MIT与Adobe联手开发AI视频生成工具,画质不输Sora,还能实时修改

(来源:MIT News)
如果有机会让你一窥人工智能模型生成视频的幕后过程,你会联想到什么?或许你以为这类似于定格动画的制作方式——先生成大量图像再拼接起来。但对于 OpenAI 的 SORA 和谷歌的 VEO 2 这类“扩散模型”而言,事实并非如此。
这些系统并非逐帧(或称“自回归”)生成视频,而是对整个序列进行同步处理。虽然最终生成的片段往往具有照片级真实感,但处理过程缓慢且无法实时修改。
近日,来自麻省理工学院计算机科学与人工智能实验室(CSAIL)和 Adobe Research 的科学家们开发出了一种名为“CausVid”的混合方法,该模型能够以每秒 9.4 帧的速度实时生成高质量视频,首帧延迟仅为 1.3 秒。
这个系统通过全序列扩散模型来训练自回归系统,使其既能快速预测下一帧画面,又能确保画质与连贯性。基于简单文本提示,CausVid 便可实现多种创作:将静态照片转化为动态场景、延长视频时长,甚至在生成过程中根据新指令实时修改内容。
该技术将原本需要 50 个步骤的流程精简为几个动作,实现了快速交互式内容创作。它能打造诸多充满想象力的艺术场景:纸飞机变成天鹅、长毛猛犸象穿越雪原、孩童在水坑中蹦跳。用户还能进行渐进式创作:先输入“生成男子过马路”的初始指令,待人物到达对面人行道时,再追加“他从口袋里掏出笔记本写字”的新元素。
CSAIL 的研究人员表示,该模型可以用于不同的视频编辑任务,例如通过生成与音频翻译同步的视频来帮助观众理解不同语言的直播;还可以帮助在视频游戏中渲染新内容,或快速生成训练模拟来教机器人完成新任务。
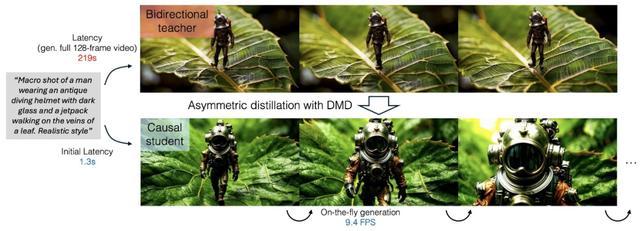
CausVid 可以被视为一种“师生模型”。其中,全序列扩散模型充当“老师”。其与驱动 SORA 或 VEO 的强大模型类似,擅长理解视频的整个时间流。它们可以同时预想一个序列的开头、中间和结尾,掌握运动的细微差别、物体的永久性以及场景整体随时间变化的稳定性。这种全面的理解使它们能够生成极其稳定且高分辨率的视频,但一次性处理整个序列需要耗费大量的计算资源,并且速度本身就很慢。
“学生”则是一个更简单的自回归模型。自回归模型根据序列中前一个元素预测下一个元素。在视频环境中,这意味着根据当前帧和前一帧预测下一帧。这种顺序处理本质上比试图一次性弄清楚所有内容要快得多。然而,纯自回归视频生成的尝试经常会失败,最大的陷阱是“错误累积”。想象一下,一个模型在预测每个后续帧时都会犯一些微小的错误。随着时间的推移,这些小错误会累积起来,导致视觉不一致、抖动,以及视频播放过程中质量明显下降。输出可能开始很流畅,但很快就会变得视觉混乱。
CausVid 巧妙地利用了教师模型的预见性,从而避免了这个问题。全序列扩散教师模型能够理解整个视频轨迹,并在训练阶段将其专业知识传授给自回归学生模型。它不仅仅是告诉学生“下一帧是什么样子”,而是训练学生模型理解稳定视频生成所需的底层动态和一致性。本质上,教师模型教会学生如何不仅快速地预测未来帧,而且能够始终如一地预测,并与对整个序列的高级理解保持一致。这与之前缺乏这种总体指导的因果方法有着至关重要的区别。通过对教师模型的高质量输出进行训练,并受益于其全局理解,学生模型可以学会快速预测后续帧,而不会像之前的模型那样陷入累积误差。
当研究人员测试 CausVid 生成 10 秒高清视频的能力时,这款模型展现出卓越的视频制作天赋。其表现远超“OpenSORA”和“MovieGen”等基线模型,生成速度比竞品快达 100 倍,同时能输出最稳定、最高质的视频片段。
团队进一步测试了 CausVid 生成 30秒长视频的稳定性,在画质连贯性方面同样碾压同类模型。这些结果表明,该技术有望实现数小时甚至无限时长的稳定视频生成。有趣的是,作为研究一部分进行的用户调研,为了解 CausVid 性能的实际体验提供了宝贵的见解。相比基于扩散技术的教师模型,用户绝大多数更喜欢学生模型生成的视频。
“自回归模型的速度优势具有决定性意义,”论文作者 Tianwei Yin 指出,“其视频质量可与教师模型媲美,虽然生成耗时更短,但代价是视觉多样性稍逊一筹。”
在使用文本-视频数据集进行的 900 多次提示测试中,CausVid 以 84.27 的综合评分拔得头筹。其在成像质量和拟人动作等指标上表现尤为突出,超越了“Vchitect”和“Gen-3”等顶尖视频生成模型。
尽管 CausVid 已是 AI 视频生成领域的高效突破,但通过精简因果架构,其生成速度有望进一步提升,甚至实现即时生成。Tianwei Yin 表示,若采用特定领域数据集训练,该模型将为机器人和游戏产业产出更优质的视频内容。
专家认为,这种混合系统是对当前受处理速度拖累的扩散模型的重要升级。“现有视频模型的速度远逊于大语言模型或图像生成模型,”未参与该研究的卡内基梅隆大学助理教授 Jun Yan Zhu 评价道,“这项突破性工作显著提升了生成效率,意味着更流畅的串流速度、更强的交互应用潜力,以及更低的碳足迹。”
该研究获得了亚马逊科学中心、光州科学技术院、Adobe、谷歌、美国空军研究实验室及美国空军人工智能加速器的支持。CausVid 技术将于 6 月在国际计算机视觉与模式识别会议(CVPR)正式亮相。
(来源:新浪科技)
