又一国产旗舰模型开源,海外网友:中国AI开源四巨头已成
作者 | 陈骏达
编辑 | 漠影
最近几周,国产开源模型迎来一波集中爆发,互联网大厂和AI独角兽们纷纷甩出自家的开源王炸,接力登顶全球开源模型榜首。而就在本周,又有一款国产开源模型火爆全网。
这一模型来自素有“中国OpenAI”之称的智谱,是其最新一代旗舰模型GLM-4.5。发布时机也十分凑巧——刚好卡在网传的OpenAI的GPT-5发布之前,同样主打推理、编程、智能体等能力。
不过,智谱已经凭借开源抢占了先机,在国内外提前收获了一波流量,官宣推文获得77万+阅读,还获得开源托管平台HuggingFace CEO的转发支持。
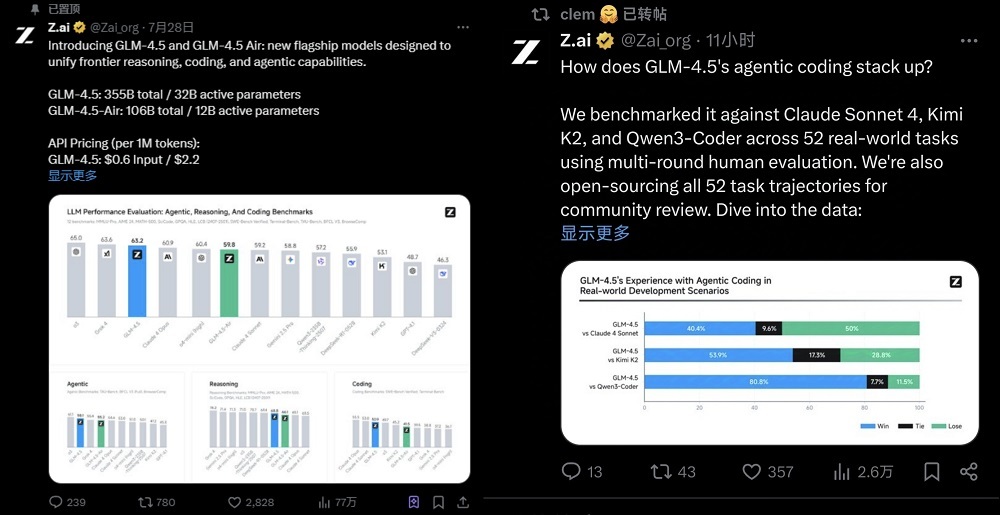
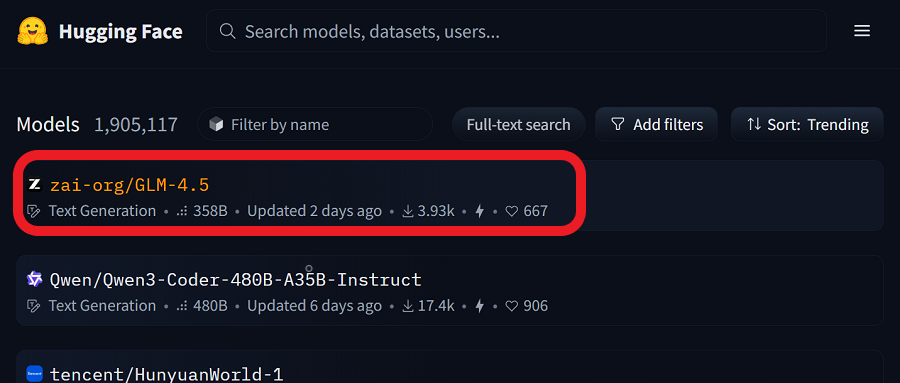
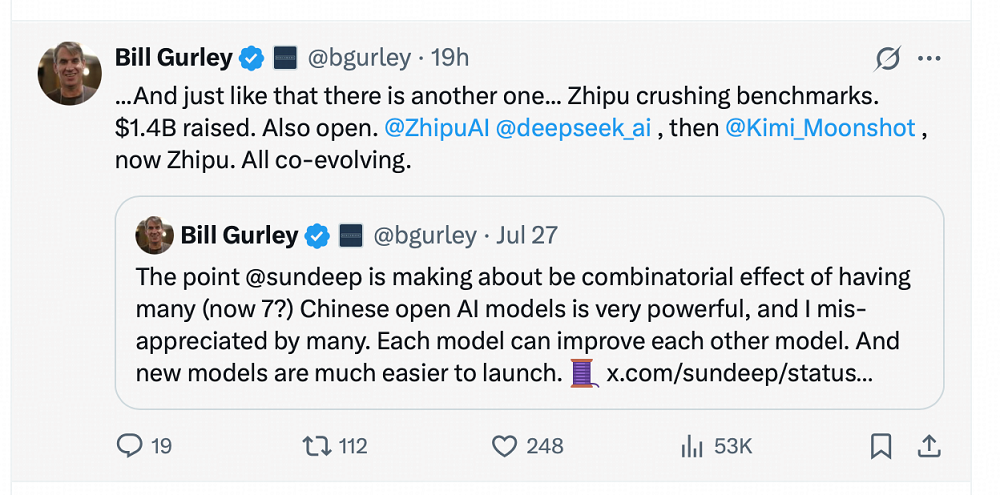
发布后不到48小时,GLM-4.5已经冲上了HuggingFace趋势榜第一名,成为全球最受关注的开源模型之一,GLM-4.5-Air则位列第六。硅谷BenchmarK风投公司合伙人Bil Gurley发文称:中国开源AI模型所产生的组合效应非常强大,模型之间都可以互相改进,新模型的推出也更为容易。
值得注意的是,在WAIC前后,中国大模型的开源相继“出圈”,月之暗面的K2、阿里的多款模型均有不俗表现,之后智谱GLM模型接力。就在今天,Hugging-Face开源模型榜单前10名几乎全是中国大模型,CNBC认为,中国企业正在研发的人工智能模型不仅智能化水平提升,使用成本也持续降低。
更有一位海外AI博主制作了一张形象的梗图,形容当前AI竞争格局的演变:全球AI大模型现已分裂为以中国模型为代表的开源派,与美国模型为代表的闭源派。近期,继DeepSeek、Qwen之后,Kimi、GLM等国产模型也相继重磅开源,给中国开源模型再添猛将,仿佛形成了中国AI“开源四杰”,与国际上的GPT、Claude、Gemini、Grok组成的 “闭源四强”分庭抗礼。

GLM-4.5定位为融合推理、编码和智能体能力的智能体基座模型,在涵盖推理、编程、智能体等场景的12项基准测试中,GLM4.5的综合性能取得了全球开源模型SOTA(即排名第一)、国产模型第一、全球模型第三的成绩。
榜单之外,智谱还在真实场景中测试了模型的智能体编程能力,平行比较了Claude-4-Sonnet、Kimi-K2、Qwen3-Coder等模型。为确保评测透明度,智谱公布了上述测试中涉及的全部52道题目及Agent轨迹,供业界验证复现。这点也获得网友们的赞许。
同时,智谱为模型提供了极具性价比的API定价,API调用价格低至输入0.8元/百万tokens、输出2元/百万tokens;高速版最高可达100 tokens/秒。此外,用户也可在智谱清言和z.ai上免费使用满血版的GLM-4.5。
近期,智东西已对GLM-4.5的多项能力进行了深度体验,这款模型在实际生产场景中的效用令人惊喜。
体验链接:
https://chatglm.cn
https://chat.z.ai/
模型仓库:
https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
一、GLM-4.5一手实测:一句话打造完整数据库,思考过程简洁明晰
目前,已有许多国内外网友上手体验GLM-4.5模型,用它打造AI私人健身教练、生成网页游戏、3D动画等,其编程能力、完成长序列复杂任务的能力给人留下深刻印象。
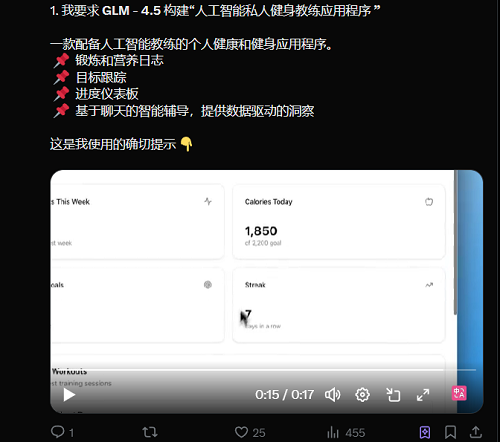
这得益于GLM-4.5本次主打的智能体能力。相较于传统的问答、摘要、翻译等静态任务,智能体任务对模型提出了更加严苛且立体的能力要求。集中展现了大模型在感知、记忆、规划、执行等方面的关键要素,也为后续多维能力提供了基础。
智能体往往面向开放式环境,需要模型具备持续感知、长期规划与自我修正能力。同时,智能体任务是一种复合流程,不仅涉及语言处理能力,还要求模型统筹调用工具、执行代码、操控接口,甚至进行多轮交互协作,真正考验模型的综合调度能力。由此可见,智能体任务不仅是一种普通的任务形态,也可以说是一种“压力测试”。
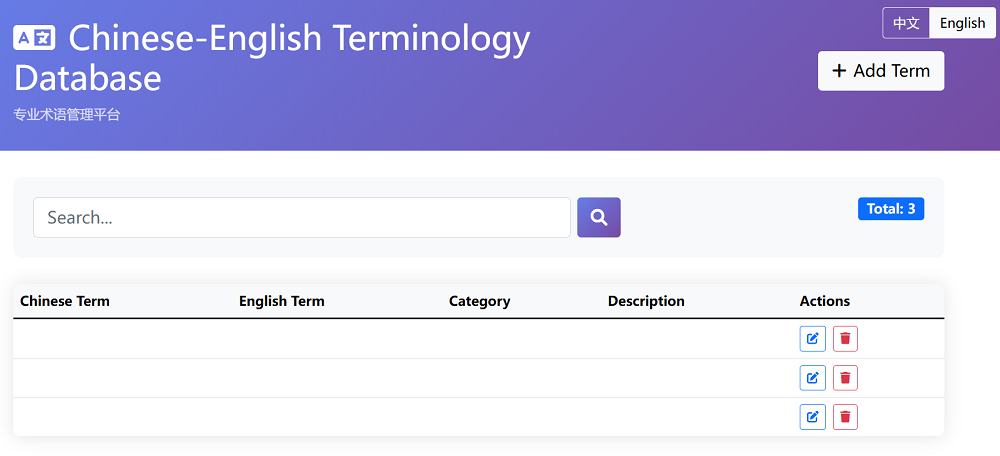
全栈开发便是一种典型的智能体任务。为测试相关能力,智东西向GLM-4.5提出了一项较为完整的开发任务——使用PHP+MySQL打造一个具有增删改查功能中英双语的术语库。这项任务的难点之一在于,模型需要自行规划项目的框架、明晰功能需求、数据库具体设计等元素,如真正的工程师一般全面思考、解决问题。
智东西也曾将类似的题目交给其他模型,不过,许多模型都无法对项目框架进行合理规划,甚至选择在一个网页文件中开发所有功能。因此,最终交付的结果无法部署在生产场景,更别提进一步修改、扩展了。
令人惊喜的是,GLM-4.5交付的结果较为完整,实现了既定的功能,并且速度较快,2分钟左右便完成了3个核心页面的开发,最终部署的效果如下:
这一结果或许得益于GML-4.5正式开始生成代码前清晰的思考过程:它准确地判断了项目性质,也明白应该生成哪些文件,这为后续的开发提供了明确的指引。思考过程也不拖泥带水,看上去简洁清晰。

▲部分对话记录:https://chat.z.ai/s/50e0d240-2034-407b-a1b3-94248dd5f449
智谱的官方Demo则展示了GLM-4.5的更多能力,例如,它可以根据用户需求,准确地复刻YouTube、谷歌、B站等网站的UI界面,可用于Demo展示等需求。
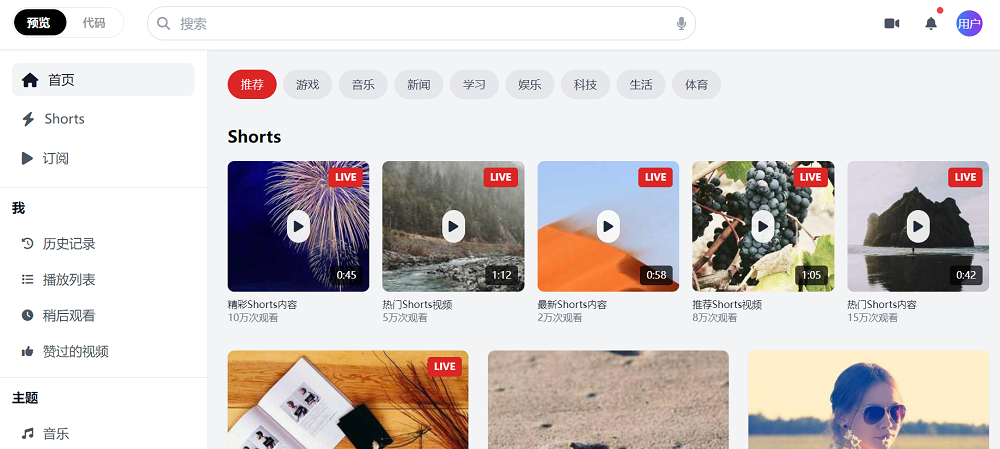
▲对话记录:https://chat.z.ai/s/01079de2-a76d-41ee-b6ee-262ea36c4df7
或是打造一个让用户自主设计迷宫,系统查找路径的网页。

▲对话记录https://chat.z.ai/s/94bd1761-d1a8-41c9-a2f4-5dacd0af88e9
这种全栈能力不仅能用于实际生产场景,拿来整活儿也是不错的。智谱官方打造了一个量子功德箱,能实际互动,并将数据保存到后台。

不过,GML-4.5开发上述项目的过程或许更值得深入探讨。翻看智能体的执行轨迹,可以看到,在与开发工具结合后,GLM-4.5可以更为端到端地完成任务。它先是创造了待办清单,然后逐步完成任务,总结开发进展,并在用户提出修改意见时,进行全面的核查和调试。
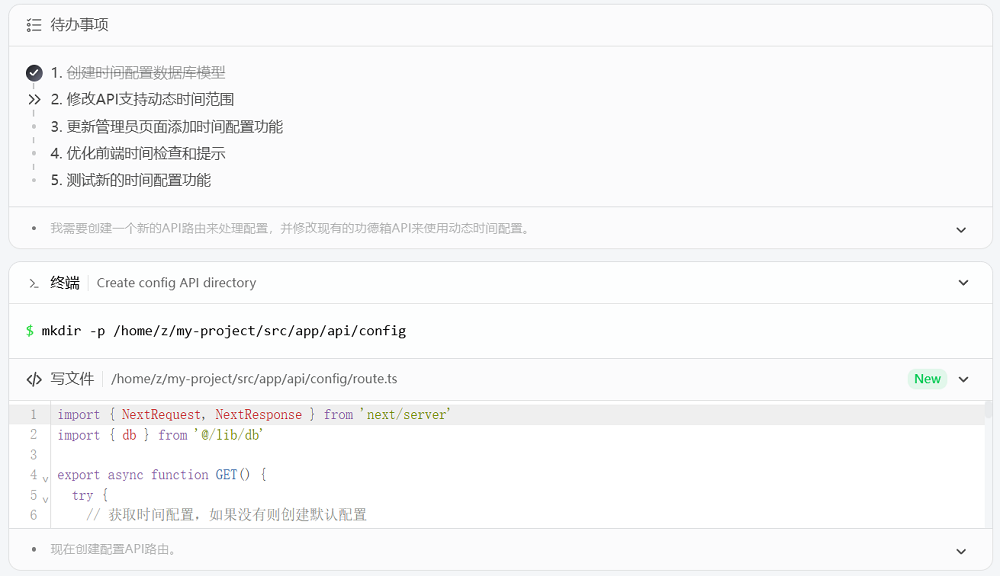
▲对话记录:https://chat.z.ai/s/1914383a-52ac-48b7-9e92-fa105be60f3e
GLM-4.5还在PPT制作这一场景展现出不错的能力。它可以按照用户指定的页数、内容等打造完整、美观的PPT,并结合搜索工具丰富PPT的视觉体验。例如,下图中,GLM-4.5为传奇短跑运动员博尔特打造了一份职业生涯回顾PPT。
▲对话记录:https://chat.z.ai/s/544d9ac2-e373-4abc-819b-41fa6f293263
我们已经在上述多个案例中直观感受到了GLM-4.5的能力。那么,这款模型背后究竟依靠哪些技术创新,才能实现如此表现?对此,智谱在同期发布的技术博客中给出了答案。
二、参数效率实现突破,兼容多款编程智能体
GLM-4.5在训练流程整体分三步走,从底层架构、任务选择到优化策略,每一阶段逐步推动模型能力提升。
首先在预训练阶段,GLM-4.5系列模型借鉴了DeepSeek-V3的MoE架构,不过在注意力机制方面仍然使用结合部分旋转位置编码(Partial RoPE)的分组查询注意力(Grouped-Query Attention)。
这一机制从ChatGLM2沿用至今,能规避多头潜在注意力(MLA)对张量并行处理带来的挑战。智谱还配置了较多的注意力头,因为该团队发现,增加注意力头能在推理基准测试中显著提升模型性能。
GLM-4.5和GLM-4.5-Air均拥有MTP(多token预测)层,让模型在一次前向计算中,同时预测多个后续token。实测证明,这一机制可显著加速推理过程。
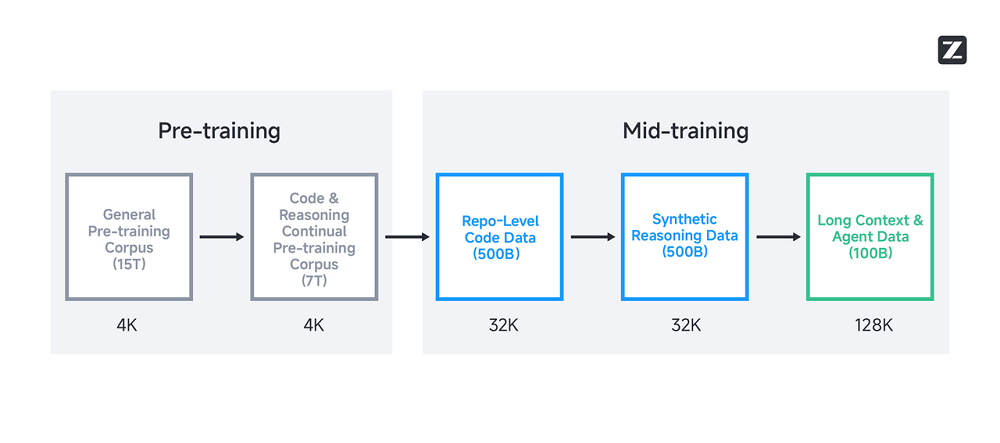
进入中期训练阶段后,智谱开始针对更复杂、更实用的任务进行专项优化,重点强化模型在代码和推理方面的能力。
例如,GLM-4.5针对代码库场景进行了专门优化,学习了跨文件之间的依赖关系;整合了GitHub上的issues和PR,进一步提升软件工程能力;并将训练序列长度扩展至32K,从而具备了处理大型代码库的能力。这正是第一部分案例中,GLM-4.5能够自行查验和修改代码的能力来源之一。
为了进一步提升模型处理长上下文的能力,智谱将训练序列的长度从32K进一步扩展到了128K,并对预训练语料库中的长文档进行了上采样,还在这一阶段加入了编程agent的轨迹。
到了后训练阶段,GLM-4.5全面引入了强化学习,并围绕高级数学编程推理能力、复杂agentic任务和通用能力这三大关键领域,展开系统性优化。
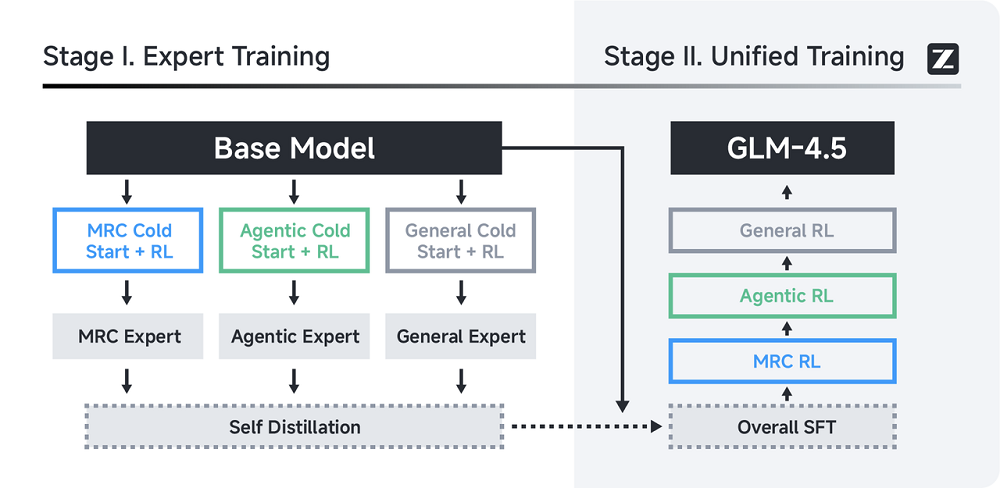
GLM-4.5在后训练阶段的强化学习部分是按照不同任务需求有侧重地展开的。针对推理任务,训练时引入了按难度递进的课程学习策略,还用动态采样温度来控制探索强度,并通过基于token 级熵的PPO自适应裁剪机制,提升策略更新的稳定性。
当模型面对的是网页搜索、代码生成这类任务时,训练方式转向了更具agentic特征的RL。数据不仅来源于自动流程,还引入了人类参与,以构建更真实的复杂多步交互场景。
编程任务则用GitHub 上的真实PR和issues来作为标准,训练中结合准确率奖励和格式惩罚,引导模型学会规范、可靠地行动。
在更通用的实际应用场景里,比如工具调用和长文档推理,GLM-4.5又采用了不同策略来补强。函数调用任务中,使用的是双轨策略:一部分是基于规则的逐步强化学习,确保工具调用准确性;另一部分则是通过奖励最终任务完成效果的方式,引导模型学会自主规划与调用工具。
同时,为了让模型更好地理解和利用长文本,智谱也安排了一个专门的长上下文RL阶段,让GLM-4.5在处理大规模文档时具备更强的推理能力。
总体来看,GLM-4.5的整个训练过程是高度工程化的:架构上通过MoE提升计算效率,训练流程中针对关键任务进行能力注入,强化学习阶段进一步拉高模型的推理上限和实用表现,最终实现推理、编码和智能体能力的原生融合。
也正是由于在工具调用、网页浏览、软件工程、前端编程等领域的优化,GLM-4.5系列模型与Claude Code、Cline、Roo Code等主流编程智能体实现了完美兼容,也可以通过工具调用接口支持任意的智能体应用。
值得注意的是,GLM-4.5还展现出更高的参数效率,参数量为DeepSeek-R1 的 1/2、Kimi-K2的 1/3,但在多项标准基准测试中表现得更为出色。在衡量模型编程能力的SWE-bench Verified榜单上,GLM-4.5系列位于性能/参数比帕累托前沿,表明在相同规模下GLM-4.5系列实现了最佳性能。
高参数效率代表了模型架构和训练策略的有效性,即在更少的参数下学到了更多、更有用的能力,这也意味着,在同等算力预算下,GLM-4.5能实现更高的性价比。
结语:开源大模型突围,智能体赛道迎来“平替”时代?
当前,以智能体为标签的AI产品层出不穷,数量庞杂,却鲜少有产品能真正获得用户的长期使用和信赖。这在一定程度上也是所有AI产品的共性问题,要解决这一问题,除了进一步打磨用户体验之外,底层模型能力的提升也至关重要。
随着Claude、GPT等海外大模型的获取越来越困难且价格愈发昂贵,国产开源模型正为开发者提供更高效的本土化解决方案。
(来源:新浪科技)
