标题、图表与正文的从属关系,即使面对排版混乱的极端场景,也能条理清晰地提取信息。
其次,它具备敏锐的“空间感知力”。通过强化空间对齐模块,模型能充分利用文字在页面上的位置信息,主动理解元素间的空间布局。结合动态分辨率技术,无论是密集表格还是图文混排,它都能精准还原文档结构,彻底解决了以往模型“张冠李戴”的空间盲区。
此外,模型采用Multi-Token Prediction(MTP)技术——在预测当前 Token时,同步考虑未来多个Token的概率分布,大幅提升长文档逻辑连贯性。
配合全任务强化学习策略,增强模型对版式结构的全局预见性并在推理阶段将模型生成效率提升了80%以上。在训练阶段,采用多任务协同强化训练方案,实现文档结构还原、文档分类与信息抽取的深度对齐。
强化训练策略围绕“语义+坐标”双目标优化,针对坐标回溯的 IoU 精度进行专项强化,有效遏制定位幻觉,确保输出结果的物理可信度。通过多档位分辨率扰动与Mask采样策略,显著提升了模型多场景文档图像的理解能力。
凭借这些创新,Unisound U1-OCR在多项权威测试中均获业界SOTA表现,真正实现了从“识别文字”到“理解文档”的跨越。
1. OmniDocBench V1.5评测SOTA
在OmniDocBench V1.5评测中,Unisound U1-OCR以95.1分取得SOTA表现(如图1),领先GLM-OCR,Deepseek-OCR2,Gemini-3-Pro,GPT-5.2等主流模型,实现了精度与泛化能力的双重突破。
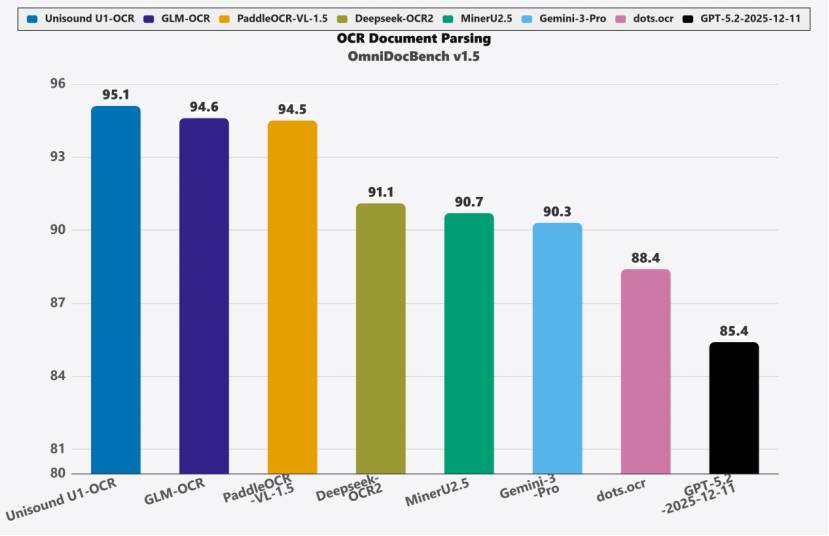
图1 Unisound U1-OCR在OmniDocBench V1.5的评测得分对比
2. D4LA评测SOTA
在D4LA评测中,F1 分数达 90.8(如图 2),大幅领先 DocLayout-YOLO(87.3)PP-StructureV3(86.0)。无需微调即可高精度解析学术论文、财务报表等 11 类高复杂度文档。
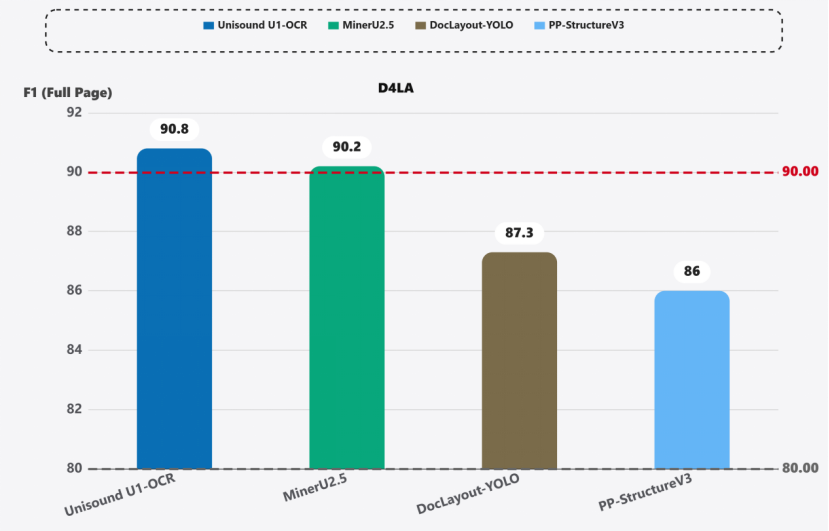
图2 基于D4LA评测的文档版面解析横向对比结果
3. DocLayNet评测SOTA
在DocLayNet评测中,F1 分数 95.9(如图 3),超越 MinerU 2.5、PP-StructureV3 等模型。在表格识别、跨页关联、微小文本检测等高难任务上优势显著,鲁棒性极强。
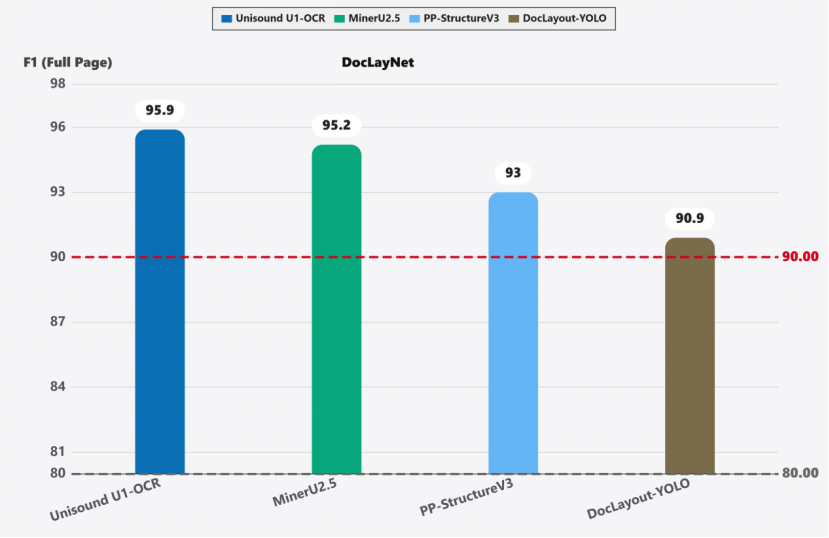
图3 基于DocLayNet评测的文档版面解析横向对比结果
4. 业务相关评测SOTA
在内部业务测试中(如图 4),其信息抽取与文书分类能力超越 Gemini-2.5-Flash、Qwen-235B-VL 等主流通用商业和开源模型。特别是在医疗入院记录、出院小结等强业务场景中,领先优势尤为明显,Unisound U1-OCR 以 3B 规模的参数获得比更大规模通用 VLM 更好的评测性能。与较小尺寸的文档解析任务模型相比,得益于模型多项创新举措,在业务级信息抽取等深层语义信息理解的能力表现更好。
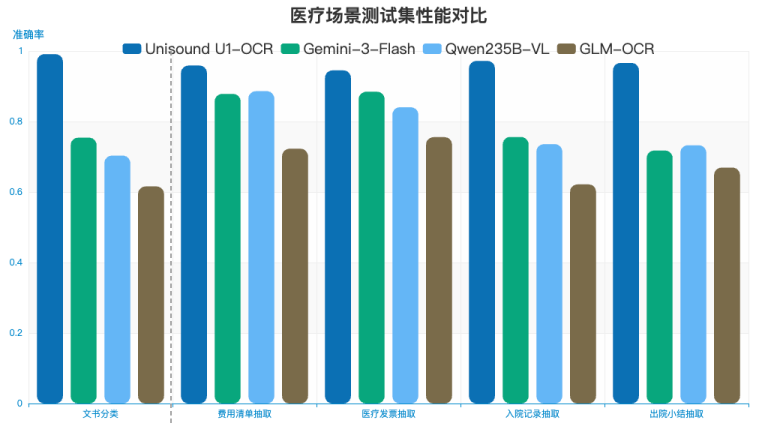
图4 基于业务数据集的文书分类和信息抽取能力横向对比评测结果
面向真实场景:4大核心能力助推U1-OCR从“读懂”迈向“执行”
作为开启OCR 3.0时代的文档智能基础大模型,除了在通用评测中斩获多项SOTA,Unisound U1-OCR更立足工业级场景需求,打造了四大核心能力,实现从‘读懂’到‘执行’的业务落地。
1. 可信可查:精准溯源,结果可验
模型独创“坐标-文本-语义”融合架构,实现像素级精准定位与完整证据链构建。在完成信息抽取的同时,系统精准标示信息在文档中的来源位置,使结果审核过程全透明、可追溯,从技术层面保障文档处理结果的可信度,彻底解决传统文档处理“结果不可验”的行业难题。
例如,在企业审核场景中,审核人员无需大海捞针般翻阅原文,点击抽取结果即可实时高亮定位原始位置。这种“人机协同”的闭环将审核耗时缩短至秒级,让人工漏检率降至最低,真正实现了“可信任的AI”。
2. 业务融合:开箱即用,Agent Ready
通用OCR工具在专业领域存在局限——例如医保结算单中“自付一”“自付二”与“个人自费”的逻辑关系,或合同中金额大小写的校验规则,都需要领域知识支撑。
Unisound U1-OCR在基础模型之上,融入了云知声在医疗、金融等领域的行业知识积累,模型可基于业务逻辑进行多字段关联校验。在内部业务测试中,面向50余种常见业务文书的分类准确率超过99%。
3. 高效部署,安全可控
模型深度支持私有化与离线部署,可在无外网环境下稳定运行,完美匹配政务、医疗、金融等高安全等级行业的数据隐私保护需求。同时,通过版面级并行解码与多Token预测架构等优化措施,一份十多页的文档,整理处理可在数秒内完成,高效的文档处理能力,让工业级文档智能能力触手可及。
4. 超强适配,攻克复杂场景
针对企业实际业务中遇到的非标准拍照、文档弯折模糊、复杂花式排版、多语言混排等各类极端复杂文档场景,Unisound U1-OCR仍能保持稳定、高精度的处理表现,彻底摆脱传统技术对标准化文档的依赖,真正适配企业真实业务的全场景需求。
真实场景验证,实力可鉴
1. 可信信息抽取案例
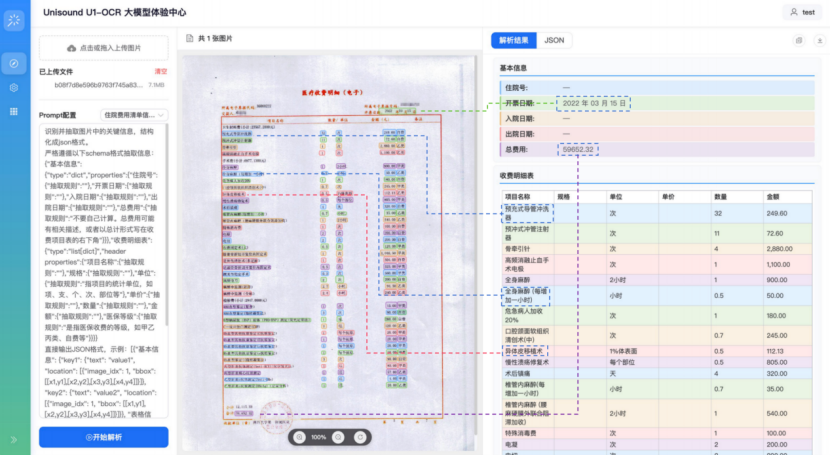
案例1:模型能够深度理解业务需求,实现数据的“即抽即用”。医疗费用清单抽取中,模型能自动理解语义,兼容不同医院的写法差异(如将原图中的“总计”“合计金额”等描述统一对齐映射至数据库的“总费用”字段),并根据业务字段抽取规则精准剔除无关的大类干扰项,实现结果直接入库。
同时,模型支持像素级的坐标回溯,通过不同颜色将抽取结果与原图位置一一对应(如图所示),这种透明的可信体系让传统的“全文重读”进化为“秒级定点确认”,在保障数据入库准度的同时,实现了业务效率的质变。
2. 业务知识融合案例
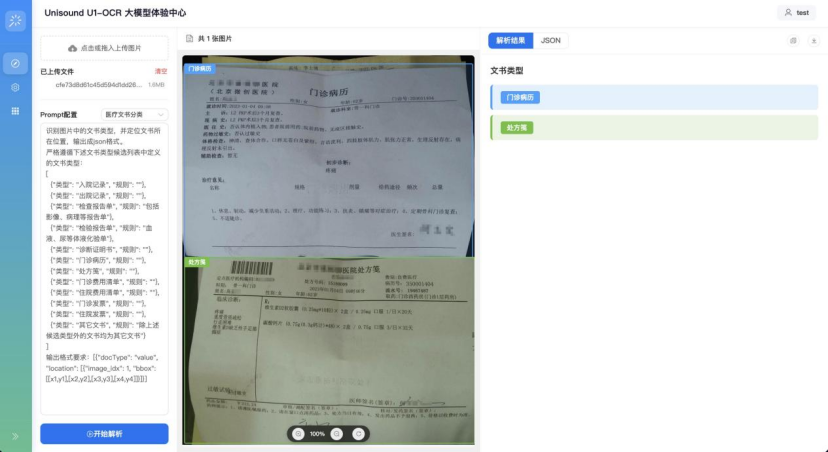
案例2:模型支持单图内多文档自动识别与分割,精准区分病历、处方等混叠文件。无需人工预分类,即可一键完成混合单据的自动化归档与提取,让海量杂乱文档处理简单高效。
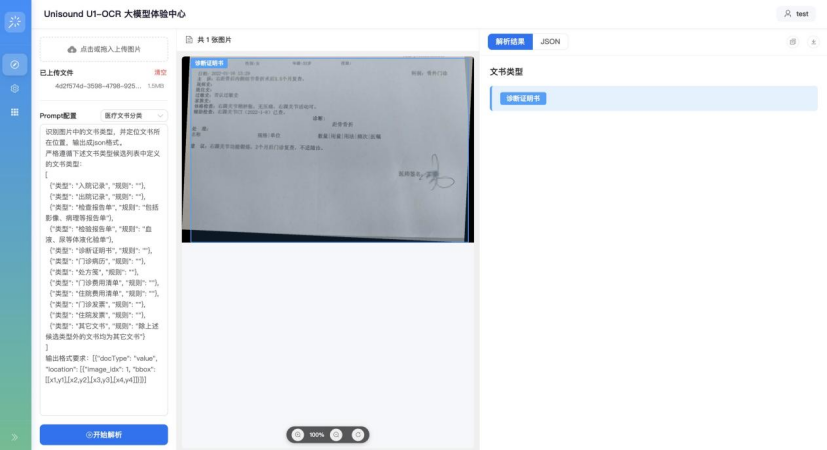
案例3:即使面对拍照遮挡、内容缺失的非理想文档,模型仍能凭借深层语义洞察准确判定类别。这种对复杂长尾场景的高兼容性,确保系统在实战中无死角,大幅提升自动化处理成功率。
3. 复杂版式识别案例
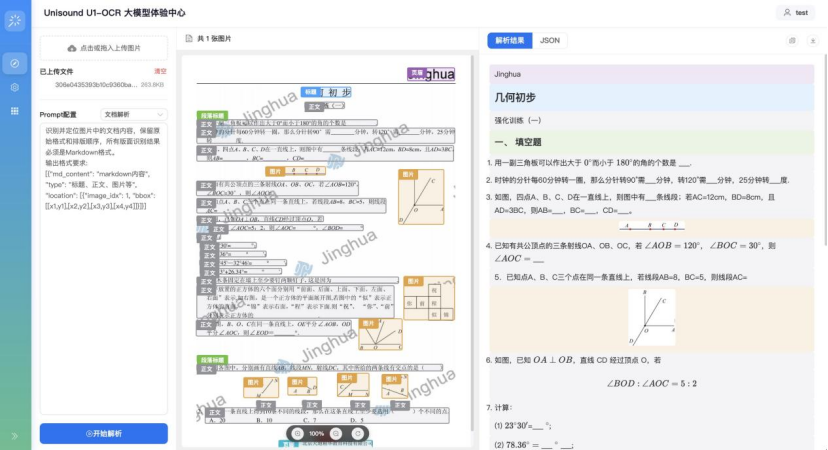
案例4:传统方案在解析报纸、期刊等多栏穿插、图文交织的复杂版面时,易陷入“下一段该读哪里”的阅读迷航。而Unisound U1-OCR模型的突破在于,它不再机械地按固定顺序扫描页面,而是像人一样,结合上下文语义与版面逻辑,自动判断段落的承接关系,精准梳理出符合人类阅读习惯的内容流。

案例5: 针对满屏水印与倾斜排版,模型可自动执行“图像净化”——智能消除水印干扰,精准校正扭曲版面。无论原图多杂乱,都能输出布局规整、内容清晰的标准化文档,为后续识别奠定干净基础,彻底消除干扰隐患。
案例6: 面对跨行、跨列及嵌套的复杂表格,模型不仅能精准解析内容,更能完整保留原始行列结构与逻辑关系。输出结果直接可用、无需二次调整,无论是统计报表还是工程图纸都能轻松解析。
Unisound U1-OCR开启OCR 3.0时代,标志着AI从单纯“识字”跃迁至“理解业务逻辑”。这不仅是文档智能的革新,更是云知声迈向AGI的关键一步。我们将以多模态文档为知识入口,赋予机器自主推理与证据溯源能力,推动AI从感知走向认知。
(来源:DoNews)
