一个「always」站在大模型技术C位的传奇男子 | 量子位
一个「always」站在大模型技术C位的传奇男子

AI届传奇沙哥Noam Shazeer,为什么AI领域突破性论文频频署他名啊??
这是最近网友不断对着Transformer八子之一的Noam Shazeer(为方便阅读,我们称他为沙哥)发出的灵魂疑问。
尤其是最近Meta FAIR研究员朱泽园分享了他们《Physics of Language Models》项目的系列新进展后,有网友发现,其中提到的3-token因果卷积相关内容,沙哥等又早在三年前就有相关研究。
是的,“又”。
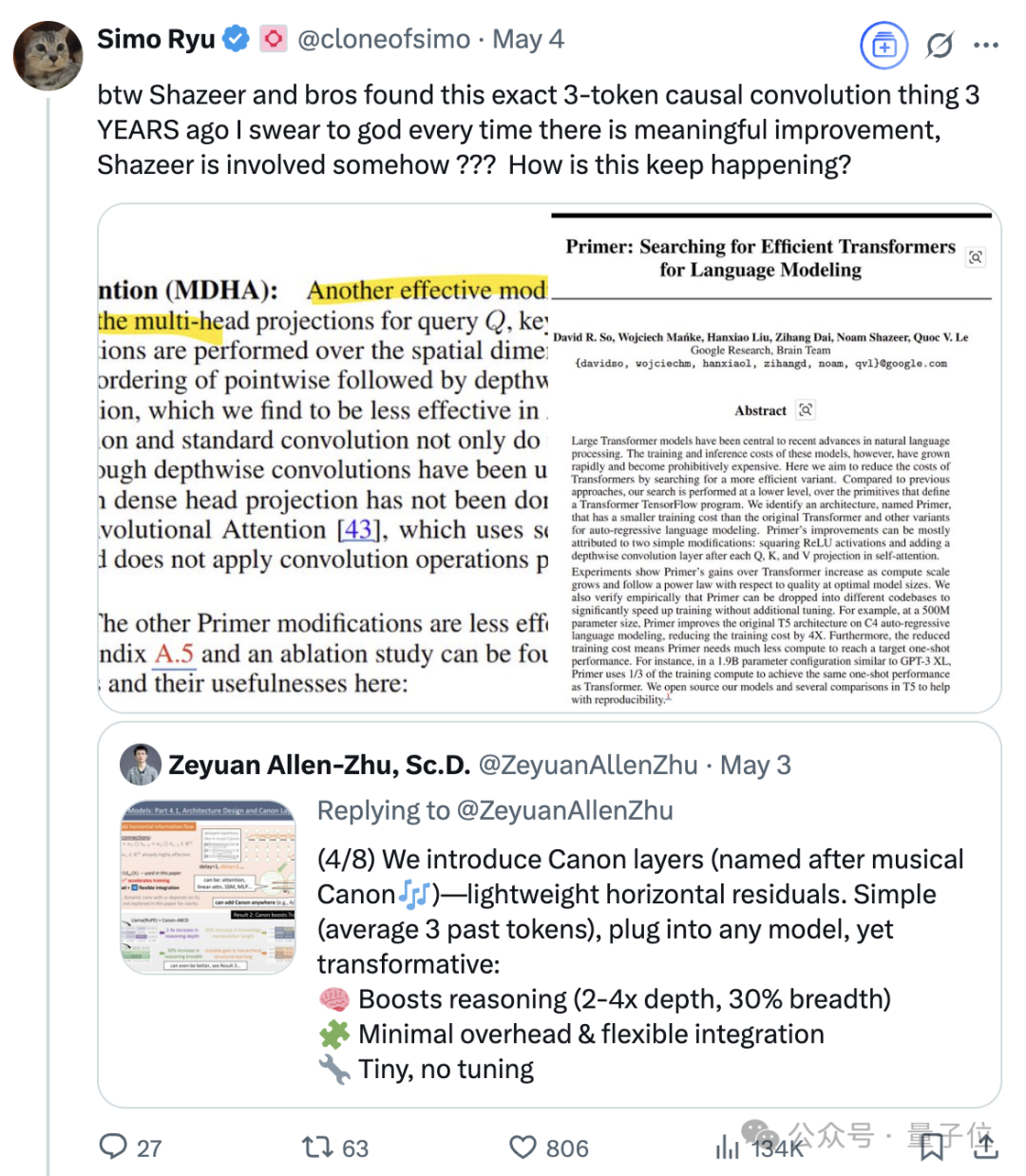
因为你只要梳理一遍他的工作履历,就不难发现,AI界大大小小的突破背后,总是能发现他的名字。
“不是搞个人崇拜,但为什么总是Noam Shazeer?”
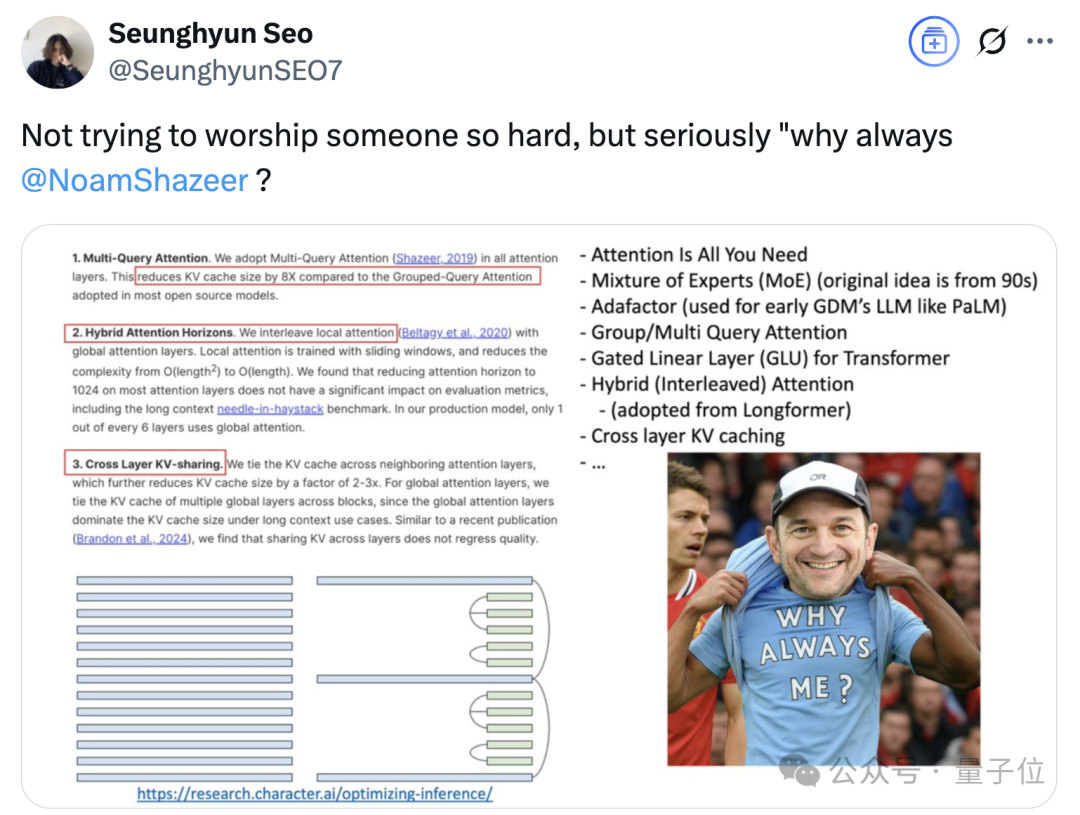
△网友称右下角沙哥图由GPT-4o生成
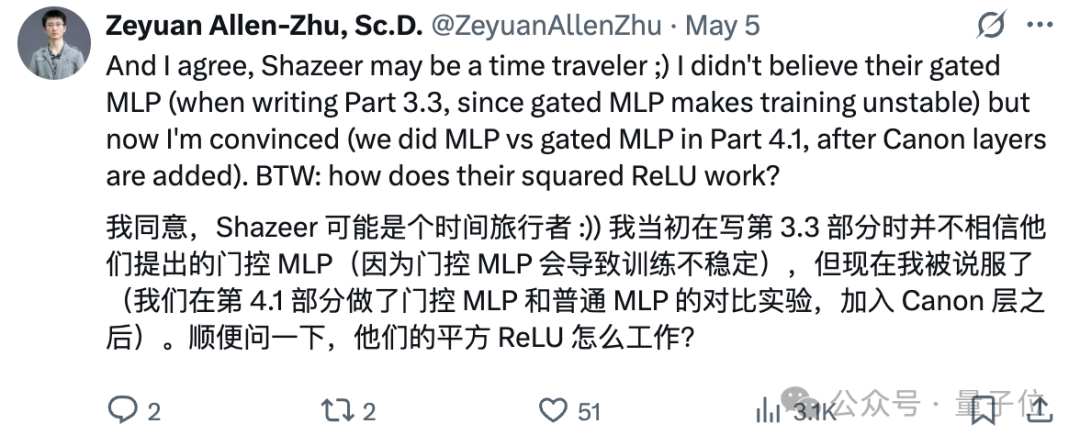
朱泽园也自己也站出来表示,沙哥成果超前:
正式认识一下,沙哥是谁?
他是Transformer八位作者中被公认是“贡献最大”的那位,也是半路跑去创业Character.AI,又被谷歌“买回来”那位。
他并非OpenAI的明星科学家,也不似DeepMind创始人般频繁曝光,但若细察当今LLM的核心技术,其奠基性贡献隐然贯穿始终。
从引用量超17万次的《Attention is all you need》,到将MoE引入LLM的谷歌早期研究,再到Adafactor算法、多查询注意力、用于Transformer的门控线性层(GLU)……

有人感慨,其实我们现在就是生活在“Noam Shazeer时代”。
因为如今主流模型架构的演变,就是在其奠定的基础上持续推进。

所以,他都做了什么?
Attention Is All You Need是其一
在AI领域,昙花一现的创新者众多,但能持续定义技术范式者凤毛麟角。
沙哥恰恰属于后者,他的工作不仅奠定了当今大语言模型的基础,还频频在技术瓶颈出现时提供关键突破。
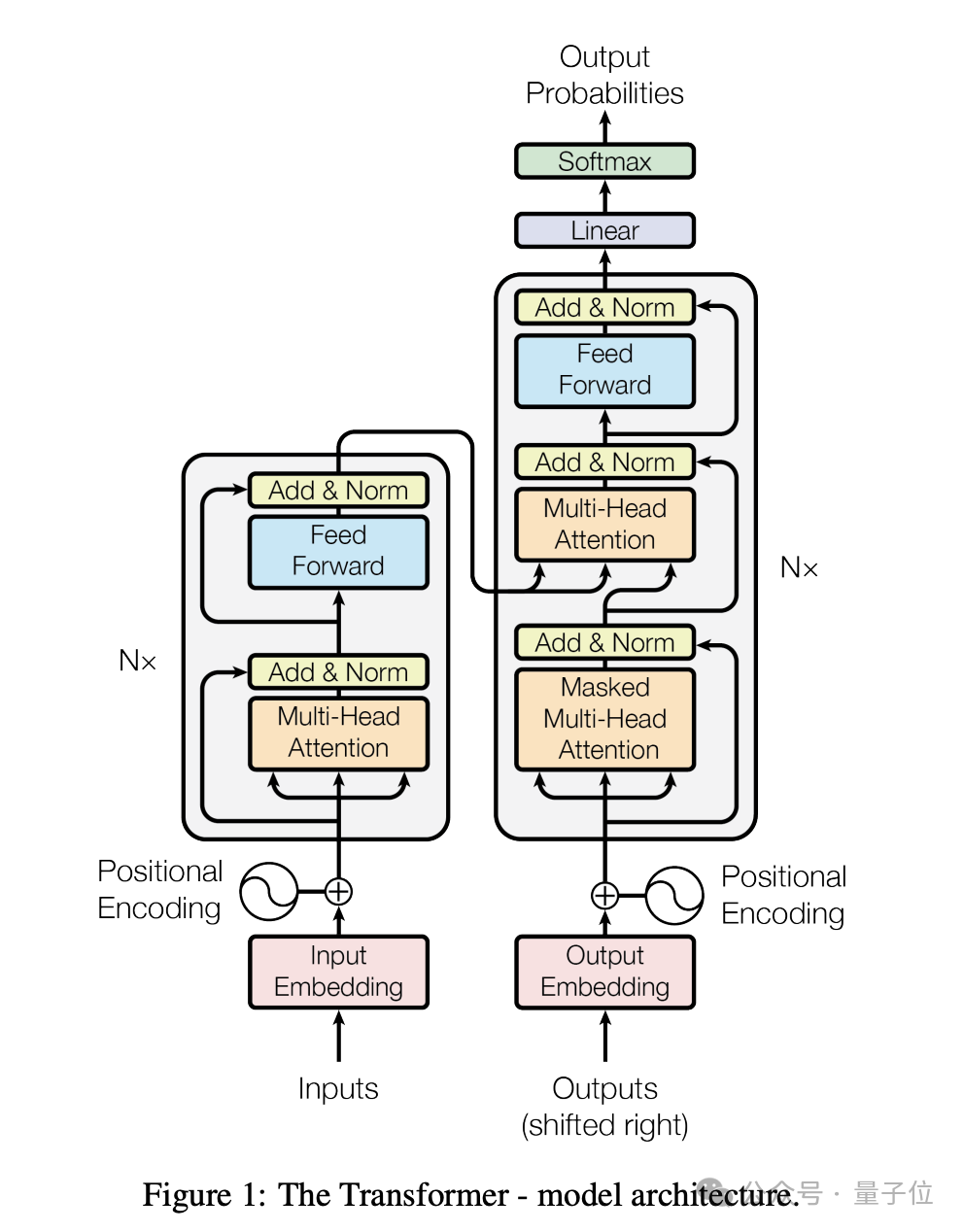
其影响力最大的一项工作当属2017年的《Attention Is All You Need》。
2017年的一天,已加入谷歌数年的沙哥在办公楼走廊里偶然听到Lukasz Kaiser、Niki Parmar、Ashish Vaswani等几人的对话。
他们正兴奋地谈论如何使用自注意力,沙哥当时就被吸引了,他觉得这是一群有趣的聪明人在做有前途的工作。
而后,沙哥被说服加入了这个已有七人的团队,成为第八位成员,也是最后一位。
但这个最后到场的人,却在短短几周内根据自己的想法,重新编写了整个项目代码,把系统提升到了新的水平,使得Transformer项目“拉开了冲刺的序幕”。
沙哥实力超群却不自知,当看到论文草稿中自己被列为第一作者时,他还有些惊讶。
在讨论一番后,八位作者最后决定打破学术界一作二作通讯作的规则,随机排序,并给每个人名字后都打上星号,脚注标明都是平等贡献者。
但大家都知道,沙哥加入发挥了举足轻重的作用。后来《Attention Is All You Need》这篇论文引起轰动。
而沙哥的恐怖之处,在于他似乎总能比行业提前数年看到技术趋势,不只是Transformer。
在《Attention Is All You Need》前后,沙哥还作为一作同三巨头之一、图灵奖得主Geoffrey Hinton以及谷歌元老级人物、第20号员工Jeff Dean等合作发表了另一篇具有代表性的工作——
《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》。
早在那时就为现今大火的新范式Mixture of Experts(MoE)埋下了伏笔。

这项工作创造性地引入了Sparsely-Gated Mixture-of-Experts,将MoE应用于语言建模和机器翻译任务,提出了一种新架构,具有1370亿参数的MoE被以卷积方式应用于堆叠的LSTM层之间。
规模放在今天也是超大杯的存在。
虽然MoE的思路早在上世纪90年代初就已经被提出,以Michael I. Jordan、Geoffrey Hinton等的《Adaptive Mixtures of Local Experts》为代表,但沙哥参与的这项研究通过动态激活子网络,让模型突破更大规模参数成为可能,启发了后续诸多基于MoE的模型改进和创新。
且沙哥对MoE的探索远不止于此。
2020年,谷歌《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》中提出GShard。
它提供了一种优雅的方式,只需对现有模型代码做很小改动,就能表达各种并行计算模式。
GShard通过自动分片技术,将带有Sparsely-Gated Mixture-of-Experts的多语言神经机器翻译Transformer模型扩展到超6000亿参数规模。

次年,Switch Transformers这项工作,结合专家并行、模型并行和数据并行,简化MoE路由算法,提出大型Switch Transformer模型,参数达到1.6万亿。
不仅推进了语言模型的规模,还在当时实现了比T5-XXL模型快4倍的速度。

模型规模的扩大一方面为自然语言处理开辟了新的领域,另一方面也面临训练过程中的不稳定性以及微调阶段质量不确定性的阻碍。
2022年,针对该问题的研究《ST-MoE: Designing Stable and Transferable Sparse Expert Models》问世了。
该项目将一个ST-MoE-32B稀疏模型的参数规模扩展到了2690亿,其计算成本与一个拥有320亿参数的密集型encoder-decoder Transformer模型差不多。

这林林总总一系列关键性进展的作者名单中,总少不了沙哥。
时间证明沙哥的预判是对的。
如今,GPT-4 、DeepSeek系列、阿里Qwen3系列……主流将MoE与Transformer架构的结合,无一不是在此系列工作的思想上发展而来。
说沙哥踩在时代的命门上,不光靠这些。
为解决大规模模型的训练内存受限的问题,沙哥还曾联合提出了Adafactor优化器,早期谷歌大模型如PaLM都离不开它。

作用于大模型推理加速的Multi Query Attention(MQA)也是出自他的手笔。
MQA最早于2019年沙哥的独作论文《Fast Transformer Decoding: One Write-Head is All You Need》中被提出,旨在解决Transformer增量推理阶段效率低下的问题。

另外,他还提出了被广泛应用于各种Transformer模型中的Gated Linear Layer(GLU)。
GLU为Transformer架构带来了显著改进,通过门控机制,GLU可以根据输入动态地调整信息的传递,从而更好地捕捉数据中的复杂模式和依赖关系,提升模型的表达能力。
这种动态调整能力更有助于模型处理长序列数据,有效利用上下文信息。

用网友的话来说,沙哥参与的研究往往都是简单粗暴,详细介绍了技术细节,当时可能大家不能完全理解其中的奥妙,但之后就会发现很好用。
3岁自学算术,1994年IMO满分
沙哥的技术嗅觉,源自其近乎传奇的成长轨迹。
1974年,沙哥出生于美国,3岁就开始自学算术。
1994年,他参加了IMO(国际数学奥林匹克竞赛),在经历长达九小时的考试后,取得了满分,这是该项赛事35年历史上首次有学生拿到满分(同年还有另外5名学生拿到满分)。
同年,沙哥(来源:量子位)
