2026春节档票房突破50亿元 这些上市公司受益
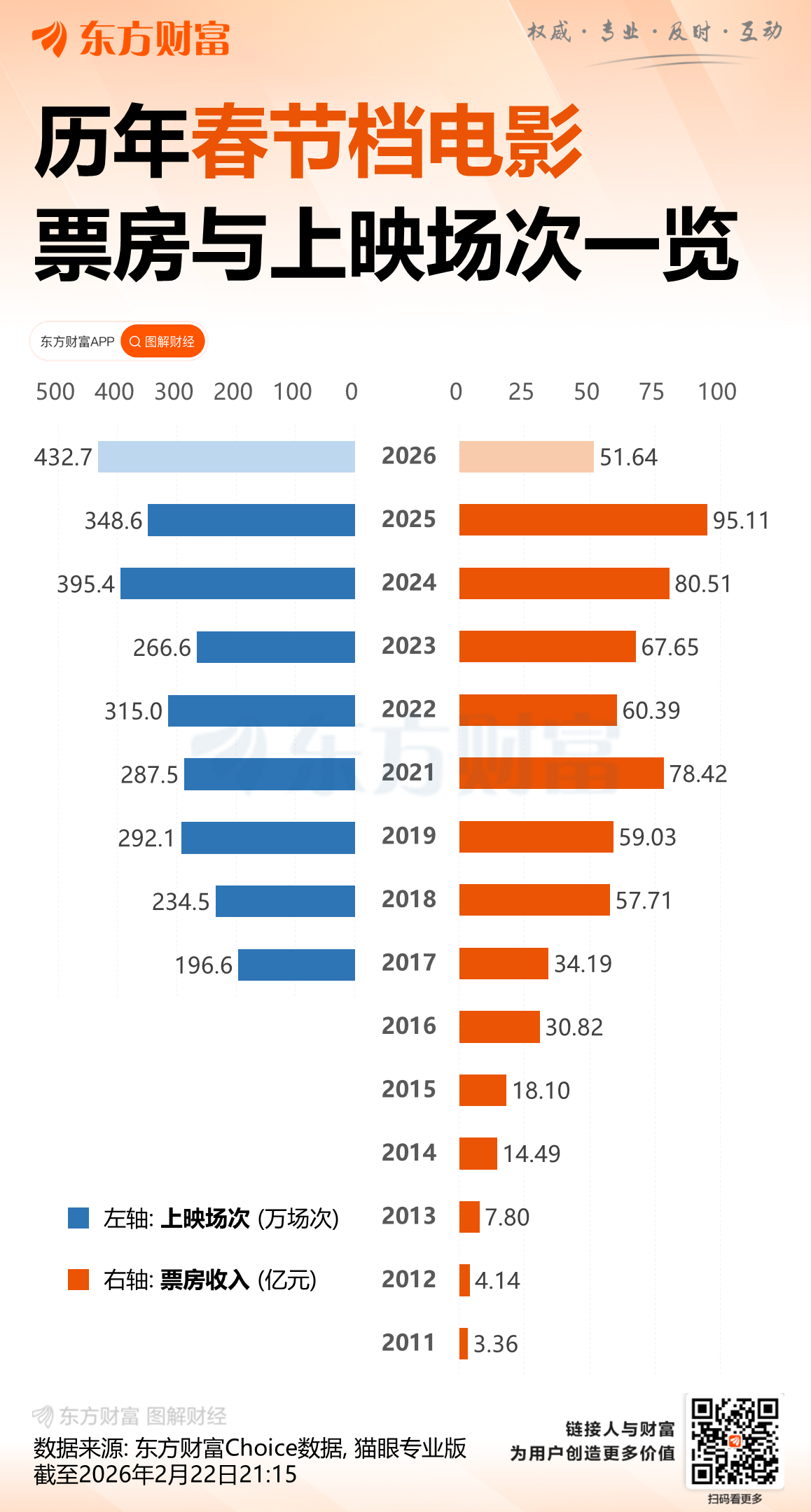
截至22日18时,据猫眼专业版数据,2026年春节档档期总票房(含预售)破50亿,《飞驰人生3》《镖人:风起大漠》《惊蛰无声》分列前三位。
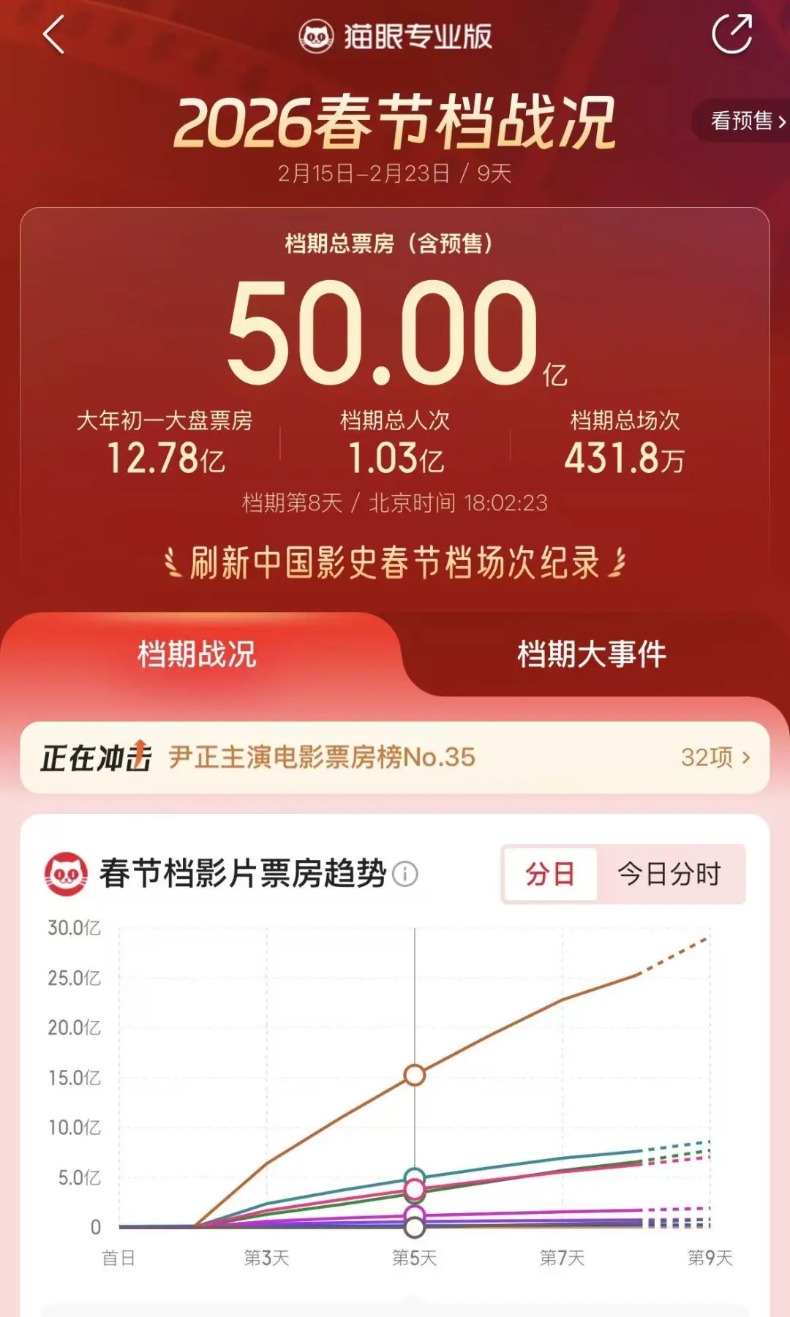

此外,据网络平台数据显示,2026年中国电影市场累计票房超9.70亿美元,超北美票房成绩,暂列全球单一市场票房冠军。
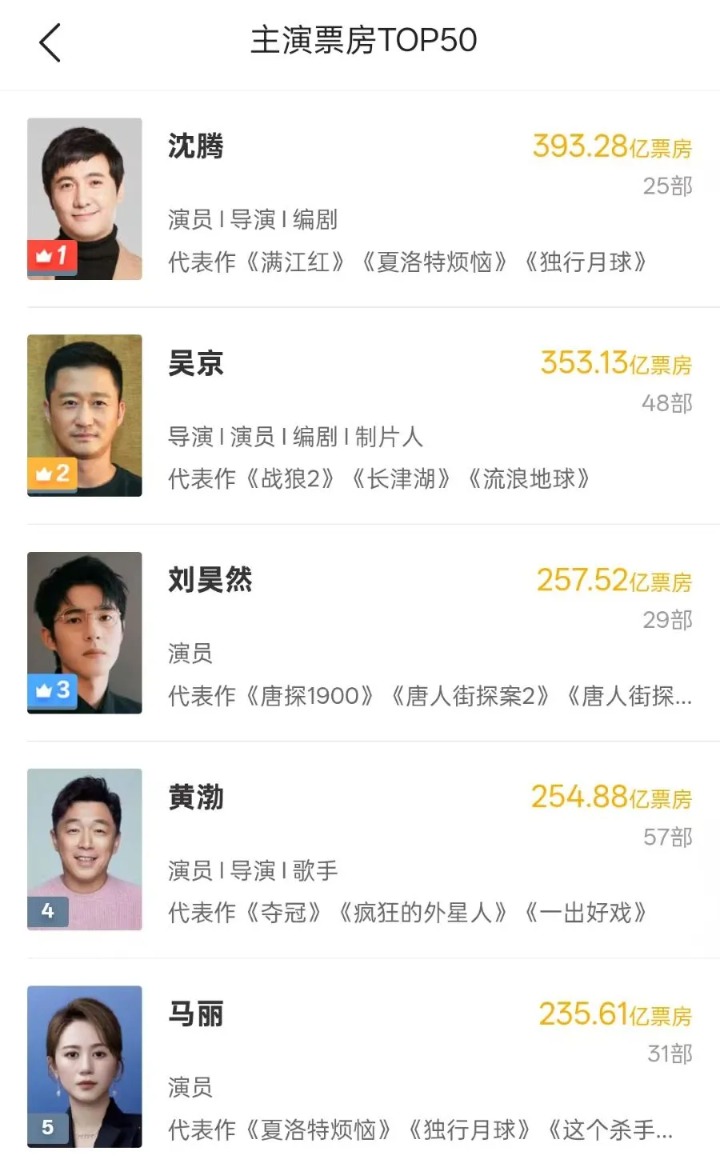
随着《飞驰人生3》的热映,演员沈腾的主演电影票房累计已突破393亿元,登顶主演票房榜第一,吴京和刘昊然紧随其后。目前,《飞驰人生3》的预测票房为42.75亿元,沈腾有望凭本片成为首位主演电影票房破400亿元的演员。
市场下沉
据证券时报,作为“史上最长春节档”,9天假期为票房释放提供充裕窗口。从单片票房情况来看,市场呈现“一超多强”的格局,头部影片贡献显著,产业链上市公司深度参与,头部影片公司多片布局已成常态。
中金公司研报预测,今年春节档总票房或介于65亿元至85亿元之间,头部影片的表现将对票房最终落点具有重要影响。
猫眼专业版数据显示,今年春节档电影平均票价为48.5元,较去年春节档50.8元有所下降,创下近五年新低,一定程度上降低观影门槛,释放了消费需求。
票价的下降尤其激活了下沉市场。电影数据分析师陈晋表示,截至目前,三、四线城市贡献了今年春节档总票房的53.72%,较去年大幅增长,同时也是历年春节档最高贡献率。另据灯塔专业版《2026春节档中后期市场观察》,《飞驰人生3》上映前四天,四线城市票房占比分别为29.18%、30.58%、31.87%、32.16%,市场持续下沉。
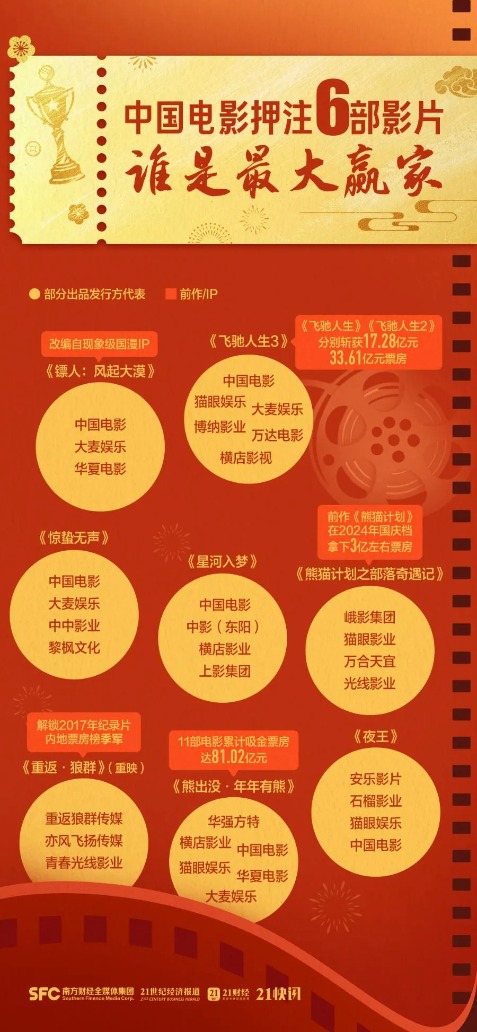
谁是最大赢家
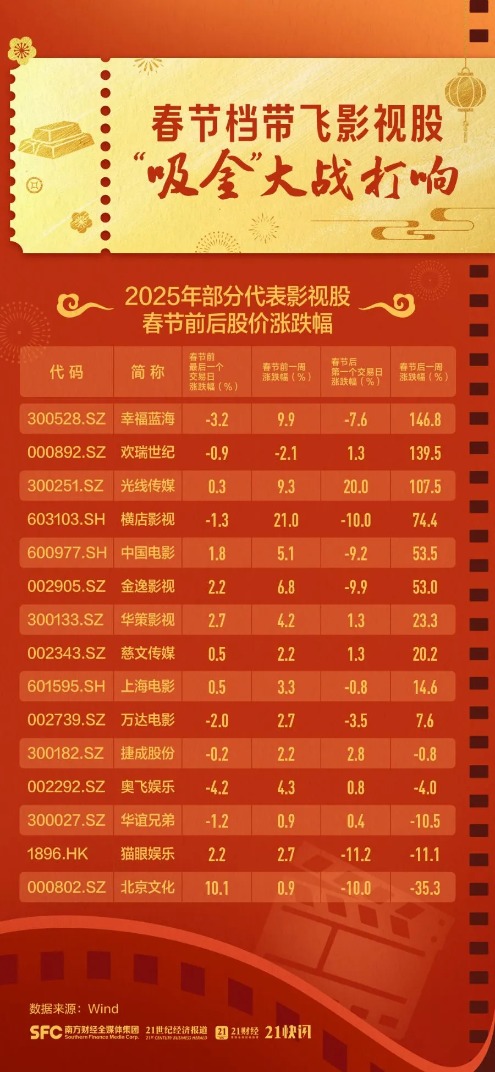
春节档的竞争本质上是影视资本的博弈。2026年春节档,多部影片背后有上市影企参与,包括光线传媒、中国电影、横店影视、幸福蓝海、博纳影业、金逸影视、上海电影、万达电影、完美世界等多家上市公司。

(来源:天天基金网)
东财图解·加点干货