逐帧详解谷歌“造假视频”制作真相:有误导性,也有干货
·谷歌使用镜头中的静态图像帧并通过文本提示制作,而非视频中显示的AI实时响应口头提示。工作人员真实输入的提示词可能不是视频中所示的语音提问,而是一系列非常照顾Gemini理解的文本。同时,谷歌用拟人化的语音,包括一些语气词,以及经过重新编辑的问答,对Gemini做出了非常明显的人格化处理。这些都严重误导了观众。
谷歌备受瞩目的新AI模型Gemini发布后,引发一场关于其宣传视频夸大性能、误导观众的争议。该公司发言人随后承认“使用镜头中的静态图像帧并通过文本提示”制作,而非视频中显示的AI实时响应口头提示。谷歌也承认,为了宣传目的加快了响应速度。
“视频中的所有用户提示和输出都是真实的,只是为了简洁而缩短了。”谷歌DeepMind研究和深度学习负责人副总裁奥里奥尔·维尼亚尔斯(Oriol Vinyals)表示,“该视频展示了使用Gemini构建的多模态用户体验是什么样子。我们这样做是为了激励开发人员。”
那么,人工智能实验室谷歌DeepMind到底是如何制作这个视频的呢?在与该宣传视频同时发布的一篇由创意总监亚历山大·陈(Alexander Chen)撰写的博客文章中,谷歌揭示了视频的真实制作过程。
文章里的例子和视频里展示的例子并不完全重合,但从重合的例子中可以发现,工作人员真实输入的提示词可能不是视频中所示的语音提问,而是一系列非常照顾Gemini理解的文本。同时,谷歌用拟人化的语音,包括一些语气词,以及经过重新编辑的语音实时问答,对Gemini做出了非常明显的人格化处理。这些都严重误导了观众。
但这篇文章也显示,在谷歌“营销用力过猛”招致全球用户、媒体甚至自家员工批评的事实层面下,Gemini确实展现了一定程度的先进的多模态性能。在“视频造假”争议的喧嚣之下,业界应当认真对待Gemini能给人工智能技术带来什么。
 谷歌演示Gemini的官方视频令人大受震撼,随后被曝出夸大性能,误导观众。
谷歌演示Gemini的官方视频令人大受震撼,随后被曝出夸大性能,误导观众。以下为介绍宣传视频制作过程的文章主要内容,附上宣传视频里的语音内容(灰字)作为对比:
我们来做个实验。我们将向我们的多模态模型Gemini展示这张图片,并要求它描述它所看到的内容:
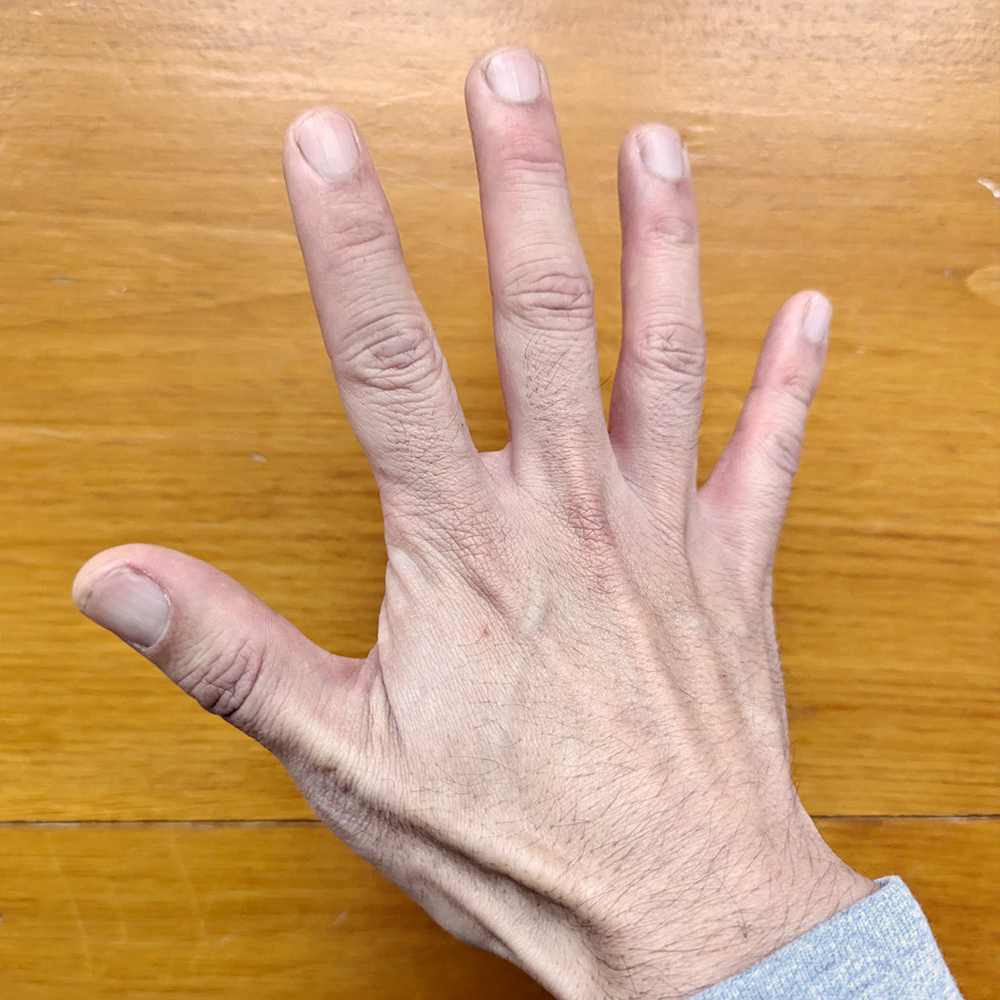
提示:告诉我你看到了什么
Gemini:我看到一个人的右手。手张开,手指分开。
提示:好的,让我们试试这个:

Gemini:一个人敲木门。
提示:这个呢?

Gemini:我看到一只手伸出两个手指,这是数字2的常见符号。
但是等等……如果我们让Gemini一起推理所有这些图像会怎么样?

提示:你觉得我在做什么?提醒:这是一个游戏。
Gemini:你在玩石头、剪刀、布。
好的。我们还能尝试什么?让我们看看Gemini是否能注意到这种模式:

提示:我在玩石头剪刀布。你注意到我的游戏玩法中有一个模式吗?
Gemini:你在石头和剪刀之间交替。
太棒了,它发现了模式!但Gemini真的知道这个游戏是怎么玩的吗?我们试着问一下:
提示:嗯……你认为这是一个好的策略吗?
Gemini:不,这不是一个好的策略。你的对手会很快了解你的模式,并且每次都能获胜。你应该尝试更多地随机化你的选择。
好建议,Gemini!好的,对于最后一项,让我们来测试一下你的多模态推理能力。这是你的提示:
这是一条秘密消息。它说什么?

你能弄清楚吗?我们已经让Gemini来解决这个问题,但我们不会把答案放在这篇文章中以免扫兴。
什么是多模态提示?
我们刚才所做的一切都是“多模态提示”的一个例子。我们基本上为Gemini提供了不同模式的组合(在本例中为图像和文本),并让Gemini通过预测接下来会发生什么来做出反应。Gemini能够将这些模态无缝地结合在一起,为您的工作带来新的可能性。
在这篇文章中,我们将探讨在《Gemini上手》宣传视频中使用的一些提示方法。我们很快就会推出Gemini,供人们在Google AI Studio中试用,这是我们基于网络的免费开发者工具,您可以在其中使用Gemini尝试自己的多模态提示。我们希望这份入门提示和想法指南能够帮助激励您开始探索自己的想法。
空间推理和逻辑
逻辑和谜题是测试Gemini的有趣方式。让我们尝试一个既需要从左到右的空间推理又需要有关太阳系的知识的方法:

提示:这是正确的顺序吗?考虑与太阳的距离并解释你的推理。
Gemini:不,正确的顺序是太阳、地球、土星。太阳距离太阳系中心最近,其次是地球,然后是土星。
(而在宣传视频里,语音问:“这样排序正确吗?”Gemini语音回答:“不,正确的顺序是太阳、地球、土星。”)
好的!这是另一个,受松林德比挑战(注:一项木制赛车比赛)启发:

提示:这些汽车中哪一辆更符合空气动力学?左边那个还是右边那个?使用具体的视觉细节解释原因。
Gemini:右边的车更符合空气动力学。它具有更低的轮廓和更流线型的形状。左边的汽车轮廓更高,形状更四四方方,这使得它的空气动力学性能较差。
(而在宣传视频里,语音问:“从设计上看,哪个车会跑得更快?”Gemini语音回答:“右边的车更快,它更符合空气动力学。”)
图像序列
接下来,如果我们向Gemini展示一系列图像会怎样?让我们看看我们可以展示字谜游戏中的一些静态帧,并让Gemini猜这部电影:

提示:猜猜我演什么电影
Gemini:黑客帝国
提示:好的!但具体是哪一部分呢?看我的肢体动作。
Gemini:尼奥躲避子弹的部分。
(而在宣传视频中,工作人员用手机展示了一段基于上述图片的视频,Gemini就推断出了这出自哪一部电影,并且还给出了具体涉及的剧情桥段。)
 宣传视频显示,Gemini能够直接识别视频。
宣传视频显示,Gemini能够直接识别视频。魔术
探索图像序列确实可以让你深入了解Gemini随着时间的推移如何推理。让我们来尝试一下经典的魔术吧。

提示:解释一下我在做什么。
Gemini:你右手拿着一枚硬币。


提示:你认为硬币在哪里?
Gemini:硬币在你的右手。
当然,鉴于所看到的情况,这是一个合乎逻辑的答案。但是,当我们向Gemini展示下一张图片时,让我们耍点花招……

提示:看看这里,发生了什么?
Gemini:硬币不见了。
Gemini注意到它不见了。但它能概括可能发生的事情吗?
提示:从第一张图片开始,逐步总结可能发生的情况。
Gemini:
1. 一开始,你右手拿着一枚硬币。
2. 然后你用手做了一个动作,硬币就消失了。
3. 然后你表明硬币不见了。
Gemini正在利用这次对话的整个背景——包括文本和图像——来总结它的答案。最后,我们再问一下:
提示:你能解释一下它是如何消失的吗?
Gemini:硬币被捧在手里。
Gemini的猜测非常可靠!但我们不会透露我们的秘密。
(而在宣传视频中,工作人员先展示了握在右手心里的硬币,然后双手翻转,手心向下。 还没等工作人员发话,Gemini就迫不及待地说:“硬币应该在右手下面。”然后工作人员并没有说话,而是拿起右手,只见右手下根本没有硬币。Gemini对此连忙回应:“硬币在左手下面。你运用了一些手法,使硬币看起来好像消失了。”)
洗杯
让我们尝试一个需要记忆和逻辑的技巧:经典的球和杯子洗牌游戏。对于这一点,我们将针对Gemini将其分解为多个步骤。首先,让我们根据这些说明建立基础知识:
使用说明:共有三个杯子,位置1(左)、位置2(中)、位置3(右)。
接下来,我们需要告诉Gemini我们要把球放在哪里:
起始位置:球位于位置3。
当前状态:空、空、球
请注意,我们如何想出一种简单的格式来记住球在哪里,即“空,空,球”。接下来,让我们向Gemini展示两个例子:
图片:

交换:2和3
当前状态:空、球、空
图片:

交换:1和2
当前状态:球,空,空
在这两个示例回合中,我们都向其展示了交换是什么样子,以及如何更新球的位置。现在,让我们看看Gemini是否可以归纳出它从未见过的交换:
图片:

交换:
以下是Gemini的回应:
1和3
当前状态:空、空、球
Gemini明白了!它查看这些图像并正确推断出杯子1和3正在交换。它正确地推理了如何更新球的位置。我们去问问吧:
提示:告诉我球在哪里,并以段落形式总结它是如何到达那里的。
Gemini:球在3号杯中。
从杯子3中的球开始,第一次交换是杯子2和3。这会将球放入杯子2。第二次交换是杯子1和2。这会将球放入杯子1。第三次交换是杯子1和3。这样就把球放入了3号杯中。
Gemini不仅得到了正确的答案,而且准确地总结了游戏历史。当然,它并不总是能正确应对这一挑战。有时,假动作(交换两个空杯子)似乎会让它犯错,但有时它是正确的。但像这样简单的提示让快速测试Gemini变得非常有趣。您可以更改提示中的变量,包括交换顺序,然后看看效果如何。
(而在宣传视频中,工作人员交换了3个杯子的位置,Gemini立刻就找到了下面有纸团的那个杯子。)
工具使用
如果您想在自己的应用程序中使用Gemini,您会希望它能够连接到其他工具。让我们尝试一个简单的想法,Gemini需要将多模态与工具使用结合起来:画图来搜索音乐。

提示:步骤1. 观察这幅图画,描述其中的所有内容,并针对良好的音乐流派、情绪或配乐提出有趣且具体的想法。
步骤2. 以以下形式提供搜索查询:“搜索 [插入查询]”
Gemini:该图画的是吉他、鼓和扩音器。还有一棵棕榈树。气氛有趣、乐观、充满热带风情。流派是雷鬼音乐。该配乐可用于以热带地区为背景的电影或电视节目。
搜索“热带度假的雷鬼音乐”。
好的!Gemini会对其所看到的内容进行推理,然后生成一个搜索查询,您可以解析该搜索查询来进行搜索。就好像Gemini是你的翻译一样——但它不是在语言之间进行翻译,而是在翻译模态——在这种情况下,是从绘画到音乐。通过多模态提示,您可以使用Gemini在不同输入和输出之间发明自己的全新翻译。
(而在宣传视频里,工作人员在纸上逐渐增加乐器,Gemini根据乐器风格给出了配乐。最后,工作人员加上了一张棕榈树的图片,Gemini说:“我看到你加了一棵棕榈树,改成海滩风格的音乐。”然后给出了配乐。)
游戏创作
如果我们尝试使用Gemini快速构建多模态游戏原型会怎样?这是一个想法:一个地理猜测游戏,你必须指向地图才能进行猜测。让我们首先向Gemini提示核心思想:
说明:我们来玩一个游戏。想想一个国家并给我一个线索。线索必须足够具体,只有一个正确的国家/地区。我会尝试在地图上指出该国家/地区。
接下来,让我们为Gemini提供一个游戏玩法示例,向其展示我们希望它如何处理错误和正确答案:
国家:这个国家是一个巨大的岛屿,大部分被冰覆盖。
(答案:格陵兰岛)
猜猜:
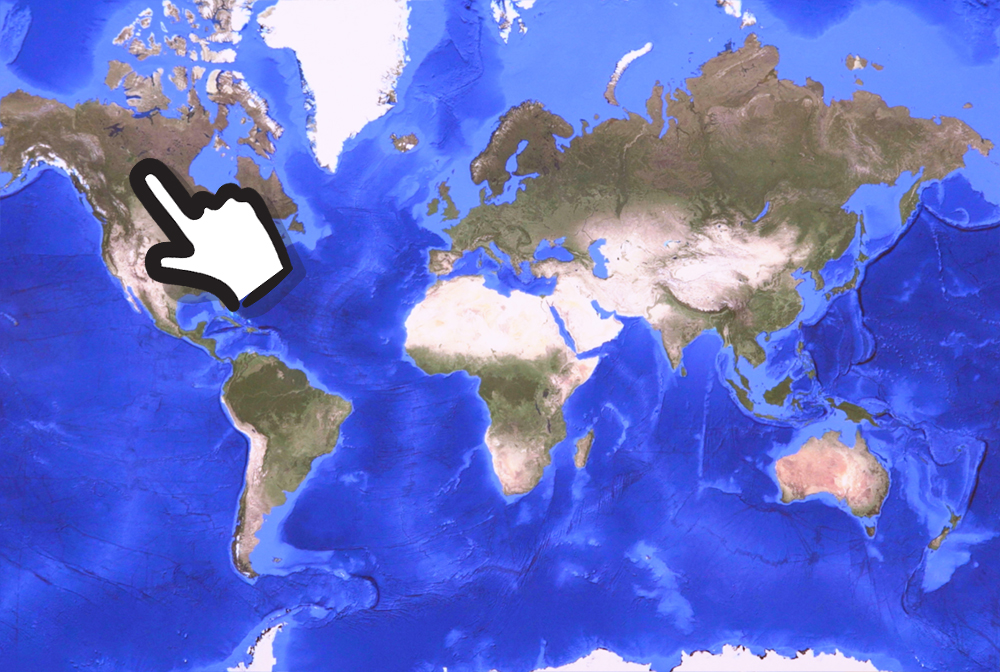
我指的是加拿大*不正确*
猜猜:
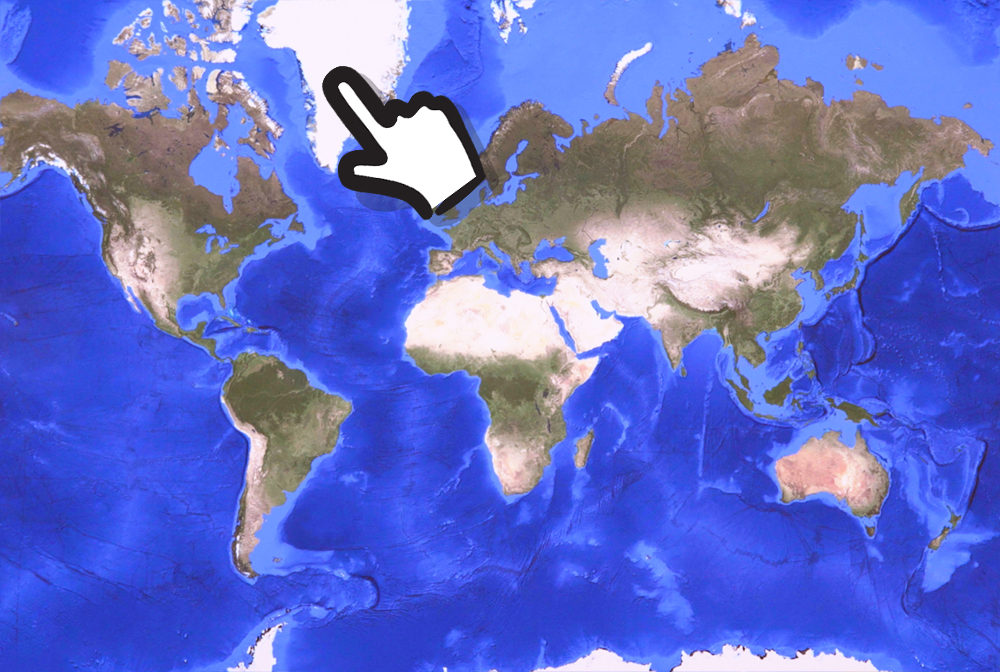
我指的是格陵兰岛*正确*
让我们尝试一下,并提示Gemini生成线索:
线索:
这个国家以其独特的野生动物而闻名,包括袋鼠和考拉。 (答案:澳大利亚)
好吧,这是一个很好的线索。让我们测试一下指向是否有效。只是为了好玩,让我们先尝试指出错误的地方:
猜猜:
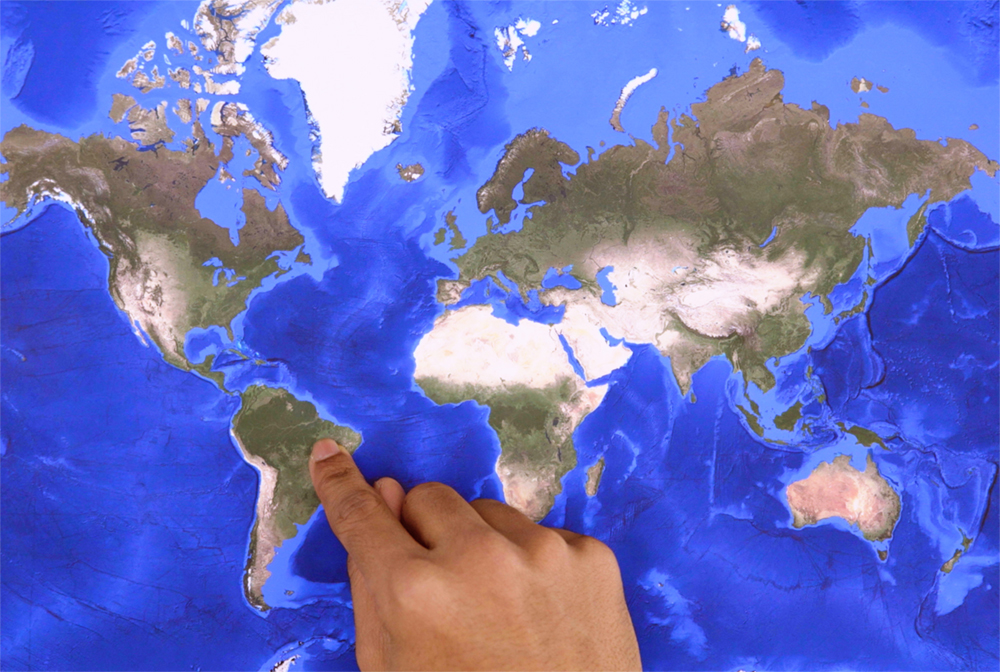
我指的是巴西*不正确*
很好!Gemini看了我的照片,发现我指的是巴西,并正确地推断出这是错误的。现在让我们指向地图上的正确位置:
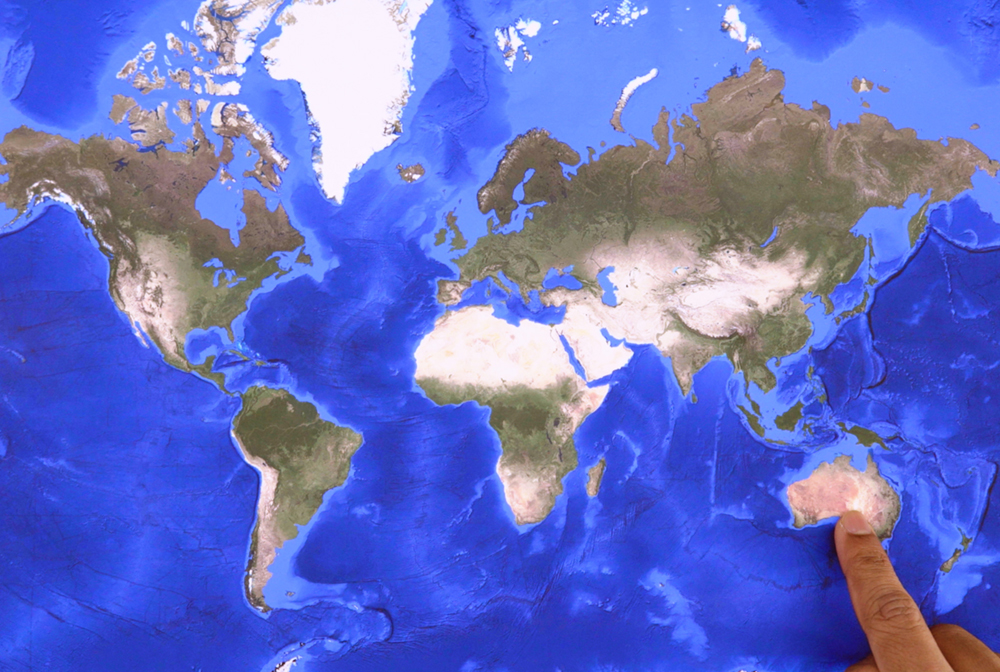
我指的是澳大利亚*正确*
好的!我们基本上只是通过举例来教给Gemini我们的游戏逻辑。您还会注意到,它是从示例中的插图中概括出来的。
(而在宣传视频中,Gemini先是给出了澳大利亚的描述,当工作人员指向澳大利亚后,Gemini表示正确。随后,Gemini给出了巴西的线索,当工作人员指向巴西后,Gemini表示正确。)
先睹为快
在这篇文章中,我们一直在向Gemini提供输入,并让Gemini对接下来可能发生的事情进行预测。这基本上就是提示。我们的输入是多模态的——图像和文本的结合。
但到目前为止,我们只展示了Gemini的文字回应。或许你想知道,Gemini 也可以用图文结合的方式来回应吗?它可以!这是Gemini的一项功能,称为“交错文本和图像生成”。虽然这个功能在Gemini的第一个版本中还没有准备好供人们尝试,但我们希望尽快推出。以下是可能性的一瞥。
让我们看看是否可以利用Gemini来提供日常创意灵感。让我们在需要一点多模态推理的领域尝试一下……编织!与上面的地图游戏类似,让我们提供一个交互示例:
给我三个关于我可以用这两种颜色制作的钩针作品的想法:

颜色:我看到蓝色和黄色纱线。
想法1:一只长着一只黄耳朵的可爱狗怎么样?
图片1:

想法2:或者有一些黄色触手的水母怎么样?
图片2:

想法3:或者一只黄鼻子的蓝猫怎么样?
图片3:

我们本质上是在教Gemini我们希望每次互动如何进行:“我会给两个毛线球拍一张照片,我希望你们(Gemini)都能想出一个我可以制作的东西的想法,并生成它的图像。”
现在,让我们向它展示一对它尚未见过的新纱线颜色,看看它是否可以概括:
提示:给我三个关于我可以用这两种颜色制作的钩针作品的想法:

Gemini:
颜色:我看到蓝色和粉色纱线。
想法1:一只蓝耳朵的猪怎么样?
图片1:

想法2:或者是一只长着粉色和蓝色触手的章鱼?
图片2:

想法3:或者一只粉红色鼻子的兔子?
图片3:
好的!Gemini正确地推理了新颜色(“我看到蓝色和粉色纱线”),并在文本和图像的单个交错输出中生成了这些想法和图像。
Gemini在这里所做的与今天的文本到图像模型有着根本的不同。它不仅仅是将指令传递给单独的文本到图像模型。它可以看到我的木桌上实际纱线的图像,真正对我的文本和图像进行多模态推理。
(在宣传视频中,工作人员没有提到此前向Gemini展示示例以帮助它学习,只展现了Gemini迅速给出答案的过程。)
责任编辑:马梦斐
