
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。
该系列包含了三个模型,分别是 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,它们仅通过 API 调用,并已向所有开发者开放。
随着该系列模型在很多关键功能上提供了类似或更强的性能,并且成本和延迟更低,因此 OpenAI 将开始在 API 中弃用 GPT-4.5 预览版。弃用时间为三...
什么样的偏好,才叫好的偏好?——揭秘偏好对齐数据的「三驾马车」

论文有两位共同一作。何秉翔,清华大学博士一年级,研究方向为大语言模型对齐、强化学习。张文斌,哈尔滨工业大学博士一年级,研究方向为自然语言处理。
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基...
全球首个Linux开发本:50TOPS算力,DeepSeek都配好了,可随地大小开发 | 量子位

全球首个Linux开发本:50TOPS算力,DeepSeek都配好了,可随地大小开发
十三 2025-04-11 20:30:33 来源:量子位
书包里直接塞一个AI实训室!
不是你以为的AI PC,全球首个算力本——AIBOOK,它来了!
要说跟AI PC最大的区别,那...
刚刚,DeepSeek公布了推理引擎开源路径,OpenAI也将开始连续一周发布
今天下午,DeepSeek 默默地在自己的 open-infra-index 库中发布了一份题为「开源 DeepSeek 推理引擎的路...
合成数据助力视频生成提速8.5倍,上海AI Lab开源AccVideo
虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进...
AI诺曼底时刻的“技术破壁者”:九章云极DataCanvas公司亮相2025 AI算力产业大会
当前,AI技术正在重构全球经济发展格局与人类生活方式,“存算一体”“云边端协同&rdquo...
倒计时1周!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此 | 量子位

倒计时1周!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此
林樾 2025-04-09 19:26:23 来源:量子位
时间、地点以及最新议程都来啦!4月16日见~
一天时间,带你看尽如何「万物皆可AI」。第三届中国AIGC产业峰会一周在...
10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?

从 ChatGPT 引发认知革命到 GPT-4o 实现多模态跨越,AI 技术的每次跃迁都在印证一个底层逻辑 —— 数据质量决定智能高度。而今,这场 AI 浪潮正在反哺数据库领域,推动其从幕后走向台前,完成智能时代的华丽转身。
在 DB+AI 的舞台上,作为分布式数据库的领军者, OceanBase 正凭其一体化架构重新定义 AI 原生...
更长思维并不等于更强推理性能,强化学习可以很简洁

今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。
他写到:「众所周知,推理模型通常会生成较长的响应,这会增加计算成本。现在,这篇新论文表明,这种行为源于强化学习的训练过程,而并非更高的准确度实际需要更...
过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o

赵俭,北京邮电大学本科三年级,研究方向为大语言模型。刘润泽,清华大学硕士二年级,师从李秀教授,研究方向为大语言模型与强化学习,特别关注大模型推理能力增强与测试时间扩展,在 NeurIPS、ICML、ICLR、AAAI 等顶级学术会议发表多篇论文,个人主页:ryanliu112.github.io。
随着 OpenAI o1 和 DeepSeek R1 的爆火,...
中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理

本文第一作者为邓慧琳,中国科学技术大学硕博连读四年级,研究方向为多模态模型视觉理解、推理增强(R1强化学习)、异常检测。在TAI、TASE、ICCV等期刊和顶会发表论文。
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言...
结合ESM-2,杜克大学开发高效PTM感知蛋白质语言模型,实现新SOTA

编辑 | 萝卜皮
当前的蛋白质语言模型 (LM) 可以准确地编码蛋白质特性,但尚未代表翻译后修饰 (PTM),而翻译后修饰对于蛋白质组多样性至关重要,并影响蛋白质的结构、功能和相互作用。
为了解决这一差距,杜克大学、西湖大学的研究人员开发了 PTM-Mamba,这是一种 PTM 感知蛋白质 LM,它通过新开发的门控机制使用与 ESM-2...
芯片厂商打响智能体AI抢位战!MediaTek发布天玑9400+,携手产业伙伴加速智能体AI体验普及和发展

4 月 11 日,MediaTek举办天玑开发者大会 2025(MDDC 2025),本届大会以 “AI 随芯,应用无界” 为主题,聚焦 AI 技术和产业变革趋势,探讨智能体 AI 体验发展和技术新范式下的共同机遇。
会上,MediaTek 正式启动 “天玑智能体化体验领航计划”,联手全球产业伙伴共同探索智能体 AI 体验发展与普...
“AI孙悟空”对话全球!讯飞星火作为大阪世博会中国馆“唯一大模型展项”正式亮相

4月13日,主题为“构想焕发生机的未来社会”的日本大阪·关西世博会(以下简称“大阪世博会”)开幕。大阪世博会中国馆以“共同构建人与自然生命共同体——绿色发展的未来社会”为主题,携“嫦娥五号”月壤样本、“蛟龙”号体验舱等顶尖科技成果亮相...
AI应用突围,中小企业的新周期已至 | 量子位

AI应用突围,中小企业的新周期已至
白交 2025-04-11 18:01:43 来源:量子位
如今的AI不再是“精英游戏”,而是转变为“全民工具”。
2025年,当算力成本一降再降,开源框架层出不穷,曾经“锁喉”中小企业发展的技术桎梏,正被逐一...
3D领域「源神」又开了两个新项目:三维部件编辑与自动绑定框架

在不久之前机器之心报道文章《3D领域DeepSeek「源神」启动!国产明星创业公司,一口气开源八大项目》中,我们曾介绍到,国内专注于构建通用 3D 大模型的创业公司 VAST 将持续开源一系列 3D 生成项目。
近日,新的开源项目它来了,包括针对任意三维模型生成完整可编辑部件的 HoloPart与通用自动绑定框架 UniRig。
今天,...
不用英伟达GPU!华为盘古Ultra来了:昇腾原生、135B稠密通用大模型

终于,华为盘古大模型系列上新了,而且是昇腾原生的通用千亿级语言大模型。
我们知道,如今各大科技公司纷纷发布百亿、千亿级模型。但这些大部分模型训练主要依赖英伟达的 GPU。
而现在的情形下,国内研究团队很难获得足够的计算资源,这也制约了国内大模型技术的快速发展。
我们看到华为盘古发布的这篇新研究,证明了...
强化学习带来的改进只是「噪音」?最新研究预警:冷静看待推理模型的进展

「推理」已成为语言模型的下一个主要前沿领域,近期学术界和工业界都取得了突飞猛进的进展。
在探索的过程中,一个核心的议题是:对于模型推理性能的提升来说,什么有效?什么无效?
DeepSeek - R1 论文曾提到:「我们发现将强化学习应用于这些蒸馏模型可以获得显著的进一步提升」。3 月 20 日,论文《Reinforcement Lea...
3710亿数学tokens,全面开放!史上最大高质量开源数学预训练数据集MegaMath发布

在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
近日,LLM360 推出了 MegaMath:全球目前最大的开源数学推理预训练数据集,共计 3710 亿(371B)tokens,覆盖网页、代码和高质量合成数据三大领域。
报告标题:MegaMath: Pushing the Limits of Open Math Corpora
技术报告:htt...
扩散模型奖励微调新突破:Nabla-GFlowNet让多样性与效率兼得

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。
在视觉生成领域,...
GPT-4o图像生成架构被"破解"了?自回归主干+扩散解码器 | 量子位

GPT-4o图像生成架构被“破解”了?自回归主干+扩散解码器
一水 2025-04-09 17:44:32 来源:量子位
三大维度全面评估GPT-4o图像能力
GPT-4o图像生成架构被“破解”了!
最近一阵,“万物皆可吉卜力”让GPT-4o的图像生成功能一炮而红...
阿里云造"Agent工厂",百炼MCP服务上线,无需代码5分钟建Agent | 量子位
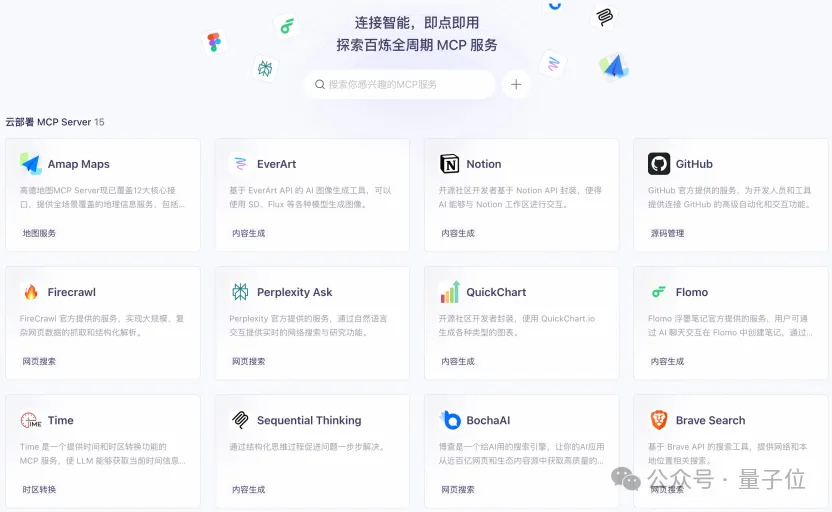
阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent
西风 2025-04-09 17:10:32 来源:量子位
未来要做Agent Store
AI大模型在咖啡店怎么落地?
不是辅助设计宣传海报or制定营销策略,新姿势是:
帮忙质检,不仅包括...
"AI眼镜的终极功能,是AI+社交" | 对话影目科技创始人 | 量子位
“AI眼镜的终极功能,是AI+社交” | 对话影目科技创始人
克雷西 2025-04-07 21:48:45 来源:量子位
“AI更多是一种底层能力,而不是一种聚焦的功能”
AI眼镜,究竟为什么这么热?
2023年10月,现象级产品Ray-Ban Meta智能眼镜发布...
Science子刊 | 基于公平贝叶斯扰动,首个面向医学图像生成公平性的方法FairDiffusion来了

编辑 | ScienceAI
随着人工智能在医学影像领域的广泛应用,文本到图像扩散模型(如 Stable Diffusion)正逐步渗透到医学数据合成、医学教育和数据共享中。然而,尽管生成质量整体较高,模型在不同人口统计属性(性别、种族、族裔)上却存在明显差异。例如,实验表明,Stable Diffusion 在生成女性、白人及非西班牙裔样本...
魔改AlphaZero后,《我的世界》AI老玩家问世,干活不用下指令

大模型驱动的 AI 助手又升级了。本周五,科技圈正在围观一个陪你一起玩《我的世界》的 AI。
它话不多说,就是埋头干活。一起盖房子的时候,你不需要给 AI 一张蓝图,或是不断告诉它该怎么做,你只需要盖自己的,它就能一边观察一遍配合,并观察你的意图随时改变计划。
现在,AI 可以不断主动学习、纠正错误,展现出了...
算法不重要,AI的下一个范式突破,「解锁」新数据源才是关键

众所周知,人工智能在过去十五年里取得了令人难以置信的进步,尤其是在最近五年。
回顾一下人工智能的「四大发明」吧:深度神经网络→Transformer 语言模型→RLHF→推理,基本概括了 AI 领域发生的一切。
我们有了深度神经网络(主要是图像识别系统),然后是文本分类器,然后是聊天机器人,现在我们又有了...
苹果发现原生多模态模型Scaling Laws:早融合优于后融合,MoE优于密集模型

让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。
目前我们见到的很多多模态大模型应用是「组合式」的:其中集成了数个单独预训练的组件,例如将视觉编码器连接到 LLM 上并继续进行多模态训练;而在谷歌 Gemin 2.0 推出之后,原生多模态模型(NMM)被认为是正确的方向。
但从零开始...
面对杂乱场景,灵巧手也能从容应对!NUS邵林团队发布DexSinGrasp基于强化学习实现物体分离与抓取统一策略

本文的作者均来自新加坡国立大学 LinS Lab。本文的共同第一作者为新加坡国立大学实习生许立昕和博士生刘子轩,主要研究方向为机器人学习和灵巧操纵,其余作者分别为硕士生桂哲玮、实习生郭京翔、江泽宇以及博士生徐志轩、高崇凯。本文的通讯作者为新加坡国立大学助理教授邵林。
在物流仓库、生产线或家庭场景中,机器人...
LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯 | 量子位

LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯
衡宇 2025-04-06 10:41:26 来源:量子位
百万上下文+原生多模态
AI不过周末,硅谷也是如此。
大周日的,Llama家族上新,...
量子位

林樾 2025-04-08 15:51:06 来源:量子位
☄️ 速戳报名!4月16日,来 #中国AIGC产业峰会 看AI如何用起来? 👉 报名链接:https://hdxu.cn/Arf5
4月16日,北京金茂万丽酒店,第三届中国AIGC产业峰会就要来啦!观众报名通道已开启...
少数派报告-全球投资导向
我们将专门针对全球的经济政治状况,做最及时的分析与资讯共享。 同时将对国内的市场做适度的点评,提供各类关键分析资讯 我们的口号是:金钱永不眠!

Privacy Policy · Terms of Service · Contact Us
Copyright © 2014-2022 少数派报告 保留所有权利 (Registered:USA CA Fremont 94536)