中国最大AI开源社区,在北京办了第一场开发者大会

作者 | 陈骏达
编辑 | 云鹏
智东西6月30日报道,今天,国内AI开源社区魔搭在北京举办了其首届开发者大会。截至2025年6月,魔搭社区已经拥有超500家贡献机构,模型总量超7万个,并服务了36个国家超1600万开发者。此外,已经有超过4000个MCP服务在魔搭MCP广场上发布,支持开发者超过1亿次的调用。
魔搭社区如今已是中国最大的AI开源社区,DeepSeek系列模型、MiniMax多款模型、腾讯混元系列模型许多业界头部模型选择在魔搭社区开源。这一社区可提供模型体验、下载、调优、训练、推理、部署等服务,覆盖LLM、对话、语音、文生图、图生视频、AI作曲等多个领域。
为进一步激励开发者对社区的参与,周靖人在大会现场发布了“魔搭开发者勋章激励计划”,为在平台上作出贡献的开发者赋予荣誉和奖励,勋章获得者可以获得平台免费GPU算力支持,以及AIGC专区高阶训练券、高阶生图券等奖励,用于模型生成、模型训练、应用搭建等场景。

大会期间,还有多位嘉宾分享了他们对具身智能、端侧AI等行业重要趋势的见解。通义千问负责人林俊旸更是提前预告,该团队将于下个月推出编程能力更强的Coder模型。
会后,周靖人接受了智东西等少数媒体的采访。周靖人向智东西说道,魔搭既是一个社区,也是一个技术产品,要随着AI技术的发展而发展。魔搭正在快速迭代其对新技术、新产品、新工具的支持,也希望有更多开发者能加入到魔搭社区本身的开发过程中。
一、魔搭周靖人:模型已成重要生产元素,要帮开发者“找、用、学、玩”
周靖人认为,模型现已成为重要的生产元素,并成为了新一代应用的核心。在大模型技术快速迭代的过程中,开源开放是大模型生态发展的核心力量。
魔搭在成立之初就遵循了开放、中立、非盈利的原则,这一理念吸引了诸多开发者和企业共同参与生态建设。回顾发展历程,魔搭见证了许多顶尖开源模型的发布。

2023年,业界第一个文本生成视频的开源模型在魔搭社区发布。同年,百川智能、上海人工智能实验室书生系列大模型、零一万物Yi模型等业界领先模型均在魔搭社区开源首发。
2024年,魔搭社区面向AI创作者与设计师群体推出AIGC专区,提供图片、视频创作和模型训练等服务。
2025年,DeepSeek系列模型、阶跃星辰开源的Step-Video-T2V视频生成模型和Step-Audio语音交互模型在魔搭社区首发。
开源开放降低了开发者和企业使用先进AI技术的门槛,并且无需担忧因为使用某一项技术而被绑定。模型开发者能从中获取社区反馈和建议,从而形成正向循环。
具体到服务层面,魔搭能在找模型、用模型、学模型、玩模型这四大领域为模型算法开发者、AI应用开发者和模型爱好者提供帮助。
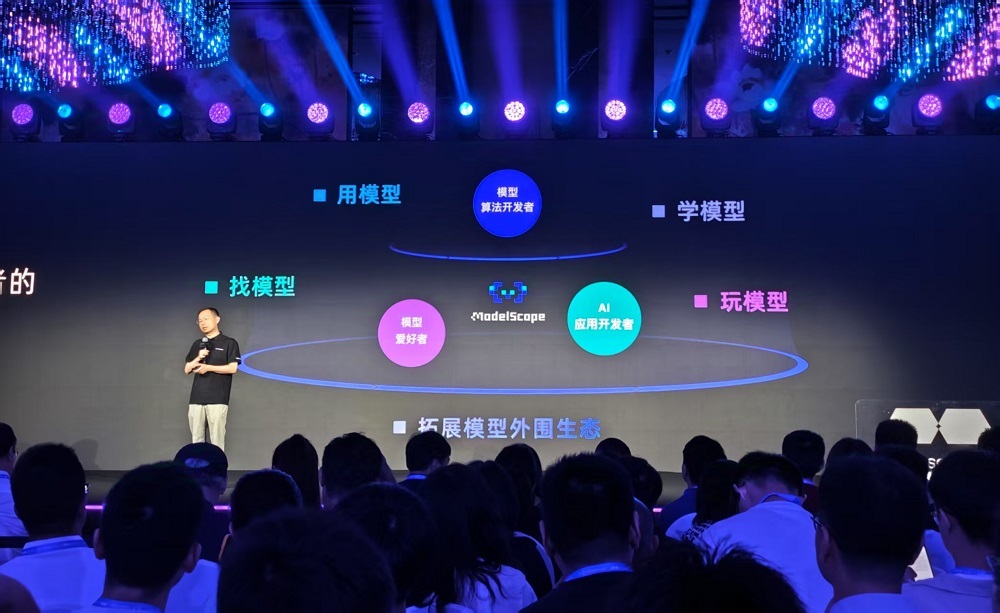
社区对模型家族进行了分类,并配备丰富的案例和API接口,帮助用户快速将模型集成到实际业务中。同时,云端Notebook功能提供了低成本的开发环境,便于用户高效探索业务场景。
为简化大模型与工具的对接流程,魔搭推出了MCP广场,汇聚数千款MCP服务及托管方案,并开放第三方集成接口。支付宝、MiniMax等创新服务在此独家首发,进一步拓展了生态应用。
在开发支持方面,魔搭提供了涵盖训练、推理、微调和评估等流程的SDK工具包,目前装机量已突破900万次。
周靖人分享,在这样一个技术变革的时代里,能够让更多的人使用AI,能够让AI的使用触手可及,普惠到社会的方方面面,是魔搭与开发者努力的重要方向。
二、无问芯穹汪玉:端侧AI面临算力能效困局,软硬件协同设计可实现突破
大会主论坛上,清华大学电子工程系系主任、无问芯穹发起人汪玉从硬件与算法的协同优化角度,探讨了端侧AI的挑战与未来。汪玉认为,AI技术正经历从云端向终端设备的迁移,随着AI模型规模的扩大,端侧设备在算力和能效上面临巨大压力。
与云端侧重多用户并发不同,端侧AI更强调低延时响应和单用户体验,当前端侧AI的理想推理速度大约为100-1000token/s,但端侧AI硬件的能力离这一目标还存在显著差距。
汪玉为上述问题提出了多个突破方向:通过芯片架构创新和存算一体技术提升硬件性能,采用模型压缩技术开发高效小模型,以及针对具体应用场景进行算法优化适配。

他特别强调,国内产业需要打通从算法设计、软件开发到硬件制造的全栈协同创新。在硬件层面,其团队已在FPGA上实现55token/s的推理速度。
汪玉特别看好具身智能的发展前景,认为这是将数字智能延伸至物理空间的重要方向。他呼吁产业界通过软硬件协同设计、共建数据生态,共同推动端侧AI和机器人技术的创新发展,构建面向未来的智能算力基础设施。
三、星海图赵行:机器人硬件形态趋于收敛,具身智能需要自己的“ImageNet”
主论坛上,清华大学特别研究员、星海图联合创始人赵行进一步分享了具身智能相关的话题。他认为,当前以ChatGPT为代表的离身智能(Disembodied AI)已通过图灵测试,但具身智能(Embodied AI)仍处于早期阶段,其核心瓶颈在于如何在正确的机器人本体上获取高质量数据,并构建可泛化的模型。
赵行强调,具身智能的突破需要类似计算机视觉领域ImageNet的标准化数据集,但由于机器人需要进行闭环测试,且硬件形态各异,数据采集和模型开发更为复杂。
标准化的硬件平台是突破上述问题的关键。星海图已经发布了3款机器人本体,计划在今年年底前采集超过1万小时的真实世界数据,涵盖工业、家庭、商业等多样化任务。
在模型架构上,星海图提出了“快慢双系统”的具身基础模型(Embodied Foundation Model),结合多模态大语言模型(慢思考)和轻量化执行模型(快执行),实现任务规划与实时闭环控制。
展望未来,赵行预测机器人硬件形态将趋于收敛,基础模型的泛化能力将在2026年迎来爆发,世界模型技术将增强机器人的预测与自主学习能力。他呼吁全球开发者共同构建具身智能生态,推动其在真实场景的大规模落地。
四、通义千问林俊旸:预训练技术仍有空间,Qwen Coder模型下月发布
在下午的主题论坛上,通义千问负责人林俊旸分享了他们的开源模型实践经验。
今年4月底,Qwen3系列模型迎来发布。模型参数量从0.6B到-235B不等。林俊旸称,这一代模型主要有三大特点:
混合推理模式:Qwen3全系列都支持混合推理,也就是说在一款模型内实现推理和非推理模式,并允许开发者自主选择模型的推理长度。但林俊旸认为,这还不是推理模型的理想形态,未来模型还需要具备自己决定是否进行推理的能力。
更多语言支持:Qwen从1.5系列就开始关注多语言,目前Qwen3支持119种语言和方言,在下一版本Qwen会扩展对非洲地区语言的支持。
MCP增强:Qwen3在训练数据方面针对MCP进行了增强,这本质上提升了模型的Agent能力。
林俊旸透露,Qwen团队内部更加关注MoE模型Qwen3-30B-A3B和稠密模型Qwen3-4B。Qwen3-30B-A3B在能力和部署难度上实现了平衡,在Qwen团队的内部测试中甚至超过了14B的稠密模型。
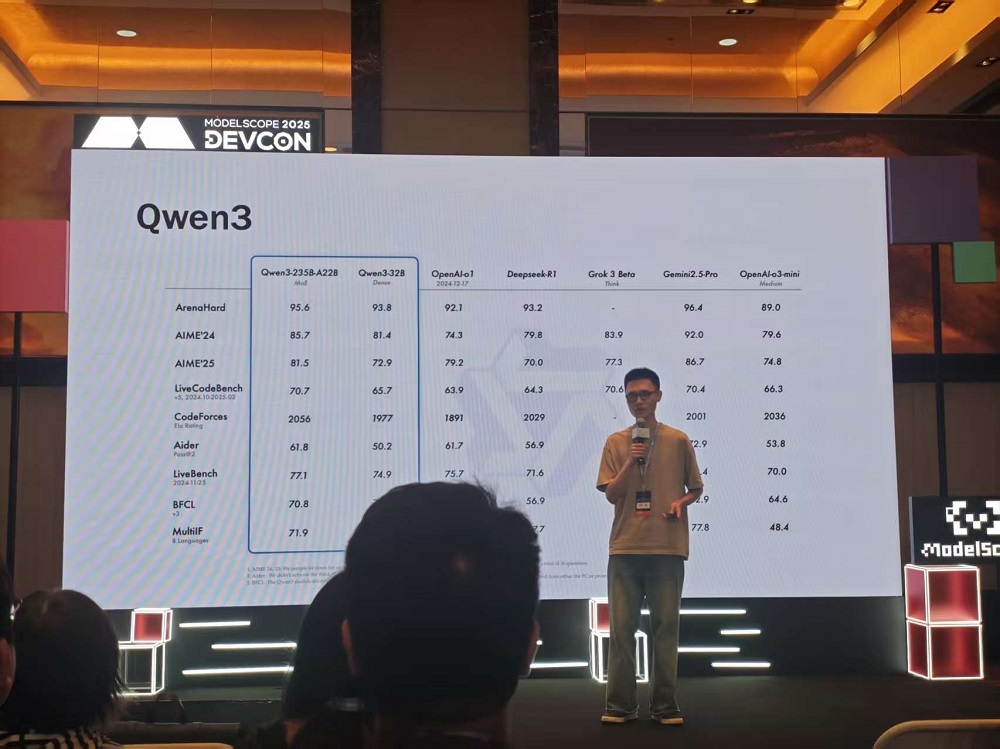
Qwen3-4B专为手机端侧设计,做了极致的剪枝和蒸馏,在许多场景的性能已经接近Qwen上一代72B模型的表现。
除了Qwen3之外,今年Qwen团队还带来了Qwen-3系列的嵌入模型、重排序模型以及全模态模型Qwen2.5-Omni、多模态模型Qwen-VLO等等。
谈及未来,林俊旸称,业内已经从训练模型的阶段逐渐转变到训练Agent的阶段,预训练技术发挥的空间仍然很大,可以通过打造强大的teacher超大型模型,最终做出适用于API调用的模型。
通义千问计划通过环境反馈的强化学习,教会模型实现长时程的推理。在输入和输出侧,模型的模态也会不断增加。下个月,通义千问将会发布适用于编程场景的Coder模型。
结语:中国开源AI生态狂飙,魔搭想成为“首选社区”
作为国内代表性的开源AI社区,魔搭的发展也可谓是中国开源AI的缩影。过去2年多以来,中国AI开源生态迅猛发展,诸如阿里、DeepSeek等企业的开源模型在世界范围内都具有较强的影响力。
同时,中国的开发者们也在为开源生态不断贡献新工具、新技术,相关开源成果在魔搭等平台开放获取,最终给全球开发者都带来了实实在在的价值。
周靖人称,他们希望将魔搭打造为AI开发者交流的首选社区,实现开发者与社区的共同成长,让更多的创新想法在魔搭社区碰撞,更多的AI应用在魔搭社区进行孵化,推动下一波AI技术的发展。
(来源:新浪科技)
