CPO,势不可挡
2025 年 OFC 展会明确表明:数据中心向 CPO 交换机的转型不可避免,其主要驱动力在于 CPO 带来的功耗节省。
从黄仁勋在 2025 年 GTC 大会上展示 CPO 交换机,到众多厂商在 2025 年 OFC 展会上演示集成在 ASIC 封装内的光引擎,共封装光学技术已无处不在。
值得注意的是,Arista 联合创始人、数据中心网络领域的长期远见者安迪・贝托尔斯海姆(Andy Bechtolsheim)尚未改变立场。在 2025 年 OFC 展会上,他继续主张线性可插拔光学(LPO)是更优选择。LPO 移除了板载数字信号处理器,功耗较传统可插拔光学器件显著降低 —— 通常减少 30-50%。更多细节可查看我的帖子。
安迪的核心论点是,至少在 1600G 代际,LPO 与 CPO 的功率效率大致相当。那么,为何要接受 CPO 额外的复杂性呢?然而,在这些更高的 SerDes 速率下,LPO 面临着 ASIC 与面板光器件之间电通道插入损耗的挑战。安迪认为,在 1600G 代际,可通过带近封装连接器的跨接电缆来缓解这一问题。
他对 CPO 的担忧包括:失去配置灵活性(所有端口必须使用相同类型的光器件)、光器件类型混合搭配的困难,以及潜在的厂商互操作性和可维护性挑战。众所周知,光模块会出现硬故障和软故障。即使是高质量光器件,硬故障率约为 100 FIT,而软故障(通常由连接器灰尘引起)更为常见。采用 CPO 时,检查或更换故障光器件所需时间长得多。更糟的是,封装内嵌入的光端口故障会导致交换机吞吐量下降,且难以更换。
这些担忧并非新鲜事,但行业在过去两年已取得显著进展。CPO 技术如今可靠性大幅提升。展望 400G 每通道 SerDes 代际,CPO 可能成为唯一可行选择。在如此高的速率下,即使是最佳的 PCB 走线或跨接电缆也可能引入过多插入损耗。届时,在封装内实现光信号传输将成为必要。
因此,若转型不可避免,为何不更早拥抱 CPO 并助力其演进呢?看看 Arista 在为其浅缓冲交换机产品线采用 CPO 之前能坚持多久,将是一件有趣的事!
CPO 集成
无论是共封装还是作为可插拔模块一部分的光收发器,其光引擎通常包含电子集成电路(EIC)和光子集成电路(PIC)。
在包含交换机或 XPU 核心的 ASIC 封装内集成这些光引擎,主要有两种方式。
硅中介层方案
核心裸片与电子 IC(EIC)可共置于硅中介层上(或通过英特尔 EMIB 等硅桥连接),而 PIC 则要么 3D 堆叠在 EIC 上方,要么放置在有机基板中。当 PIC/EIC 堆叠在硅中介层上的核心裸片旁时,它们也被称为光学 I/O。
该方案的目标是通过利用高密度 D2D 链路和中介层布线,缩短并改善核心裸片与光引擎之间的电连接。这种中介层方案允许将多个光学小芯片更靠近主裸片放置,从而实现更小的封装。
然而,将高功耗 EIC 与核心裸片共置于中介层上会使热管理复杂化。此外,若 PIC 堆叠在 EIC 上,EIC 的散热将更加困难。大型硅中介层会增加封装成本和复杂性,且中介层尺寸限制了可围绕 ASIC 布置的光模块数量。为在不增加复杂性或成本的前提下提升带宽,光引擎需要具备更高的带宽密度。
有机基板方案
第二种方案将光引擎保留在 ASIC 封装内的有机基板上(而非硅中介层)。PIC 和 EIC 被组装在一起(通常是 PIC 在底部堆叠于 EIC 上方),形成紧凑的光引擎模块,然后安装在主裸片周围的有机基板上。核心裸片通过 SerDes 接口与 EIC 通信,在最新工艺节点中,该接口通常具有 500-1000 Gbps/mm 的带宽密度。这意味着,一个面积为 625 平方毫米(每边 25 毫米)的核心裸片可向光引擎发送约 100 Tbps 的带宽。为实现超过 100 Tbps 的带宽,封装内通常需要多个核心裸片。
该方案允许光引擎在基板上间隔布置,从而在一定程度上放宽了对每个引擎的光带宽密度要求。由于引擎与主裸片距离较远,这有助于热隔离。每个光引擎可配备独立的微型散热器,或通过间隔布置使气流或冷板能够触及。重要的是,将 PIC 堆叠在 EIC 下方(最靠近基板)比反向堆叠具有更好的散热和信号性能。
由于不受大型中介层的限制,若有需要,封装可做得更大(且不会显著增加成本)以容纳更多引擎。尽管组装过程仍然复杂,但具有模块化特点。光引擎可在安装到有机基板之前进行独立测试。这是集成 CPO 的流行方案。
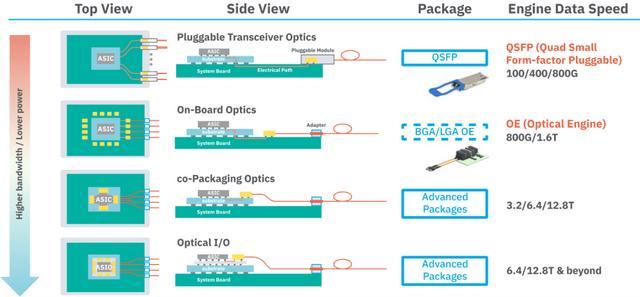
光学器件各种集成技术示意图。引自 ASE
什么是带宽密度?
并非所有 CPO 解决方案都相同。任何 CPO 解决方案的最终目标都是以最低功耗实现高带宽密度。这就引出了下一个问题:带宽密度究竟是什么?
在 CPO 和光学 I/O 的语境中,带宽密度(通常称为 “前沿密度” 或 “海岸线密度”)描述的是沿光接口集成边缘每毫米可传输的数据量,单位通常为太比特每秒(Tbps)。请注意,该指标并非在面板连接器级别测量,而是在 ASIC 裸片边缘或与 ASIC 共封装的光子小芯片 / 光引擎边缘测量。这些是封装内光纤或波导耦合的物理边界。
行业来源一致采用这一定义,带宽密度单位常为 Tbps/mm 或光纤数 /mm,具体取决于侧重点是吞吐量还是物理通道数。更高的前沿密度意味着芯片可在不增加占用面积的情况下输出更多光带宽。提升前沿密度对满足数据中心和高性能计算系统中爆炸式增长的带宽需求至关重要。
方案对比:博通 vs 英伟达
现在,为理解共封装光学,让我们更深入地考察博通和英伟达的 CPO 产品。
封装带宽
博通去年推出了 Bailly CPO 交换机。该交换机基于 Tomohawk-5 ASIC,封装内集成了八个 6.4 Tbps 光引擎,总封装外光带宽为 51.2 Tb/s(64×800 Gbps 或 128×400 Gbps)。

博通 Bailly CPO ASIC
我们预计下一代 102.4 Tbps CPO 交换机将采用演进的 CPO 架构,围绕 Tomohawk-6 裸片部署改进的硅光子引擎(每个引擎带宽 12.8 Tbps 甚至更高)。这些约 100 Tbps 的交换机可能在今年下半年面市。
博通制造的芯片可供交换机厂商用于构建系统。已有几家公司处于使用 Bailly 交换机开发交换机的不同阶段(或已进入早期采样)。在所有这些交换机产品中,均使用单个 Baily 芯片(面板具有 128×400G 端口)构建独立系统。
英伟达在 2025 年 GTC 大会上推出的共封装光学平台目标更高,可扩展至 100 Tb/s 及以上。
Quantum-X InfiniBand 交换机系统将具备:
144 个 800 Gb/s 端口(或 576×200 Gbps),总计 115.2 Tbps 带宽
四个采用 Quantum X800 ASIC 的 Quantum-X CPO 封装,每个封装具备 28.8 Tbps 带宽(144×200 Gbps 或 36×800 Gbps)
若要通过 28.8 Tbps 交换机实现 115.2 Tbps 的无阻塞交换容量,采用 Clos 架构时所需交换机数量将远多于四个。鉴于目前似乎仅有四个交换机,这看起来并非真正的 115.2 Tbps 交换机。对此有何评论?
预计 2025 年底面市。

Quantum-X 光子交换机系统。引自 2025 年 GTC 大会演示
Spectrum-X 光子以太网交换机系列将具备:
128 个 800G 端口(或 512 个 200G 端口),提供 102.4 Tb/s 带宽。这可能包含两个 Spectrum-X CPO 封装,每个封装具备 51.2 Tbps 带宽(64×800 Gbps 或 256×200 Gbps)
还将提供更大配置,包含 512 个 800G 端口(409.6 Tb/s),可能采用 4 个 CPO 封装
与 Quantum 类似,除非在交换机机箱内使用更多交换机用于芯片间连接,否则这些并非真正的 102.4 T 或 409.6 Tbps 交换机
预计 2026 年面市
因此,在容量方面,博通目前拥有 51.2T 解决方案,与当前网络需求(800G 以太网时代,100G Serdes)一致,2025 年路线图中规划了 100 Tbps;而英伟达则跨越式发展至 100-400T,以满足未来百万 GPU 集群需求(200G Serdes)。英伟达更大的带宽数字反映了其更激进的架构方案,专注于通过大规模集成(系统内使用多个光子交换机芯片)实现更高基数的交换机。
光引擎
博通 Bailly 芯片在 ASIC 封装内集成了 6.4 Tbps 硅光子基光引擎。这些高密度边缘安装的光引擎通过有机基板上的短芯片间连接直接与核心裸片交互。这种紧密集成实现了更简单的物理布局。
英伟达的 Spectrum-X(以太网)和 Quantum-X(InfiniBand)光子交换机也集成了多个 1.6 Tbps 硅光子基光子引擎。每个光子引擎采用台积电 COUPE™工艺制造,将电子裸片(EIC)堆叠在光子裸片上方。三个此类引擎集群组成可拆卸光子组件(OSA),吞吐量达 4.8 Tbps。这意味着光引擎(及其光纤接口)位于可更换模块上,与交换机基板对接,而非像博通方案那样永久粘合!
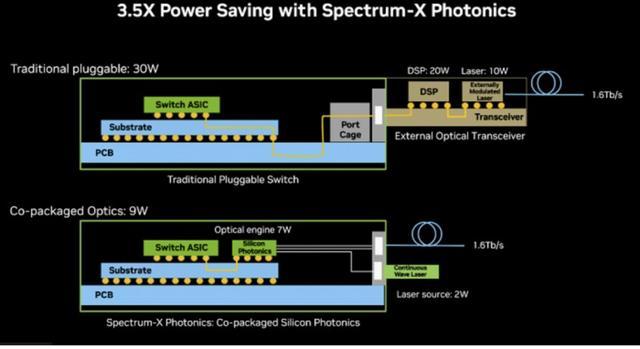
引自 2025 年 GTC 大会演示。英伟达 CPO 可视化
因此,英伟达的封装更为复杂,采用先进的 2.5D/3D 集成(引擎裸片使用台积电 SoIC 堆叠)和光部件的模块化连接系统。这在一定程度上解决了可维护性担忧。若在制造测试中发现插件模块故障,可更换为其他模块。
在 Quantum-X CPO 交换机中,每个 ASIC 封装包含 Quantum X800 28.8 Tbps 交换机 ASIC 核心,以及连接至主封装的六个 OSA 插件模块。
总之,博通方案是光器件嵌入的单封装交换机,而英伟达方案则是具备可拆卸光子模块的新型封装。
Spectrum-X CPO 封装让我们对小芯片架构有了更多了解。它似乎将主核心交换机裸片与八个 I/O 裸片紧密集成(通过裸片间接口),而光子引擎(36 个)围绕它们布置在有机基板中。这些光子引擎是否属于可拆卸 OSA 的一部分尚不可知。

Quantum-X 和 Spectrum-X CPO 封装。引自 2025 年 GTC 大会演示
光纤耦合
博通 CPO 交换机采用光引擎的边缘耦合光纤连接,以实现高前沿密度。每个光引擎 PIC 上有承载光信号的片上波导,这些波导终止于光子小芯片边缘。光纤被精确对准并永久粘合(通常使用环氧树脂)到这些波导端面。
博通已开发出高度自动化的高密度光纤连接工艺,可将多根光纤芯精确对准光子小芯片边缘。这种边缘耦合方案允许大量光通道以紧凑的占用面积从封装中引出。
在第一代 CPO 中,博通似乎使用 400G-FR4,通过 CWDM 在单根光纤上实现四个 100G 通道。如此,每个光引擎配备 16 对光纤(发送 + 接收 = 一对)以处理 6.4T 吞吐量。然而,博通可能正在开发新版本芯片,配备 64 对光纤(每对承载 100 Gbps),以支持更大基数的交换机(512×100G 端口)。
直接从光引擎引出的短光纤称为 “光纤尾纤”。光引擎引出的光纤尾纤必须路由至面板连接器,但这些尾纤短而脆弱,无法直接路由至面板。ASIC 引出的光纤尾纤通常通过连接器在交换机盒内部与更长、更坚固的光纤连接,后者再延伸至面板。
英伟达 Quantum-X InfiniBand 交换机封装每个 CPO 封装有 324 个光连接。为支持 144×200 Gbps,需要 144 对光纤(288 根光纤),剩余 36 个用于连接 ASIC 的激光器 ——18 个光子引擎各获得两个激光输入。
四对光纤(4×200 Gbps)每组汇聚为一个 DR4,并在面板处端接至单个 MPO(多光纤推入式)连接器。因此,配备 4 个 CPO 封装的交换机系统在面板处有 144 个 MPO。
尽管耦合方法的细节尚未完全公开,但英伟达很可能也在光子引擎上使用边缘耦合。
总之,博通和英伟达都必须解决大规模光纤耦合问题。博通在第一代 CPO 交换机中依靠 WDM 减少光纤数量,而从 GTC 演示中的光纤数量来看,英伟达似乎未使用 WDM。
激光器集成
CPO 设计中最大的考量之一是如何处理为光引擎内调制器提供光源的激光器。
博通和英伟达的设计均将所有高功率激光器置于主交换机封装之外,转而使用外部可插拔激光模块(外部激光源或 ELS)。这些模块可插入面板 LC 端口,接受热插拔激光 cartridges。
光纤跳线将连续波光从这些激光模块传输至共封装光引擎。该策略可保持 CPO 的低功耗并提高其可靠性。激光器的退化可能快于其他组件,因此外部激光器可轻松更换,而无需干扰交换机 ASIC。
Bailly 交换机使用 16 个高效可插拔激光模块,每个 6.4 Tbps 光引擎配备两个模块。
英伟达的方案更进一步,大幅减少了所需激光源的总数。在 Quantum-X 光子交换机系统中,仅 18 个面板连接的激光模块为所有 144×800G 光通道提供光源。每个模块集成八个激光器,为八个 1.6 Tbps 光子引擎提供光源。因此,英伟达架构的可插拔激光模块数量(按每单位带宽的模块数计算)比博通方案少 4 倍。
更少的激光器意味着需要冷却和监控的组件更少,但这也意味着若某个激光模块故障,受影响的通道会更多。
调制器
调制器是光引擎内将电信号转换为光信号的组件。它们从激光器获取稳定光,并通过将光转换为强度或相位调制的光数据流,将高速数据 “印刻” 在其上。深入理解这些调制器的工作原理是一个超出我专业领域的技术话题。
简而言之,博通很可能使用马赫 - 曾德尔调制器(MZM)。这类调制器对激光不稳定性较不敏感,对温度变化的耐受性更好,但功耗更高且占用面积更大(尺寸更大)。尽管 MZM 适用于 100 Gbps 信号传输,但在扩展至~200G 通道和数百 Tbps CPO 封装时,会面临密度和功耗限制。
这可能就是英伟达 CPO 方案选择微环谐振器调制器(MRM)的原因。MRM 占用面积更小(可很好地扩展),所需驱动电压更低,因此功耗更低。这些调制器还原生支持 WDM;每个环针对一个波长,非常适合每根光纤 8-16 个波长的系统。但这些调制器需要更多调谐(因其热敏感性)和强大的 DSP 逻辑来减少串扰。英伟达选择 MRM 表明其在 CPO 方案中对功耗节省的激进追求。MRM 的功耗约为 1-2 pJ/bit,而 MZM 为 5-10 pJ/bit。
波分复用
博通在每根光纤上使用粗波分复用(CWDM),采用 4 通道 4λ×100G 配置承载 400G。其文档未解释如何实现 800 Gbps 端口配置,可能涉及非标准配置,如聚合两条 400G FR4 链路,或可能正在开发支持 DR 链路(直接传输,无 WDM,每根光纤承载 100G)的新版本 CPO 交换机。
从每个 CPO 封装的光纤对数量来看,英伟达 Quantum-X 似乎不支持 WDM,这与 200G 端口数量一致。
功率效率与散热
共封装光学的主要动机之一是提升功率效率。博通和英伟达均报告称,与传统可插拔收发器相比,单位比特功耗显著降低。
博通声称其共封装光学每个 800 Gb/s 端口功耗约 5.5W,而等效可插拔模块约为 15W。这 3 倍的降幅意味着满载的 64 端口(每个 800G)交换机可节省数百瓦功率。5.5W 的功耗转化为光链路 6-7 pJ/bit 的功耗,这在 2024 年属于领先水平。
冷却此类系统比冷却包含数十个 15W 可插拔器件的等效交换机更容易。尽管如此,51.2T CPO 交换机的 ASIC 封装功率密度集中,仍会散发出大量热量,需要冷板液冷。不过,其单元很可能也可使用高性能风冷。
英伟达同样宣扬效率大幅提升:通过使用微环调制器和更少的激光器,其硅光子交换机的网络链路功率效率提升 3.5 倍。与博通类似,这些交换机需要液冷以有效散除 ASIC 封装的热量。事实上,GTC 大会上的 Quantum-X CPO 演示显示,交换机 ASIC 采用冷板液冷。
简而言之,两种方案均实现了更低的 pJ/bit 功耗,使超高带宽网络更具可持续性。
突破带宽墙 —— 未来方向
垂直耦合
传统光引擎常使用边缘耦合,将光纤对准芯片边缘的波导端面。带 V 型槽光纤阵列的边缘耦合是一种已知方法,可精确排列光纤(间距通常为 50-250 µm)并将其被动对准波导。
边缘耦合器可实现低插入损耗,且易于连接光纤带。然而,由于光纤必须并排布置且间距最小,它们会消耗大量边缘长度。
另一种方法是垂直耦合,使用片上衍射光栅耦合器或反射镜将光从芯片顶面耦合出去。这允许光 I/O 布置在芯片区域内,而不仅限于周边。垂直耦合器加上微透镜阵列可实现相当高的耦合密度,并可在光子裸片上方的任意位置灵活布置。其权衡通常是在扩展至多根光纤时损耗更高且对准更复杂。
尽管边缘耦合目前占主导地位(因其成熟度和效率),但垂直耦合正在研究实验室和部分公司中积极探索,以克服边缘长度限制。
多芯光纤与光纤间距缩小
若每根光纤可承载多个纤芯(光路),则对于给定的通道数,边缘的光纤数量可减少。多芯光纤(MCF)在单个光纤包层内封装多个独立纤芯,通过在单个光纤横截面内堆叠通道,高效利用有限的前沿面积。例如,4 芯光纤可使每根光纤的通道数增至 4 倍,立即将边缘通道密度提升 4 倍。尽管尚未在商用 CPO 产品中标准化,但它被视为解决光子前沿受限问题的 “有吸引力的方案”。
MCF 的缺点在于,若系统需要连接至不同服务器 / NIC 的更多低带宽端口基数,在单根光纤内聚合更多带宽并非良策。
另一种增加光纤密度的方法是缩小间距。标准单模光纤带间距约为 250 µm,通过使用更细光纤或去除缓冲层,可实现 50 µm 甚至更小的间距。IBM 已在可靠组装中演示了 50 µm 光纤通道间距,实验室中使用定制聚合物光纤甚至实现了 18 µm 间距。如此小的间距可大幅增加 “每毫米光纤数”,使 ASIC 封装能够输出更大带宽。
先进耦合器、透镜与连接方法
随着光纤间距缩小和数量增加,对准容差成为挑战。正在开发光栅耦合器与微透镜阵列等技术,以缓解对准限制,这可能实现光子芯片上方非常密集的 3D 堆叠光纤连接器阵列。
光纤连接方法也在演进。如今许多 CPO 实现仍依赖光纤阵列的精确放置,然后用环氧树脂固定。展望未来,预计会看到更多连接器化解决方案,如英伟达的可拆卸模块或初创公司提供的 “即插即用” 光插座小芯片。
WDM 是当前实现每根光纤更多通道的方法,垂直耦合、多芯光纤、密集光纤和新型连接技术正在兴起,以进一步提升前沿密度。每种技术解决不同方面的问题(几何密度 vs. 每光纤容量 vs. 对准)。下一代 CPO 实现正在探索结合多种方法,以在给定边缘长度内提升总封装外带宽。
CPO 部署挑战
主要挑战并非核心技术本身,更多在于 CPO 对现有生态系统和运营模式的影响:
生态系统颠覆:CPO 从根本上改变了供应链。客户不再从多家厂商购买可互换的可插拔模块,而是必须从单一系统厂商或紧密合作的伙伴处采购集成的 CPO 交换机或服务器。这降低了采购灵活性,增加了厂商锁定。
运营复杂性:现场更换和故障管理变得更加复杂。光引擎故障可能需要更换整个 CPO 交换机线卡或服务器主板,而非仅更换可插拔模块。大规模开发适用于 CPO 系统的稳健测试、诊断和修复策略是一项重大任务。
可靠性验证:尽管 CPO 通过消除可插拔连接器接口(常见故障点)有望提供更高可靠性,但这需要通过大规模长期部署来证明。CPO 可靠性数据已开始出现,但仍需更多验证。
成本:目前,CPO 与高容量可插拔光学器件相比无显著成本优势。随着产量上升,这种情况有望改变。
热管理:在 ASIC 封装内集成对热敏感的光组件带来显著热管理挑战,液冷成为必需。
鉴于这些挑战以及 1.6T 可插拔光学器件的快速成熟,在 200G / 通道代际,CPO 不太可能在横向扩展应用中实现大规模部署。
但行业预计将看到越来越大的 CPO 测试部署,以验证技术和运营模式,可能为下一代大规模部署铺平道路。
CPO 用于纵向扩展?
CPO 在纵向扩展用例(机架内连接)中的前景似乎更为光明。在此场景中,整个机架解决方案(包括加速器、交换机和互连)更可能从单一厂商(如英伟达)或紧密集成的合作伙伴处采购。这简化了生态系统挑战,使 CPO 集成更为直接。
在 2025 年 GTC 大会上,黄仁勋推出了 NVL144(基于 Rubin GPU),该产品在 200 Gbps 通道速率下继续使用铜缆进行 NVLink 互连。在这些速率下,铜缆可能体积庞大,电缆管理可能混乱。
光背板 / 中板链路在电缆和传输距离方面提供了巨大改进。单根带状光纤可承载多个波长,取代数十根铜缆,这大大减轻了重量和拥塞,这不仅对散热重要,对信号完整性也至关重要。光学器件还允许机箱尺寸扩展,并创建跨多个机架的超大规模纵向扩展集群,而无需将所有组件限制在数米范围内。
配备用于 NVLink 互连的 CPO 的 GPU 和纵向扩展交换机(如 NVSwitch)支持这些光背板。欲了解更多信息,可参考我关于宽总线光子背板及光背板其他趋势的帖子。
然而,无源铜缆在功率方面仍具优势,只要英伟达能在更低功耗下使其工作(即使必须在中间添加重定时器),就会继续在纵向扩展系统中使用铜缆。
纵向扩展系统中 GPU(或其他加速器)的合理选择可能是先过渡到 CPC(共封装铜缆),这将消除 PCB 走线,完全依靠跨接铜缆实现背板连接,然后在链路速度达~400 Gbps 及以上时过渡到 CPO 和光互连。
对此你有何想法 / 观点?
下一步是什么?光子织物 / 中介层?
除边缘布置光引擎的传统 CPO 外,另一种方案是使用置于核心裸片下方的光子中介层或织物。可将其视为 3D 堆叠配置,其中激光器、波导和光交换 / 路由位于基础层,计算或存储小芯片可安装在其上方,这本质上为小芯片提供了光主板。
由于光子中介层可以很大(3-4 倍光罩尺寸),它可提供非常长的 “边缘”—— 一个用于光 I/O 的连续 2D 表面。因此,每毫米边缘的有效带宽可能远高于分散布置的多个独立光引擎所能实现的带宽。
过去几年,多家初创公司一直在积极探索这一领域,2025 年 OFC 展会上也有许多演示证明了其可行性。
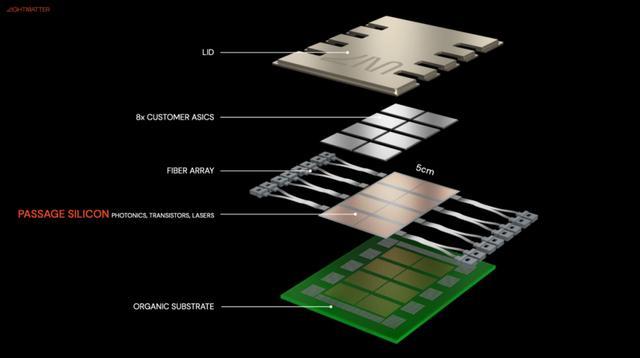
Photonic fabrics 或中介层示意图。引自 LightMatter
Photonic fabrics 的主要挑战在于基础层的光引擎会散发出大量热量,使这种 3D 堆叠配置中的热管理相当困难。尽管演示主要展示顶部的测试芯片(仅包含 Serdes 和最小逻辑),但在真实的 3D 光子织物芯片中,核心裸片和光基础层消耗大量功率,其热管理情况将十分有趣。
一些初创公司也在研究Photonic fabrics ,以连接封装内的多个 XPU。当封装内有多个核心时,Photonic fabrics 可在非相邻核心之间提供连接,延迟远低于通过有机基板路由的传统方法。
光子中介层另一示意图。引自 Celestial.ai
光互连的另一应用是将 XPU 连接至板上独立 ASIC 封装中容纳的内存池(HBM)。由于光纤延迟低,这可实现内存与 ASIC 的解耦。
然而,任何光连接的电光 - 光电转换都会消耗大量功率。若超大规模集成的替代方案涉及多个 ASIC 封装和 PCB 走线,光子织物方案可能成为更优解决方案。尽管如此,这些均属于长期发展。
当今的重点是交换机用 CPO,因为这是迫在眉睫的痛点,行业正为此兴奋不已。CPO 交换机的成功部署将在技术、供应链和对光学技术的信任方面为光子技术向其他领域扩展铺平道路!
未来令人兴奋……
(来源:新浪科技)

