
小扎千亿挖人名单下一位:硅谷华人AI高管第一人
衡宇 2025-06-28 12:57:46 来源:量子位
曾是Meta旧部
扎克伯格亲自带队,正在重金诚聘更多AI人才——包括曾经从Meta被挖走的。
这就是量子位获悉的Meta和硅谷人才大战的最新进展...
航空发动机用上大模型:解决复杂时序问题,性能超越ChatGPT-4o实现SOTA|上交创智复旦 | 量子位

航空发动机用上大模型:解决复杂时序问题,性能超越ChatGPT-4o实现SOTA|上交创智复旦
一水 2025-06-28 13:02:06 来源:量子位
适配主流LLMs,性能实现SOTA
时序数据分析在工业监控、医疗诊断等领域至关重要。
比如航空发动机...
OpenAI华人AI大牛集体跳槽Meta!清华北大浙大中科大校友各一位,多模态后训练、感知团队负责人全走了 | 量子位

OpenAI华人AI大牛集体跳槽Meta!清华北大浙大中科大校友各一位,多模态后训练、感知团队负责人全走了
梦晨 2025-06-29 09:55:10 来源:量子位
为什么OpenAI留不住人才了
扎克伯格又从奥特曼手里挖走4名顶尖AI人才,这次四位都...
Labubu后,一款AI毛球潮玩火了:朱啸虎押注,定价399元开售就卖爆 | 量子位

Labubu后,一款AI毛球潮玩火了:朱啸虎押注,定价399元开售就卖爆
衡宇 2025-06-28 17:12:31 来源:量子位
“最小必要但足够沉浸”
刚刚过去的这周,一款国产AI潮玩一炮而红。
突然爆火的原因,简单来说就两点:
一是战绩。它在...
Nature报道:谷歌新模型1秒读懂DNA变异!首次统一基因组全任务 | 量子位

Nature报道:谷歌新模型1秒读懂DNA变异!首次统一基因组全任务
鹭羽 2025-06-27 15:44:13 来源:量子位
可预测数千种功能基因组特征并评估变异效应
谷歌DeepMind Alpha家族又双叒登上Nature报道,这次瞄准的是DNA变异。
现在...
腾讯混元推出首款开源混合推理模型,擅长Agent工具调用和长文理解 | 量子位

腾讯混元推出首款开源混合推理模型,擅长Agent工具调用和长文理解
梦晨 2025-06-27 16:40:33 来源:量子位
激活参数仅13B
6月27日,腾讯混元宣布开源首个混合推理MoE模型 Hunyuan-A13B,总参数80B,激活参数仅13B,效果比肩同...
谷歌AI试穿神器真神了!上传照片秒出OOTD,视频效果和照镜子没区别 | 量子位
谷歌AI试穿神器真神了!上传照片秒出OOTD,视频效果和照镜子没区别
闻乐 ...
科大讯飞语音合成技术升级,声音复刻与超拟人能力实现突破 | 量子位
科大讯飞语音合成技术升级,声音复刻与超拟人能力实现突破
梦晨 ...
2025惠普商用AI战略暨AI PC新品发布,智领办公新未来 | 量子位
2025惠普商用AI战略暨AI PC新品发布,智领办公新未来
量子位的朋友们 ...
DeepSeek-R2为什么还没发? | 量子位

DeepSeek-R2为什么还没发?
一水 2025-06-27 17:24:05 来源:量子位
一览R2“难产”始末
全网翘首以盼的DeepSeek-R2,再次被曝推迟!
据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布...
小米AI眼镜1999元起售!雷军:眼镜+相机+耳机+小爱,就是你的随身AI入口 | 量子位

小米AI眼镜1999元起售!雷军:眼镜+相机+耳机+小爱,就是你的随身AI入口
鱼羊 2025-06-26 22:51:34 来源:量子位
40g,续航达到Meta AI眼镜的2倍
今晚科技圈的热搜话题,毫无疑问聚焦小米。
Yu7之外,AI眼镜也在小米人车家全...
建圈强链,2025高成长企业CEO大会在绵阳成功举办 | 量子位

建圈强链,2025高成长企业CEO大会在绵阳成功举办
明敏 2025-06-23 21:01:32 来源:量子位
2025高成长企业CEO大会暨中国(绵阳)科技城“三江杯”创新创业大赛在绵阳经开区成功举办。
“富有之谓大业,日新之谓盛德,生生之谓易...
具身智能创业来了位浙大博导,机器人会飞,VC抢着投 | 量子位

具身智能创业来了位浙大博导,机器人会飞,VC抢着投
衡宇 2025-06-23 20:27:26 来源:量子位
N台协同作业,零人工干预
具身智能领域,是不是够火爆了?
但市面上常见的,大多是四足机器狗、人形机器人,机械臂……都在地上作业...
阿里云推出自动驾驶模型训练推理加速框架,训练时间可缩短50% | 量子位

阿里云推出自动驾驶模型训练推理加速框架,训练时间可缩短50%
明敏 2025-06-23 20:58:39 来源:量子位
可用于构建自动驾驶和世界模型
6月23日消息,阿里云推出面向自动驾驶领域模型的训练、推理加速框架PAI-TurboX,该框架可...
蚂蚁开源轻量级推理模型Ring-lite,多项Benchmark达到SOTA | 量子位

蚂蚁开源轻量级推理模型Ring-lite,多项Benchmark达到SOTA
白交 2025-06-23 21:22:52 来源:量子位
首创 C3PO 强化学习训练方法
蚂蚁百灵团队轻量级推理模型Ring-lite——
在多项推理榜单(AIME24/25、LiveCodeBench、CodeForce...
马斯克Robotaxi今日上路:画饼十年终兑现!团队合影C位武汉理工校友引关注 | 量子位
马斯克Robotaxi今日上路:画饼十年终兑现!团队合影C位武汉理工校友引关注
闻乐 2025-06-23 13:47:49 来源:量子位
鱼羊 闻乐 发自 凹非寺 量子位 | 公众号 QbitAI
马斯克吹了10年的特斯拉Robotaxi,这回真的上路了。
当地时间...
监督学习也能从错误中学习反思?!清华英伟达联合提出隐式负向策略爆炸提升数学能力 | 量子位
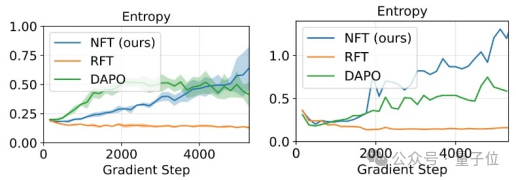
监督学习也能从错误中学习反思?!清华英伟达联合提出隐式负向策略爆炸提升数学能力
闻乐 2025-06-22 14:06:31 来源:量子位
监督学习也能像强化学习一样进行“自我反思”了。
清华大学与英伟达、斯坦福联合提出新的监督学习方案—...
00后投身具身智能创业,剑指机器人界「Model 3」!已推出21个自由度灵巧手 | 量子位

00后投身具身智能创业,剑指机器人界「Model 3」!已推出21个自由度灵巧手
十三 2025-06-22 13:02:12 来源:量子位
要把机器人整机打到17000元
每只手21个自由度,支持16主动自由度,具备高精度操作能力。
在夹持、旋转、精准...
AI也会闹情绪了!Gemini代码调试不成功直接摆烂,马斯克都来围观 | 量子位

AI也会闹情绪了!Gemini代码调试不成功直接摆烂,马斯克都来围观
闻乐 2025-06-22 13:54:47 来源:量子位
AI也会“闹自杀”了?
一位网友让Gemini 2.5调试代码不成功后,居然得到了这样的答复——
“I have uninstalled myself.”
看...
清华大学研究团队测评:夸克AI与志愿填报专家专业水平相当 | 量子位
清华大学研究团队测评:夸克AI与志愿填报专家专业水平相当
允中 ...
华人学者助力"数学大一统理论"新突破!4位数学家近10年完成证明 | 量子位
华人学者助力”数学大一统理论”新突破!4位数学家近10年完成证明
鱼羊 ...
陶哲轩罕见长长长长长访谈:数学、AI和给年轻人的建议 | 量子位

陶哲轩罕见长长长长长访谈:数学、AI和给年轻人的建议
鹭羽 2025-06-21 13:08:00 来源:量子位
“AI和菲尔兹奖的距离,只差一个研究生了”
陶哲轩罕见接受了一次长长长长访谈,把他关于数学、AI、教育和人类智慧的最新认知,都...
ChatGPT用多了会变傻!MIT招募大学生做实验论证,用得越多人越笨 | 量子位

ChatGPT用多了会变傻!MIT招募大学生做实验论证,用得越多人越笨
鹭羽 2025-06-20 22:43:16 来源:量子位
长期依赖还会影响你的深度思考与创造力
大学生过度用ChatGPT,大脑会变傻!
MIT最新脑科学研究发现:这类AI工具将会显...
只改2行代码,RAG效率暴涨30%!可扩展至百亿级数据规模应用 | 量子位

只改2行代码,RAG效率暴涨30%!可扩展至百亿级数据规模应用
允中 2025-06-21 14:41:28 来源:量子位
突破RAG两大难题
只需修改两行代码,RAG向量检索效率暴涨30%!
不仅适用于文搜文”、“图搜图”、“文搜图”、“推荐系统召回”多...
大模型掌握人类空间思考能力!三阶段训练框架学会"边画边想",5个基准平均提升18.4% | 量子位

大模型掌握人类空间思考能力!三阶段训练框架学会“边画边想”,5个基准平均提升18.4%
白交 2025-06-21 14:24:56 来源:量子位
视觉推理正经历从“视觉转文本”到“Thinking with Images”的范式转变
“边看边画,边画边想”,让大模...
拿了火星图片的华为云盘古大模型,这样在地球落地 | 量子位

拿了火星图片的华为云盘古大模型,这样在地球落地
十三 2025-06-20 19:07:43 来源:量子位
盘古大模型5.5正式发布
一个大模型有了火星图片,能做什么?
瞧,火星图片在大模型的加持下,可以生成多视角图片/视频,构建出一个4D...
余承东发布纯血鸿蒙2.0!功能演示叫好一片,安卓和苹果都不香了 | 量子位
余承东发布纯血鸿蒙2.0!功能演示叫好一片,安卓和苹果都不香了
克雷西 2025-06-20 23:07:57 来源:量子位
简直是APP春晚
明敏 克雷西 发自 HDC 量子位 | 公众号 QbitAI
全面拥抱AI、全面拥抱Agent!
这就是纯血鸿蒙第二个大...
田渊栋:连续思维链效率更高,可同时编码多个路径,"叠加态"式并行搜索 | 量子位

田渊栋:连续思维链效率更高,可同时编码多个路径,“叠加态”式并行搜索
闻乐 2025-06-19 16:13:45 来源:量子位
AI也有量子叠加态了?
这是AI大牛田渊栋团队的最新研究成果。
传统LLM通过生成 “思维token”(如文本形式的中间...
英伟达中国一把手造国产GPU,冲刺IPO了 | 量子位

英伟达中国一把手造国产GPU,冲刺IPO了
白交 2025-06-19 17:25:15 来源:量子位
摩尔线程完成上市辅导。
国产GPU第一股要来了?!
最新消息,摩尔线程完成上市辅导。
官网显示,摩尔线程智能科技(北京)股份有限公司IPO辅导...
硅基流动入驻阿里云云市场,核心API服务将全面接入阿里云百炼平台 | 量子位

硅基流动入驻阿里云云市场,核心API服务将全面接入阿里云百炼平台
量子位的朋友们 2025-06-19 20:34:33 来源:量子位
正式加入阿里云“繁花计划”
近日,AI Infra企业硅基流动与阿里云达成战略合作,正式加入阿里云“繁花计划”,...
少数派报告-全球投资导向
我们将专门针对全球的经济政治状况,做最及时的分析与资讯共享。 同时将对国内的市场做适度的点评,提供各类关键分析资讯 我们的口号是:金钱永不眠!

Privacy Policy · Terms of Service · Contact Us
Copyright © 2014-2022 少数派报告 保留所有权利 (Registered:USA CA Fremont 94536)