苹果出手:改进GRPO,让dLLM也能高效强化学习
最近,扩散语言模型(dLLM)有点火。现在,苹果也加入这片新兴的战场了。
不同于基于 Transformer 的自回归式语言模型,dLLM 基于掩码式扩散模型(masked diffusion model / MDM),此前我们已经报道过 LLaDA 和 Dream 等一些代表案例,最近首款实现商业化的 dLLM 聊天机器人 Mercury 也已经正式上线(此前已有 Mercury Coder)。

感兴趣的读者可在这里尝试 https://poe.com/Inception-Mercury
相较于自回归语言模型,dLLM 的一大主要特点是:快。而且 dLLM 不是从左到右地生成,而是并行迭代地优化整个序列,从而实现内容的全局规划。Mercury 聊天应用 demo,https://x.com/InceptionAILabs/status/1938370499459092873
苹果的一个研究团队表示:「代码生成与 dLLM 范式非常契合,因为编写代码通常涉及非顺序的反复来回优化。」事实上,此前的 Mercury Coder 和 Gemini Diffusion 已经表明:基于扩散的代码生成器可以与顶尖自回归代码模型相媲美。
然而,由于开源 dLLM 的训练和推理机制尚未被完全阐明,因此其在编码任务中的表现尚不明确。现有的针对 dLLM 的后训练研究,例如采用 DPO 训练的 LLaDA1.5 以及采用 GRPO 训练的 d1 和 MMaDA,要么收效甚微,要么严重依赖半自回归解码(使用相对较小的块大小进行块解码)。
言及此,今天我们介绍的这项来自苹果的研究就希望填补这一空白。他们首先研究了 dLLM 的解码行为,然后建立了一种用于扩散 LLM 的原生强化学习 (RL) 方法。

论文标题:DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
论文地址:https://arxiv.org/pdf/2506.20639
项目地址:https://github.com/apple/ml-diffucoder
该研究基于对 DiffuCoder 的分析。这是一个 7B 级的针对代码生成的 MDM,苹果使用了 1300 亿个有效 token(arXiv:2411.04905)来训练它。该模型的性能可比肩同规模的自回归编码器,为理解 dLLM 的行为以及开发扩散原生的后训练方法提供了强大的测试平台。
基于得到的分析结果,苹果还针对性地对 GRPO 进行了定制优化,提出了一种采用全新耦合采样方案的新算法:coupled-GRPO。
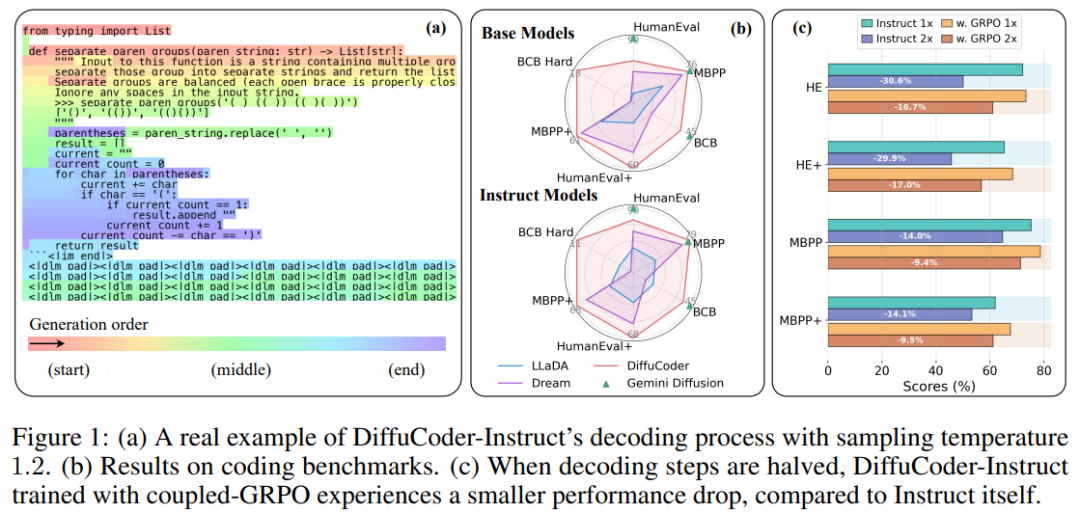
效果相当不错
DiffuCoder
首先,苹果是怎么训练出 DiffuCoder 的呢?
基本方法很常规:用大规模语料库。下图展示了其多个训练阶段。
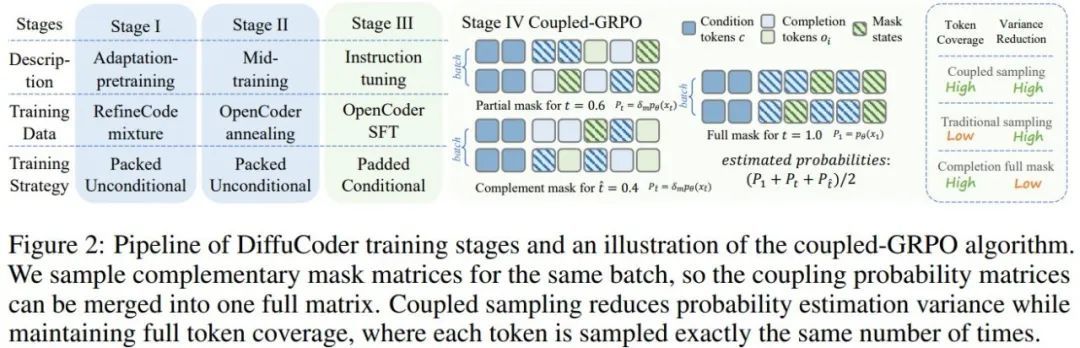
他们首先进行了类似于 Dream 的适应性预训练(adaptation pre-training)。中训练(mid-training)介于预训练和后训练之间,类似于 OpenCoder 中的退火阶段 —— 事实证明这是有效的。接下来是指令微调阶段,作用是增强模型遵循指令的能力。最后,在后训练阶段,他们采用了一种全新的 coupled-GRPO 方法(将在后文介绍)来进一步增强模型的 pass@1 编程能力。
更详细的训练配置请访问原论文。
他们在 HumanEval、MBPP、EvalPlus 和 BigCodeBench 基准上对 DiffuCoder 进行了评估并与其它一些模型进行了比较,结果见下表。
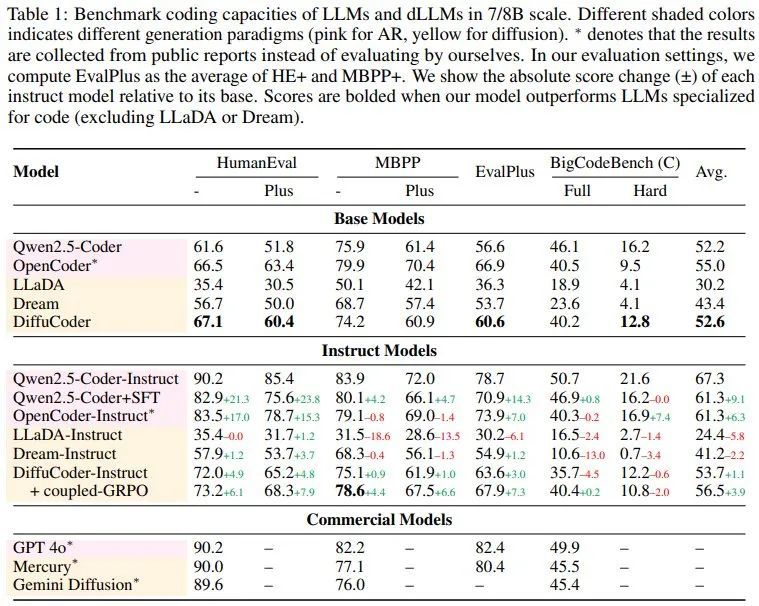
可以看到,DiffuCoder 在使用 130B 代码 token(第 1 阶段和第 2 阶段)进行持续训练后,达到了与 Qwen2.5-Coder 和 OpenCoder 相当的性能。然而,所有 dLLM 在指令调整后都仅比其基础模型略有改进,尤其是与 Qwen2.5-Coder+SFT 相比时,而后者在相同数据上进行指令微调后进步非常明显。
基于 DiffuCoder 理解掩码式扩散模型
LLaDA 和 Dream 等当前 dLLM 依赖于低置信度的重掩码解码策略,而 LLaDA 使用半自回归解码方法(即块扩散解码)可在某些任务上实现性能提升。dLLM 的另一种常见做法是将扩散时间步长设置为等于序列长度,从而有效地利用逐个 token 的生成来提升性能。鉴于此,他们引入了局部和全局自回归性 (AR-ness) 指标,以系统地研究 dLLM 的解码顺序。
具体而言,他们的分析旨在揭示:
dLLM 的解码模式与自回归模型的解码模式有何不同;
数据模态(例如代码或数学)如何影响模型行为;
AR-ness 如何在不同的训练阶段演变。
生成中的自回归性
在标准的自回归解码中,模型严格按照从左到右的顺序生成 token,以确保强大的序列一致性。然而,基于扩散的解码可能会选择无序地恢复 [MASK]。因此,他们引入了两个指标来量化扩散模型的非掩码式调度与自回归模式的相似程度,其中包括下一个 token 模式和左优先模式。
1、局部:连续下一个 token 预测
局部 AR-ness@k 是通过预测序列与范围 k 内下一个 token 预测模式匹配的比例来计算的。如果 k 长度范围内的所有 token 都是前一个生成 token 的直接后继,则就随意考虑此范围。局部 AR-ness 会随着 k 的增加而衰减,因为维持更长的连续范围会变得越来越困难。
2、全局:最早掩码选择
在步骤 t 中,如果预测 token 位于前 k 个被掩码的位置,则对全局 AR-ness 进行评分。全局 AR-ness @k 是每个 t 的平均比例,它衡量的是始终揭示最早剩余 token 的趋势,从而捕捉从左到右的填充策略。该比例随 k 的增长而增长,因为随着被允许的早期位置越多,该标准就越容易满足。对于这两个指标,值越高表示生成的自回归性越强。
解码分析
他们在条件生成过程中对以下对象进行自回归性比较:
不同的 dLLM,包括从零开始训练的 LLaDA 以及改编自自回归 LLM 的 Dream 或 DiffuCoder;
不同的数据模态,包括数学和代码;
DiffuCoder 的不同训练阶段。
1、dLLM 的解码与自回归模型有何不同?
对于自回归解码,局部和全局 AR-ness 均等于 1(即 100% 自回归)。相反,如图 3 所示,dLLM 并不总是以纯自回归方式解码。
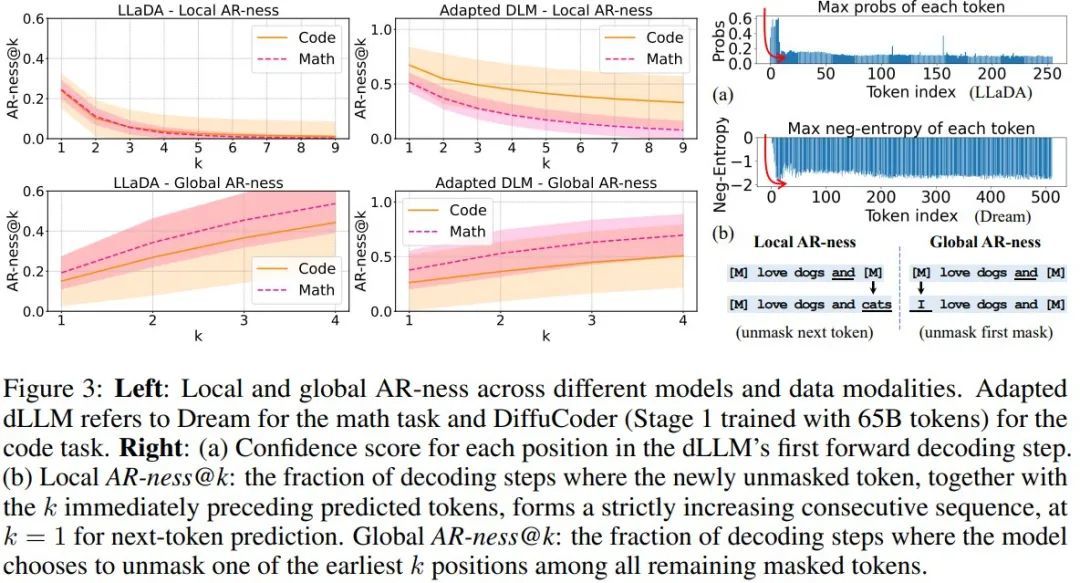
在 dLLM 解码中,很大一部分 token 既不是从最左边的掩码 token 中恢复出来的,也不是从下一个 token 中恢复出来的。这一观察结果表明,与常规自回归模型相比,dLLM 采用了更灵活的解码顺序。然而,局部和全局自回归值都更接近于 1 而不是 0,这表明文本数据本身就具有某种自回归结构,而基于扩散的语言模型无论是从零开始训练还是从自回归模型适应而来,都能自然地捕捉到这些结构。
实验结果表明,适应得到的 dLLM 往往比从零开始训练的 dLLM 表现出更强的自回归值。这是因为它们会从原始自回归训练中继承从左到右的 token 依赖关系。较低的自回归值会打破这种依赖关系,从而为并行生成提供更多机会。较高的自回归值也可能带来好处;例如,LLaDA 通常需要采用半 AR(块解码)生成来实现更高的整体性能。在这种情况下,块解码器会明确地将因果偏差重新引入生成过程。在 DiffuCoder 中,苹果该团队认为模型可以自行决定生成过程中的因果关系。
2、不同的数据模态会如何影响解码范式?
根据图 3,尽管数学和代码解码表现出了不同程度的局部自回归值,但他们得到了一个相当一致的发现:代码生成的全局自回归值均值较低,方差较高。
这表明,在生成代码时,模型倾向于先生成较晚的 token,而一些较早被掩蔽的 token 直到很晚才被恢复。原因可能是数学文本本质上是顺序的,通常需要从左到右的计算,而代码具有内在的结构。因此,模型通常会更全局地规划 token 生成,就像程序员在代码中来回跳转以改进代码实现一样。
3、自回归值 AR-ness 在不同的训练阶段如何变化?
从图 4(第 1 阶段)可以看的,在使用 650 亿个 token 进行训练后,他们已经观察到相对较低的自回归值。然而,当他们将训练扩展到 7000 亿个 token 时,AR-ness 会提升,但整体性能会下降。
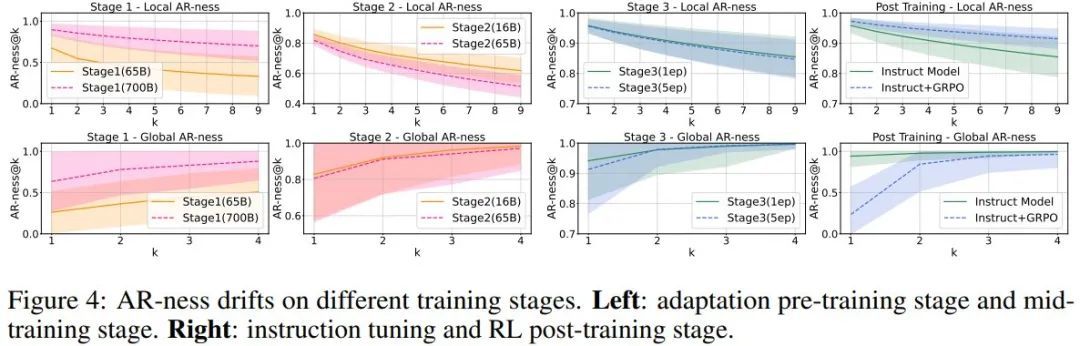
于是苹果猜想,预训练数据的质量限制了性能。因此,他们选择阶段 1 的 6500 亿个 token 作为阶段 2 的起点。在中训练(阶段 2)和指令调整(阶段 3)期间,在第一个高质量数据周期(epoch)中,该模型学习到了较高的因果偏差。然而,随着 token 数量的增加,任务性能会提升,而测量到的 AR-ness 会开始下降。这种模式表明,在第一个周期之后,dLLM 就会开始捕获超越纯自回归顺序的依赖关系。在 GRPO 训练之后,模型的全局 AR-ness 也会下降,同时,在解码步骤减少一半的情况下,性能下降幅度会减小。
4、熵沉(Entropy Sink)
当 dLLM 执行条件生成时,第一步扩散步骤从给定前缀提示的完全掩码补全开始,并尝试恢复补全序列。在此步骤中,他们将每个恢复的 token 的置信度得分记录在图 3 (a) 中。
可以看到,LLaDA 和 Dream 的默认解码算法会选择置信度最高的 token,同时重新掩蔽其余 token。LLaDA 使用对数概率,而 Dream 使用负熵来衡量置信度,值越大表示模型对该 token 高度自信。
值得注意的是,由此产生的分布呈现出特征性的 L 形模式。苹果将这种现象称为熵沉(Entropy Sink)。他们假设熵沉的出现是因为文本的内在特性使模型偏向于位于给定前缀右侧的 token:这些位置接收更强的位置信号和更接近的上下文,导致模型赋予它们不成比例的高置信度。这种现象可能与注意力下沉(attention sink)的原因有关,但其根本原因尚需进一步分析和验证。这种对局部相邻 token 的熵偏差可以解释为何 dLLM 仍然保持着非平凡的自回归性。
生成多样性
自回归大语言模型的训练后研究表明,强化学习模型的推理路径会受基础模型的 pass@k 采样能力限制。因此苹果在动态大语言模型中结合 pass@k 准确率来研究生成多样性。
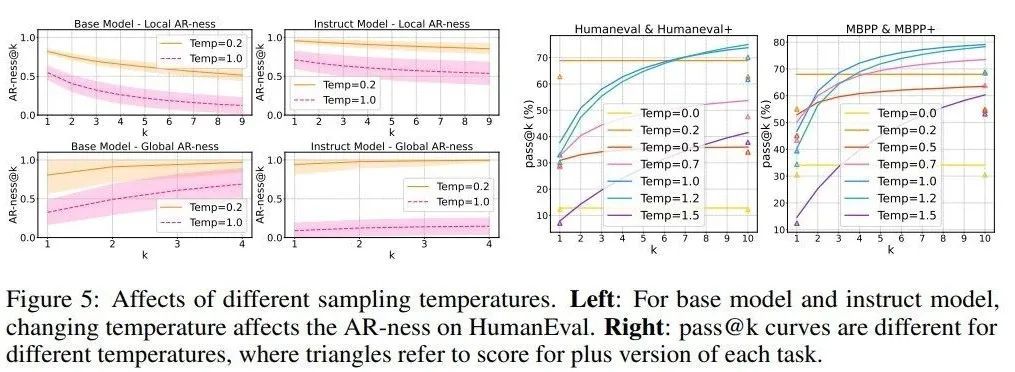
如图 5(右)和图 6 所示,对于 DiffuCoder 的基础版和指令微调版模型,低温设置下单次采样正确率(pass@1)很高,但前 k 次采样的整体正确率(pass@k)提升不明显,说明生成的样本缺乏多样性。当把温度调高到合适范围(比如 1.0 到 1.2),pass@k 指标显著提升,这说明模型其实隐藏着更强的能力。
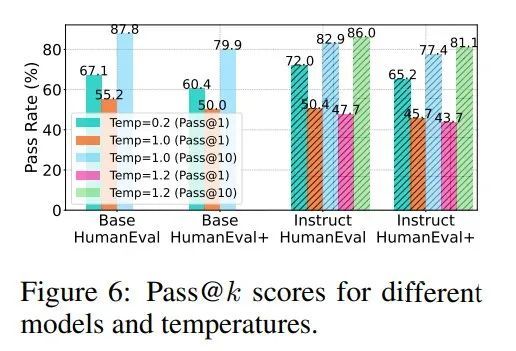
在很多强化学习场景中,模型需要先在推理过程中生成多样的回答,强化学习才能进一步提升单次回答的准确率。DiffuCoder 的 pass@k 曲线显示它还有很大的优化空间,这也正是苹果设计 coupled-GRPO 算法的原因。
另外,如图 5(左)和图 1(a)所示,更高的温度还会降低模型的自回归性,意味着模型生成 token 的顺序更随机 —— 这和传统自回归模型不同:传统模型中温度只影响选哪个 token,而动态大语言模型中温度既影响选词又影响生成顺序。
coupled-GRPO
RL 就像「试错学习」,比如玩游戏时通过不断尝试找到最优策略;GRPO 是一种改进的 RL 方法,能让语言模型学得更快更好。以前的研究证明它们对自回归模型很有效,但在扩散语言模型(dLLM)中用得还不多。
而将掩码扩散过程表述为马尔可夫决策过程,可以实现类似于 PPO 的策略优化方法。为了便于与 GRPO 集成,需要在扩散模型中对 token 概率进行近似。当前的掩码扩散模型依赖于蒙特卡洛抽样进行对数概率估计。然而,蒙特卡洛采样在 GRPO 的训练过程中会带来显著的开销。
打个比方,现在的模型计算「猜词概率」时,依赖多次随机尝试(蒙特卡洛采样),这会导致训练 GRPO 时速度很慢、开销很大。比如,原本可能只需要算 1 次概率,现在要算 100 次,电脑算力消耗剧增,这就是当前需要解决的关键问题。
在原始 GRPO 的损失计算中,仅对涉及掩码 token 的位置计算损失,导致在采样次数有限时出现效率低下和高方差问题。为提升概率估计的准确性同时覆盖所有 token,苹果提出了耦合采样方案(Coupled-Sampling Scheme),其核心思想是通过两次互补的掩码操作,确保每个 token 在扩散过程中至少被解掩一次,并在更真实的上下文中评估其概率。

coupled-GRPO 的实际实现
在实际应用中,本研究选择 λ=1,以平衡计算成本与估计精度。为进行公平比较,本研究引入一个「去耦基线(de-coupled baseline)」:该基线使用相同数量的样本,但不强制掩码之间的互补性(即两次独立采样)。
此外,在优势分数计算中,本研究采用留一法(Leave-One-Out, LOO)策略确定基线得分,这样可以得到一个无偏估计。耦合采样方案可以看作是应用了 Antithetic Variates 的方差缩减技术,并且本文还列出了用于验证奖励的详细设计,包括代码格式奖励以及测试用例执行通过率作为正确性奖励。详见原论文。
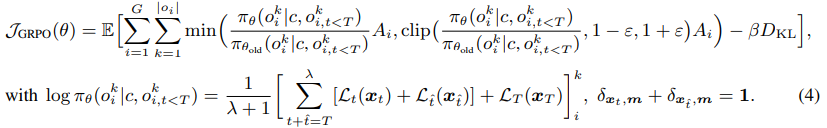
coupled-GRPO 通过互补掩码、LOO 优势估计和温度优化,在扩散语言模型的训练中实现了更稳定的奖励学习与更低的 AR-ness,显著提升了生成质量与并行效率。其实验结果不仅验证了强化学习与扩散模型结合的潜力,也为 dLLM 的实际应用(如代码生成、高速推理)提供了可行路径。
未来研究可进一步探索其在多模态生成和大模型蒸馏中的应用。
(来源:新浪科技)
