
CVPR 2025:单图秒变专业影棚,几何/材质/光影全搞定,数据代码开源
白交 2025-04-02 16:40:40 来源:量子位
香港中文大学、上海人工智能实验室及南洋理工大学的研究团队联合研发
如何从一张普通的单幅图像准确估计物体的三维...
论文读得慢,可能是工具的锅,一手实测科研专用版「DeepSeek」

「未来,99% 的 attention 将是大模型 attention,而不是人类 attention。」这是 AI 大牛 Andrej Karpathy 前段时间的一个预言。这里的「attention」可以理解为对内容的需求、处理和分析。也就是说,他预测未来绝大多数资料的处理工作将由大模型来完成,而不是人类。
身为经常接触大量文档和文案的开发者、研究者,相信...
反向传播、前向传播都不要,这种无梯度学习方法是Hinton想要的吗?

「我们应该抛弃反向传播并重新开始。」早在几年前,使反向传播成为深度学习核心技术之一的 Geoffrey Hinton 就发表过这样一个观点。
而一直对反向传播持怀疑态度的也是 Hinton。因为这种方法既不符合生物学机理,与大规模模型的并行性也不兼容。所以,Hinton 等人一直在寻找替代反向传播的新方法,比如 2022 年的前向 ...
MoCha:开启自动化多轮对话电影生成新时代

本文由加拿大滑铁卢大学魏聪、陈文虎教授团队与 Meta GenAI 共同完成。第一作者魏聪为加拿大滑铁卢大学计算机科学系二年级博士生,导师为陈文虎教授,陈文虎教授为通讯作者。
近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创...
铰链物体的通用世界模型,超越扩散方法,入选CVPR 2025

基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。尽管现在基于 diffusion 的方法取得了很多进展,但是这些方法存在处理效率低,同时缺乏三维感知等问题,难以投入真实环境中使用。
清华大学联合北京大学提出了第一个基于重建模型的 part-level 运动的建模——...
Meta Llama 4被疑考试「作弊」:在竞技场刷高分,但实战中频频翻车

Meta 翻车来得猝不及防。
上周六,Meta 发布了最新 AI 模型系列 ——Llama 4,并一口气出了三个款,分别是 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。
据官方介绍,在大模型竞技场中,它们的排名相当不赖。
就拿 Llama 4 Maverick 来说,总排名第二,成为第四个突破 1400 分的大模型。其中开放模...
ILLUME+:华为诺亚探索新GPT-4o架构,理解生成一体模型,昇腾可训!

近年来,基于大语言模型(LLM)的多模态任务处理能力取得了显著进展,特别是在将视觉信息融入语言模型方面。像 QwenVL 和 InternVL 这样的模型已经展示了在视觉理解方面的卓越表现,而以扩散模型为代表的文本到图像生成技术也不断突破,推动了统一多模态大语言模型(MLLM)的发展。这些技术的进步使得视觉理解和生成能力...
DataCanvas Alaya NeW智算操作系统首批首家通过中国信通院“大模型推理平台”标准评估

近日,九章云极DataCanvas公司自主研发的DataCanvas Alaya NeW智算操作系统顺利通过中国信息通信研究院(以下简称“中国信通院”)首批首家“大模型推理平台技术要求”标准技术评估。这是继今年1月首批首家通过中国信通院“大模型计算资源调度平台”标准评测后,DataCanvas Alaya NeW智算...
新SOTA,AI增强医学蛋白质组数据分析,扩散模型驱动的从头肽测序
编辑 | 萝卜皮
随着人工智能工具的广泛应用,大多数技术和自然科学领域都在迅速发展。生物技术领域尤其如此,人工智能模型为药物研发、精准医疗、基因编辑、食品安全以及许多其他研究领域带来了重大突破。
其中一个分支领域是蛋白质组学,即大规模研究蛋白质的学科,该学科将大量蛋白质数据收集到数据库中,以便与样本...
大模型RL不止数学代码!7B奖励模型搞定医学法律经济全学科, 不用思维链也能做题 | 量子位

大模型RL不止数学代码!7B奖励模型搞定医学法律经济全学科, 不用思维链也能做题
梦晨 2025-04-02 17:08:50 来源:量子位
将强化学习训练扩展到医学、化学、法律、心理学、经济学等多学科
一个7B奖励模型搞定全学科,大模型强...
Meta深夜开源Llama 4!首次采用MoE,惊人千万token上下文,竞技场超越DeepSeek

万万没想到。Meta 选择在周六日,发布了最新 AI 模型系列 ——Llama 4,这是其 Llama 家族的最新成员。
该系列包括 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。所有这些模型都经过了大量未标注的文本、图像和视频数据的训练,以使它们具备广泛的视觉理解能力。
Meta GenAI 负责人 Ahmad Al-Dahle...
从0到1玩转MCP:AI的「万能插头」,代码手把手教你!

在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。
2024 年 11 月,Anthropic 推出了开源协议 MCP(Model Context Protocol,模型上下文协议),旨在为 AI 模型与外部数据源和工具之间的交互提供一个通用、...
CVPR满分论文 | 英伟达开源双目深度估计大模型FoundationStereo

本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。通过构建大规模(100 万立体图像对)合成训练数据集,结合自动自筛选流程去除模糊样本,并设计了网络架构组件(如侧调谐特征主干和远程上下文推理)来增强可扩展性和准确性。这些创新显著提升了模型在不同领域的鲁棒性和...
大语言模型变身软体机器人设计「自然选择器」,GPT、Gemini、Grok争做最佳

大型语言模型 (LLM) 在软体机器人设计领域展现出了令人振奋的应用潜力。密歇根大学安娜堡分校的研究团队开发了一个名为「RoboCrafter-QA」的基准测试,用于评估 LLM 在软体机器人设计中的表现,探索了这些模型能否担任机器人设计的「自然选择器」角色。
这项研究为 AI 辅助软体机器人设计开辟了崭新道路,有望实现更自...
全网都在猜,这些视频是不是字节AI生成的:该跟动捕说再见了?

在 GPT-4o 的风到处吹时,X 平台(原推特)上有好多带视频的帖子爆了。到底是什么引来了一百万的浏览量?
没错,是玛丽莲・梦露「活了过来」。她不仅能够语音 — 口型保持一致,动作也能复刻参考示例。在大幅度的手臂摆动时,也不会出现严重的变形或虚影。
网友瞳孔震惊,「别告诉我,这些都是 AI 生成的......」
...
CVPR 2025 Oral | 多模态交互新基准OpenING,新版GPT-4o杀疯了?

文生图 or 图生文?不必纠结了!
人类大脑天然具备同时理解和创造视觉与语言信息的能力。一个通用的多模态大语言模型(MLLM)理应复刻人类的理解和生成能力,即能够自如地同时处理与生成各种模态内容,实现多模态交互,这也是向通用人工智能(AGI)迈进的关键挑战之一。最近爆火的新版 GPT4o 与 Gemini-2.0 在图文交互...
7B扩散LLM,居然能跟671B的DeepSeek V3掰手腕,扩散vs自回归,谁才是未来?

语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
但最近,这种印象正被打破。更多的研究者开始探索在图像生成中引入自回归(如 GPT-4o),在语言生成中引入扩散。
香港大学和华为诺亚方舟实验室的一项研究就是其...
微软诞生50周年,比尔・盖茨撰文忆往昔,并发布了Altair BASIC源代码

1975 年 4 月 4 日,比尔・盖茨和保罗・艾伦在美国新墨西哥州阿尔伯克基市创立了微软公司。到今天,半个世纪过去了,微软早已成长为一家超级科技巨头。
近日,比尔・盖茨亲自撰文回忆了微软的诞生和他们的第一笔业务,同时还通过一份 157 页的 PDF 文件分享了他们为这项业务编写的 Altair BASIC 源代码。
顺带一提,比尔...
三思而后行,让大模型推理更强的秘密是「THINK TWICE」?

近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。OpenAI 的 o1 系列与 DeepSeek 的 R1 模型已展示出显著的推理能力提升。然而,在实现高性能的同时,复杂的训练策略、冗长的提示工程和对外部评分系统的依赖仍是现实挑战。
...
CVPR 2025 | GaussianCity: 60倍加速,让3D城市瞬间生成

想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。
然而,现实却远非如此。现有的 3D 城市生成方法,如基于 NeRF 的 CityDreamer [1],虽然能够生成逼真的城市场景,但渲染速度较慢,难以满足游戏、虚拟现实和自动驾驶模拟对实时性...
GPT-4o骗了所有人,逐行画图只是前端特效?!底层架构细节成迷,奥特曼呼吁大家别玩了 | 量子位

GPT-4o骗了所有人,逐行画图只是前端特效?!底层架构细节成迷,奥特曼呼吁大家别玩了
梦晨 2025-03-31 11:54:41 来源:量子位
OpenAI团队为此一直在熬夜
GPT-4o玩家太疯狂,奥特曼紧急呼吁别再生成图片了:OpenAI团队为此一...
周光:VLA模型将成智能驾驶体验颠覆性拐点 | 量子位
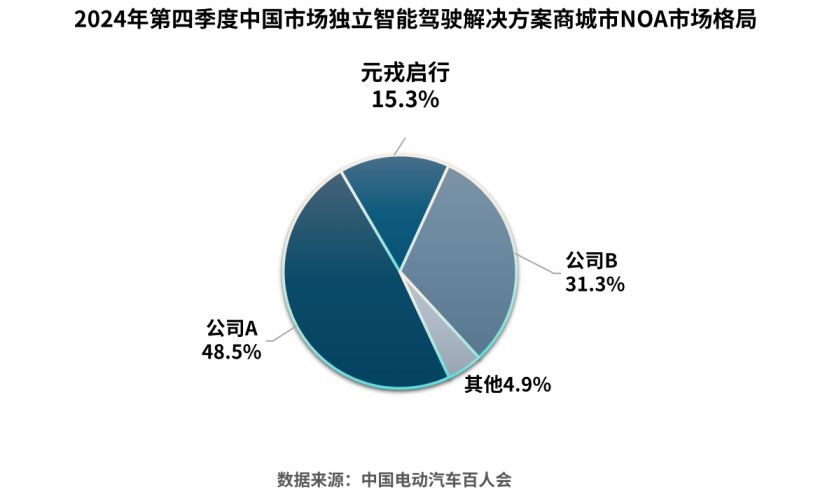
周光:VLA模型将成智能驾驶体验颠覆性拐点
西风 2025-03-31 18:36:19 来源:量子位
颠覆性体验,正在到来。
3月30日,在百人会智能汽车创新技术与产业论坛上,元戎启行CEO周光表示已完成VLA模型的道路测试,并将基于VLA模型打...
摸DeepSeek过河也得自身硬! 想开后的文小言,真香! | 量子位

摸DeepSeek过河也得自身硬! 想开后的文小言,真香!
西风 2025-03-31 16:31:49 来源:量子位
多模型融合玩出新花样
刚刚,百度文小言全面升级了。
基于多模型的能力,文小言升级了包括全新大语音模型、图片问答等在内的一系列...
具身前沿,智领未来!第二届中国具身智能大会成功举办 | 量子位

具身前沿,智领未来!第二届中国具身智能大会成功举办
量子位的朋友们 2025-03-30 16:30:46 来源:量子位
擘画具身智能发展新蓝图
在人工智能技术持续突破的浪潮中,具身智能正从单点突破迈向产业协同,开启生态化发展新阶段...
免费的「网页版Cursor」!新版DeepSeek-V3加持,秒秒钟编出APP | 量子位

免费的「网页版Cursor」!新版DeepSeek-V3加持,秒秒钟编出APP
一水 2025-04-01 12:43:23 来源:量子位
一手实测来了
借助新版DeepSeek-V3,任何人现在可以一次性创建任何应用或游戏了——
而且是一边开发一边看效果的那种。
在...
ChatGPT会员北美大学生全免费,持续一个月,AI帮你过期末考试

本周五凌晨,OpenAI CEO 山姆・奥特曼宣布了一个令人兴奋的消息。
从现在开始,ChatGPT Plus(原价每月 20 美元)面向美国和加拿大的大学生免费了,时长持续一个月。只要是美国和加拿大授予学位学校的全日制和非全日制学生均有资格享受此优惠。
OpenAI 使用 SheerID 验证系统来验证学生的身份,具体可参看:https://hel...
Multi-Token突破注意力机制瓶颈,Meta发明了一种很新的Transformer

当上下文包含大量 Token 时,如何在忽略干扰因素的同时关注到相关部分,是一个至关重要的问题。然而,大量研究表明,标准注意力在这种情况下可能会出现性能不佳的问题。
标准多头注意力的工作原理是使用点积比较当前查询向量与上下文 Token 对应的键向量的相似性。与查询相似的关键字会获得更高的注意力权重,随后其值向...
创新,责任,领导力|人工智能领军人才发展论坛成功举办 | 量子位

创新,责任,领导力|人工智能领军人才发展论坛成功举办
量子位的朋友们 2025-03-30 16:41:07 来源:量子位
推动人工智能领域的蓬勃发展
3月29日,2025年中关村论坛年会人工智能主题日专场论坛、2025“智领未来”北京人工智能系...
刚刚,DeepSeek公布推理时Scaling新论文,R2要来了?

这会是 DeepSeek R2 的雏形吗?本周五,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。
当前,强化学习(RL)已广泛应用于大语言模型(LLM)的后期训练。最近 RL 对 LLM 推理能力的激励表明,适当的学习方法可以实现有效的推理时间可扩展性。RL 的一个关键挑战是在可验证问题或人工规则之外的各个领域获得 L...
思维链不可靠:Anthropic曝出大模型「诚信」问题,说一套做一套

自去年以来,我们已经习惯了把复杂问题交给大模型。它们通常会陷入「深度思考」,有条不紊地展示思维链过程,并最终输出一份近乎完美的答案。
对于研究人员来说,思考过程的公开可以帮助他们检查模型「在思维链中说过但在输出中没有说」的事情,以便防范欺骗等不良行为。
但这里有一个至关重要的问题:我们真的能相信模...
少数派报告-全球投资导向
我们将专门针对全球的经济政治状况,做最及时的分析与资讯共享。 同时将对国内的市场做适度的点评,提供各类关键分析资讯 我们的口号是:金钱永不眠!

Privacy Policy · Terms of Service · Contact Us
Copyright © 2014-2022 少数派报告 保留所有权利 (Registered:USA CA Fremont 94536)